
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文扩散反馈帮助CLIP更好地"看见"
王文轩1,2,3*, 孙权3*, 张帆3, 唐烨鹏4, 刘静1,2, 王鑫龙3
1中国科学院自动化研究所, 2中国科学院大学, 3北京智源人工智能研究院, 4北京交通大学
* 同等贡献
⏰ 时间表
[2024-08-07] 我们发布了CLIP模型权重!💥
[2024-08-05] 我们发布了训练和评估代码!💥
[2024-07-30] 我们的论文在arXiv上发布了!💥
💡 动机
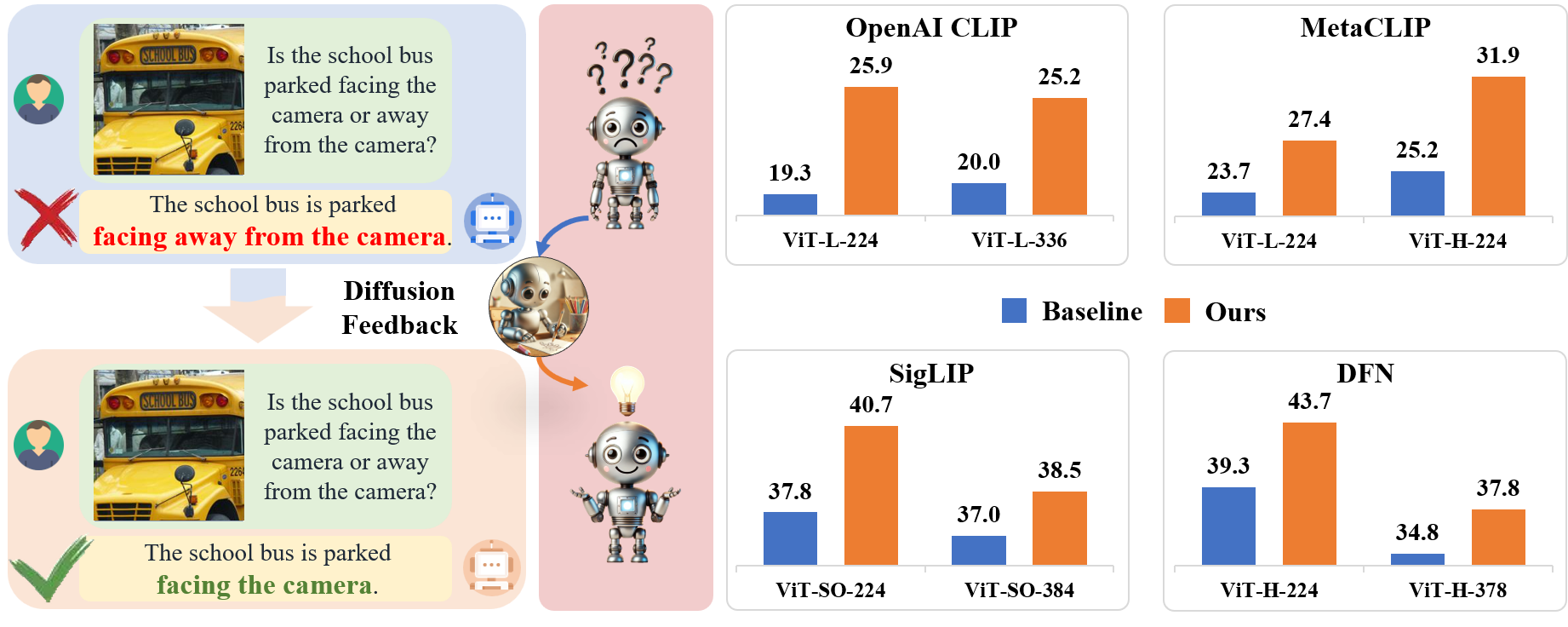
在这项工作中,我们提出了一种简单的CLIP模型后训练方法,通过自监督扩散过程在很大程度上克服了其视觉缺陷。我们引入了DIVA,它将扩散模型用作CLIP的视觉助手。具体而言,DIVA利用文本到图像扩散模型的生成反馈来优化CLIP表示,仅使用图像(无对应文本)。我们证明,DIVA在很大程度上评估细粒度视觉能力的具有挑战性的MMVP-VLM基准测试上改进了CLIP的性能(例如,提高3-7%),并增强了MLLMs和视觉模型在多模态理解和分割任务上的性能。在29个图像分类和检索基准测试上的广泛评估证实,DIVA保留了CLIP强大的零样本能力。
🤖 架构
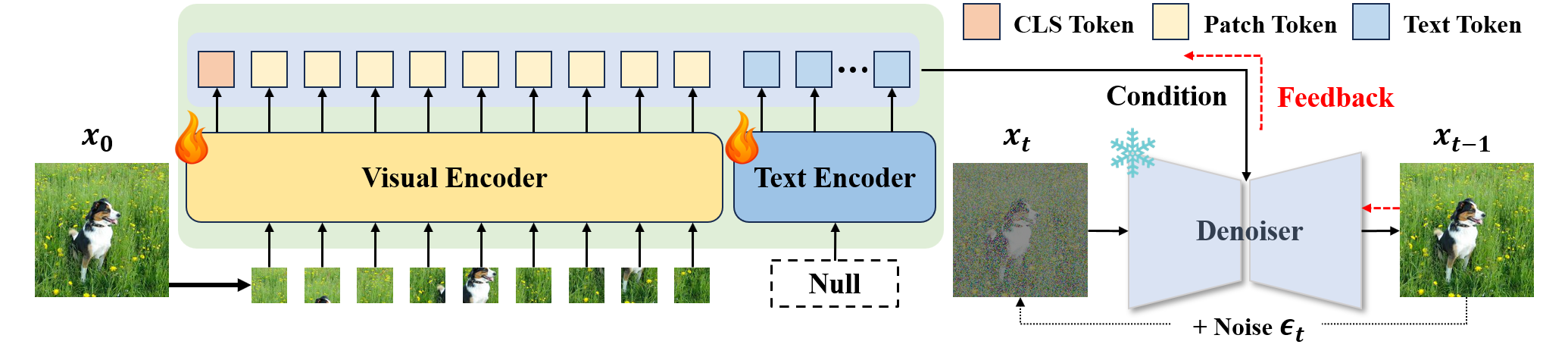
给定一张图像,CLIP模型将视觉特征编码为条件的主要部分,然后生成式扩散模型以噪声图像和条件作为输入预测添加的噪声。我们通过生成反馈,使用扩散损失最大化图像似然来优化CLIP的表示。
🔨 安装
克隆此仓库并安装所需的包:
git clone https://github.com/baaivision/DIVA.git
cd DIVA
mkdir -p outputs logs datasets pretrained_weights/CLIP pretrained_weights/SD
conda create -n diva python=3.9
conda activate diva
pip install -r requirements.txt
核心包:
- Pytorch 版本 2.0.0
- open-clip-torch 版本 2.24.0
- timm 版本 0.9.8
🍹 DIVA生成式微调的准备工作
数据获取
