
 访问官网
访问官网 Github
Github 论文
论文
Ranni:驯服文本到图像扩散模型以准确遵循提示
冯宇彤
·
龚彪
·
陈迪
·
沈昱君
·
刘宇
·
周靖人
阿里巴巴集团 | 蚂蚁集团
这个代码库是CVPR 2024论文"Ranni:驯服文本到图像扩散模型以准确遵循指令"的官方实现。它包含两个主要组成部分:1)基于大语言模型的规划模型,将文本指令映射到图像中的视觉元素;2)基于扩散的绘画模型,根据第一阶段的视觉元素绘制图像。由于大语言模型强大的能力,Ranni实现了更好的语义理解。目前,我们发布了模型权重,包括一个LoRA微调的LLaMa-2-7B和一个完全微调的SDv2.1模型。

|
新闻
- 2024年4月8日:Ranni被CVPR 2024接收为口头报告论文 🎉
- 2024年4月3日:我们发布了Ranni的v1代码。
待办事项
- 发布模型、检查点和演示代码。
- 支持更多条件。
- 基于对话的编辑。
- 具有ID一致性的连续生成。
安装
使用conda安装:
conda env create -f environment.yaml
conda activate ranni
下载检查点
下载Ranni检查点并将所有文件放在model目录中,应该如下所示:
models/
llama2_7b_lora_bbox.pth
llama2_7b_lora_element.pth
ranni_sdv21_v1.pth
Gradio演示
我们通过运行Gradio演示来展示交互式图像生成:
python demo_gradio.py
它应该看起来像下面显示的UI:
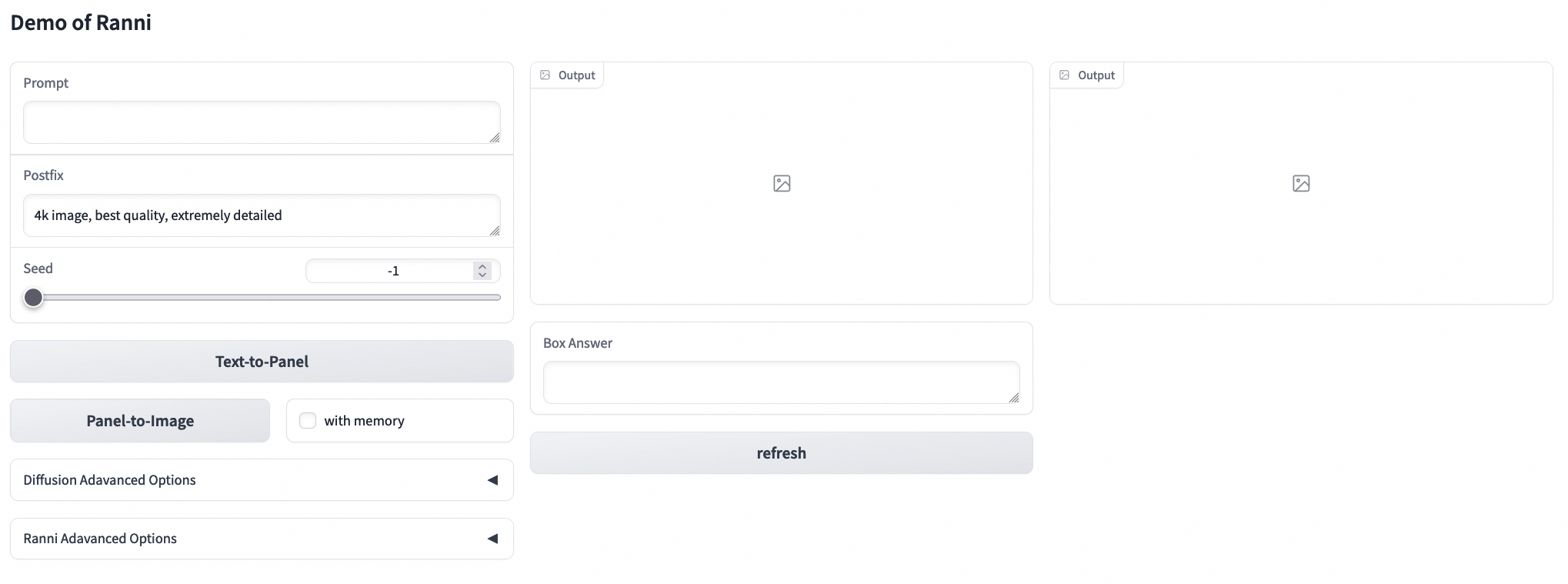
|
图像生成教程
只需输入图像提示。点击text-to-panel按钮生成语义面板,然后点击panel-to-image按钮生成相应的图像:
提示:一只黑狗和一只白猫

|
持续编辑教程
生成图像后,您可以修改框内答案以调整面板(如有需要,修改提示)。点击refresh按钮刷新条件。在panel-to-image后启用with memory复选框,然后生成修改后的图像:
