
 Github
Github Huggingface
Huggingface 论文
论文

会说话的头像: Leonardo.ai API生成的单个肖像图片 🙎♂️ + ElevenLabs TTS API生成的音频 🎤 = 会说话的头像视频 🎞.
Leonardo.ai
前往 Leonardo.Ai 输入你的提示词和反向提示词来生成艺术图像
这里有一些资源:Leonardo.ai YouTube视频 Leonardo.ai YouTube视频教程
或者你可以使用API Leonardo.Ai API指南
| Leonardo.ai 图像生成 | Leonardo.ai 图像生成 | Leonardo.ai 图像生成 |
|
|
|
|
ElevenLabs
前往 Eleven Labs 输入你的文本,生成不同音高和说话者的优美音频。ElevenLabs也支持多语言
这里有一些资源:ElevenLabs YouTube视频
或者你可以使用API ElevenLabs API指南
🔥 亮点
-🔥 左右滚动查看所有视频
| 视频1 + 增强(GFPGAN ) | 视频2 | 视频3 |
|---|---|---|
| 视频4 | 视频5 | 视频6 |
|---|---|---|
- 🔥 新增多种模式,如
静态模式、参考模式、调整大小模式,以实现更好的自定义应用。
我们的方法图
Linux:
-
安装 anaconda、python 和 git。
-
创建环境并安装依赖。
git clone https://github.com/saba99/Talking_Face_Avatar.git
cd SadTalker
conda create -n sadtalker python=3.8
conda activate sadtalker
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
conda install ffmpeg
pip install -r requirements.txt
### tts 是 gradio 演示的可选依赖。
### pip install TTS
UI + API:
查看 index.html
📥 2. 下载训练好的模型
您可以运行以下脚本将所有模型放置在正确的位置。
bash scripts/download_models.sh
模型详情
最终文件夹结构如下所示:
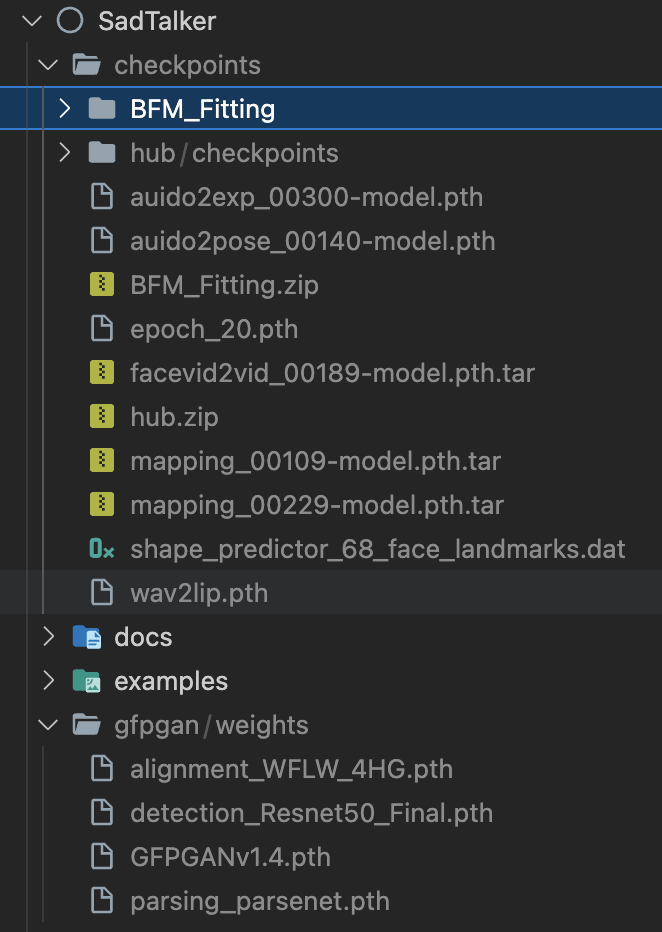
模型说明:
| 模型 | 描述 |
|---|---|
| checkpoints/auido2exp_00300-model.pth | Sadtalker中预训练的ExpNet。 |
| checkpoints/auido2pose_00140-model.pth | Sadtalker中预训练的PoseVAE。 |
| checkpoints/mapping_00229-model.pth.tar | Sadtalker中预训练的MappingNet。 |
| checkpoints/mapping_00109-model.pth.tar | Sadtalker中预训练的MappingNet。 |
| checkpoints/facevid2vid_00189-model.pth.tar | 来自face-vid2vid复现的预训练face-vid2vid模型。 |
| checkpoints/epoch_20.pth | Deep3DFaceReconstruction中预训练的3DMM提取器。 |
| checkpoints/wav2lip.pth | Wav2lip中高精度的唇形同步模型。 |
| checkpoints/shape_predictor_68_face_landmarks.dat | dilb中使用的人脸关键点模型。 |
| checkpoints/BFM | 3DMM库文件。 |
| checkpoints/hub | face alignment中使用的人脸检测模型。 |
| gfpgan/weights | facexlib和gfpgan中使用的人脸检测和增强模型。 |
🔮 3. 快速开始(最佳实践)
WebUI演示:
## 您需要事先通过 `pip install tts` 手动安装TTS(https://github.com/coqui-ai/TTS)。
python app.py
手动使用:
使用默认配置为肖像图像添加动画:
python inference.py --driven_audio <audio.wav> \
--source_image <video.mp4 or picture.png> \
--enhancer gfpgan
结果将保存在 results/$SOME_TIMESTAMP/*.mp4 中。
全身/图像生成:
使用 --still 生成自然的全身视频。您可以添加 enhancer 来提高生成视频的质量。
python inference.py --driven_audio <audio.wav> \
--source_image <video.mp4 or picture.png> \
--result_dir <存储结果的文件> \
--still \
--preprocess full \
--enhancer gfpgan