关于数据准备,请参考image2dataset和MMVP获取本工作中使用的训练和评估数据。收集相应数据集后,直接将它们放入dataset/文件夹路径。
预训练权重下载
对于预训练权重准备,请参考OpenAI ViT-L-14/224&336、MetaCLIP ViT-L/H-14、SigLIP ViT-SO-14/224、SigLIP ViT-SO-14/384、DFN ViT-H-14/224、DFN ViT-H-14/378和SD-2-1-base获取判别式CLIP模型和提供生成反馈的扩散模型的权重。下载所有必要的权重后,将它们分别移动到相应的文件夹路径pretrained_weights/CLIP/和pretrained_weights/SD/。
代码修改
为了准备我们DIVA的条件设计,需要修改已安装的CLIP和OpenCLIP包中的一些源代码。
对于OpenAI CLIP,使用我们提供的condition/OpenAICLIP_for_clip_model.py中的内容替换Your Conda Installation Path/anaconda3/envs/diva/lib/python3.9/site-packages/clip/model.py中的内容。
对于MetaCLIP和DFN,使用我们提供的condition/MetaCLIP_for_openclip_transformer.py和condition/DFN_for_openclip_transformer.py中的内容分别替换Your Conda Installation Path/anaconda3/envs/diva/lib/python3.9/site-packages/open_clip/transformer.py中的内容。
对于SigLIP,使用我们提供的condition/SigLIP_for_timm_models_visiontransformer.py中的内容替换Your Conda Installation Path/anaconda3/envs/diva/lib/python3.9/site-packages/timm/models/vision_transformer.py中的内容。
🍻 训练与评估快速入门
完成以上所有准备步骤后,你可以使用以下命令简单地开始训练我们的DIVA:
# 对于OpenAICLIP
bash DIVA_for_OpenAICLIP.sh