提示:一只黑狗和一只白猫 修改:黑狗 -> 白狗
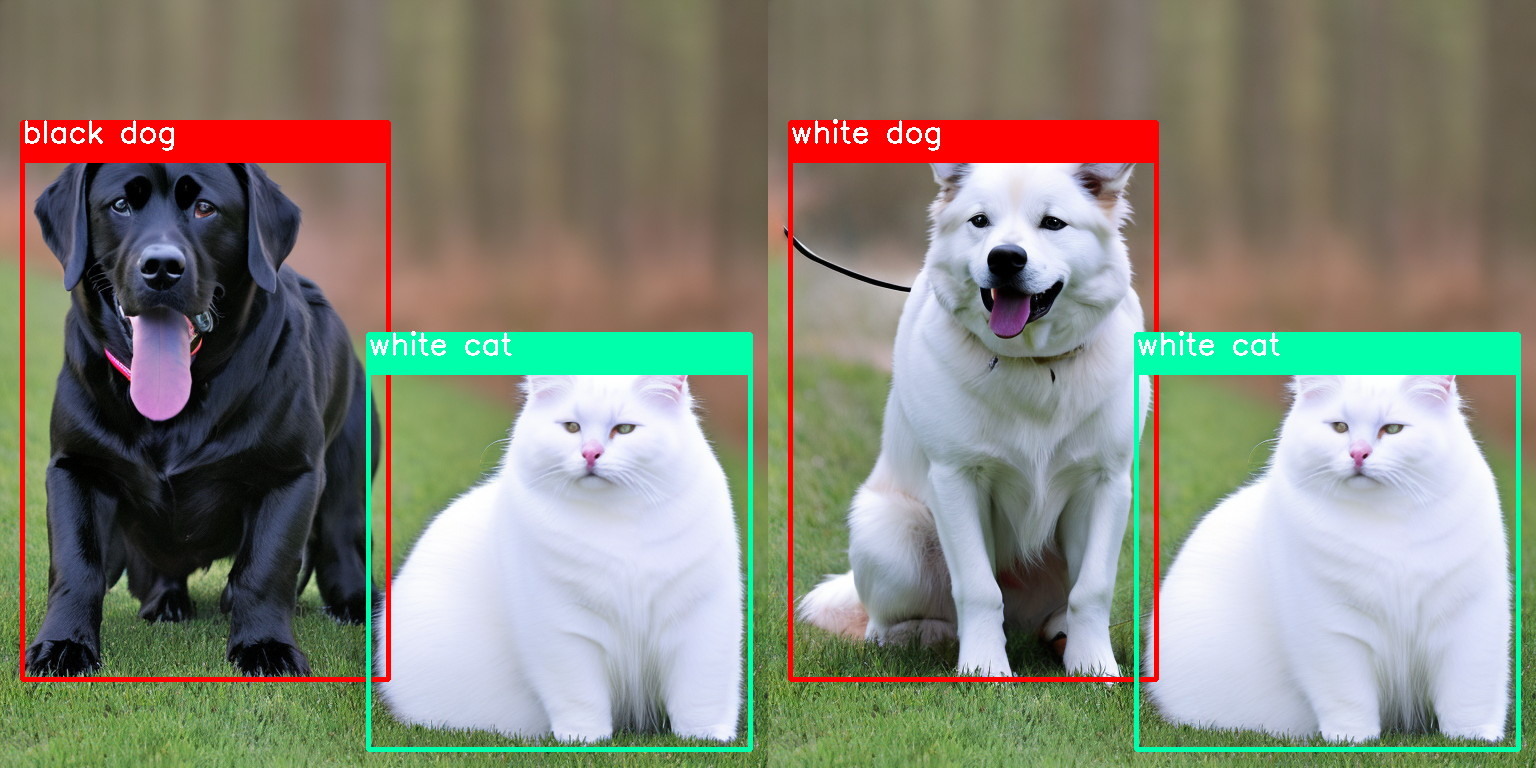
|
通过操作框和提示,您可以实现以下类型的多种编辑操作:
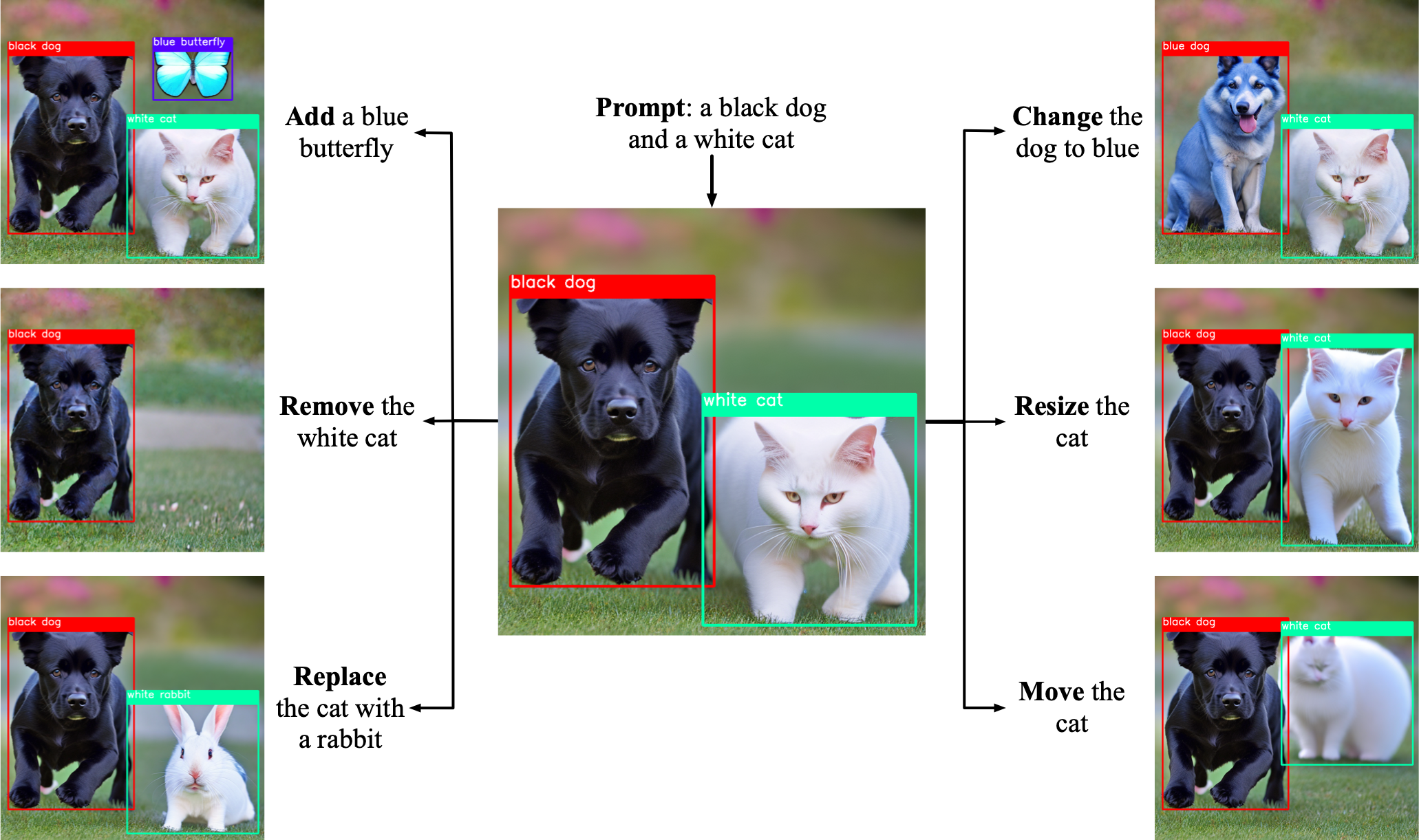
|
致谢
本代码库基于以下代码库:
引用
如果您发现这个代码库对您的研究有用,请使用以下条目。
@article{feng2023ranni,
title={Ranni: Taming Text-to-Image Diffusion for Accurate Instruction Following},
author={Feng, Yutong and Gong, Biao and Chen, Di and Shen, Yujun and Liu, Yu and Zhou, Jingren},
journal={arXiv preprint arXiv:2311.17002},
year={2023}
}