# 对于MetaCLIP
bash DIVA_for_MetaCLIP.sh
# 对于SigLIP
bash DIVA_for_SigLIP.sh
# 对于DFN
bash DIVA_for_DFN.sh
模型库
| 方法 | 图像尺寸 | 参数量 (M) | 平均得分 |
|---|---|---|---|
| OpenAI ViT-L-14 | 224² | 427.6 | 25.9 (+6.6) |
| OpenAI ViT-L-14 | 336² | 427.9 | 25.2 (+5.2) |
| MetaCLIP ViT-L-14 | 224² | 427.6 | 27.4 (+3.7) |
| MetaCLIP ViT-H-14 | 224² | 986.1 | 31.9 (+6.7) |
| SigLIP ViT-SO-14 | 224² | 877.4 | 40.7 (+2.9) |
| SigLIP ViT-SO-14 | 384² | 878.0 | 38.5 (+1.5) |
| DFN ViT-H-14 | 224² | 986.1 | 43.7 (+4.4) |
| DFN ViT-H-14 | 378² | 986.7 | 37.8 (+3.0) |
值得注意的是,由于训练阶段引入的条件设计和推理阶段选择局部补丁词元的随机性,使用我们提供的OpenAI CLIP权重在MMVP_VLM基准测试上获得的分数可能与我们论文中报告的结果不同。此时,如果分数不符合预期,我们建议尝试多次使用不同的随机种子。
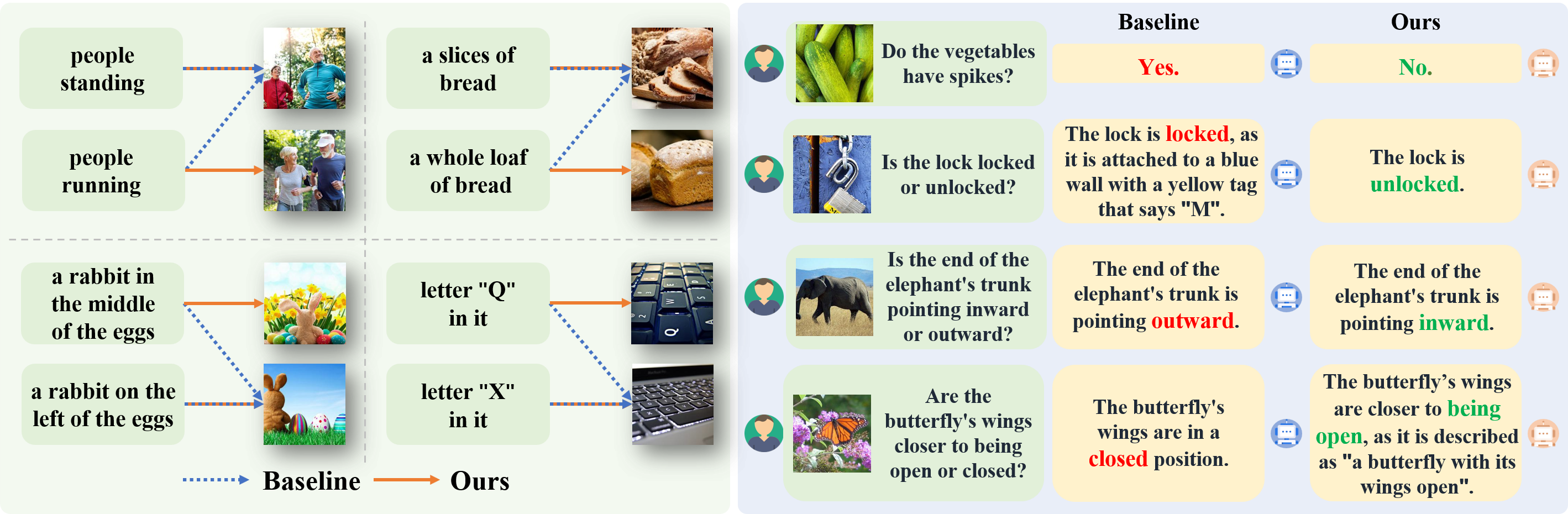
🎨 可视化
💙 致谢
DIVA 基于优秀的 Diffusion-TTA、MMVP、CLIP、OpenCLIP 和 timm 构建。
📝 引用
@article{wang2024diffusion,
title={Diffusion Feedback Helps CLIP See Better},
author={Wang, Wenxuan and Sun, Quan and Zhang, Fan and Tang, Yepeng and Liu, Jing and Wang, Xinlong},
journal={arXiv preprint arXiv:2407.20171},
year={2024}
}











