
 访问官网
访问官网 Github
Github 论文
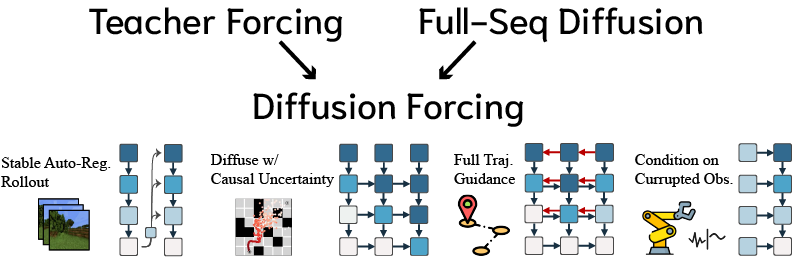
论文扩散强制:下一个词预测遇上全序列扩散
[项目网站] [论文]
Boyuan Chen1, Diego Martí Monsó2, Yilun Du1, Max Simchowitz1, Russ Tedrake1, Vincent Sitzmann1
1麻省理工学院 2慕尼黑工业大学
这是我们论文扩散强制:下一个词预测遇上全序列扩散的v1.5代码库。main分支包含我们最新的带有时间注意力的重新实现(推荐使用),而paper分支包含原始论文用于复现目的的RNN代码。
@misc{chen2024diffusionforcingnexttokenprediction,
title={扩散强制:下一个词预测遇上全序列扩散},
author={Boyuan Chen and Diego Marti Monso and Yilun Du and Max Simchowitz and Russ Tedrake and Vincent Sitzmann},
year={2024},
eprint={2407.01392},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2407.01392},
}
项目说明
设置
如果你想使用我们最新改进的视频和规划实现(使用时间注意力而非RNN),请保持在当前分支。如果你对复现原始论文的声明感兴趣,请通过git checkout paper切换到原始论文使用的分支。
运行conda create python=3.10 -n diffusion-forcing创建环境。
运行conda activate diffusion-forcing激活此环境。
安装时间序列、视频和机器人学所需的依赖:
pip install -r requirements.txt
注册一个wandb账户以进行云端日志记录和检查点保存。在命令行中,运行wandb login登录。
然后修改configurations/config.yaml中的wandb实体为你的wandb账户。
可选地,如果你想进行迷宫规划,由于d4rl的过时依赖,需要安装以下复杂的依赖。这涉及首先安装mujoco 210,然后运行
pip install -r extra_requirements.txt
使用预训练检查点快速开始
由于数据集很大,我们提供了一个迷你子集和预训练检查点,供你快速测试我们的模型!要使用它们,请从这里下载迷你数据集和检查点到项目根目录,并用tar -xzvf quickstart_atten.tar.gz解压。文件将出现在data和outputs/xxx.ckpt中。如果你在发布检查点之前fork了项目,请确保也git pull上游以使用最新版本的代码!
然后运行以下命令,并前往wandb面板查看结果。
视频预测:
我们的可视化是并排的,左侧是预测,右侧是真实数据。然而,由于序列高度随机,真实数据预计不会与预测对齐。提供真实数据仅用于提供质量参考。
自回归生成与训练长度相同的Minecraft视频:
python -m main +name=sample_minecraft_pretrained load=outputs/minecraft.ckpt experiment.tasks=[validation]
要让模型滚动超出训练长度,只需在上述命令后附加dataset.validation_multiplier=8,它将滚动8倍于训练的最大序列长度。
上述检查点使用少量帧训练了100K步。我们已经验证了扩散强制在潜在扩散设置中有效,并且可以扩展到更多标记而不牺牲组合性(使用本仓库之外的一些额外技术)!敬请期待我们的下一个项目!
迷宫规划:
随着我们获得更多见解,迷宫规划设置有所改变,详情请参见训练部分相应段落。我们尚未重新实现MCTG,但你已经可以在wandb日志上看到不错的可视化效果。
中等迷宫
python -m main experiment=exp_planning algorithm=df_planning dataset=maze2d_medium dataset.action_mean=[] dataset.action_std=[] dataset.observation_mean=[3.5092521,3.4765592] dataset.observation_std=[1.3371079,1.52102] load=outputs/maze2d_medium_x.ckpt experiment.tasks=[validation] algorithm.guidance_scale=3 +name=maze2d_medium_x_sampling
大型迷宫
python -m main experiment=exp_planning algorithm=df_planning dataset=maze2d_large dataset.observation_mean=[3.7296331,5.3047247] dataset.observation_std=[1.8070312,2.5687592] dataset.action_mean=[] dataset.action_std=[] load=outputs/maze2d_large_x.ckpt experiment.tasks=[validation] algorithm.guidance_scale=2 +name=maze2d_large_x_sampling
我们还探索了几个更多的设置,但尚未重新实现原始论文中的所有内容。如果你对那些检查点感兴趣,请查看本README文件的源代码中被注释掉的检查点加载说明。
python -m main experiment=exp_planning algorithm=df_planning dataset=maze2d_large dataset.observation_std=[3.6140624,5.1375184,9.747382,10.5974788] dataset.action_mean=[] dataset.action_std=[] load=outputs/maze2d_large_xv.ckpt experiment.tasks=[validation] algorithm.guidance_scale=4 +name=maze2d_large_xv_sampling
这里还有一个检查点,我们在其中采用了扩散动作,这是一个具有挑战性的设置,之前的论文中没有涉及。虽然我们还没有让它像原始的RNN版本的扩散强制那样工作得很好,但它确实有不错的数据。你可以稍微调高guidance scale。
python -m main experiment=exp_planning algorithm=df_planning dataset=maze2d_medium dataset.observation_std=[2.67,3.04,8,8] dataset.action_std=[6,6] load=outputs/maze2d_medium_xva.ckpt experiment.tasks=[validation] algorithm.guidance_scale=2 algorithm.open_loop_horizon=10 +name=maze2d_medium_xva_sampling
python -m main experiment=exp_planning algorithm=df_planning dataset=maze2d_large dataset.observation_std=[3.62,5.14,9.76,10.6] dataset.action_std=[3,3] load=outputs/maze2d_large_xva.ckpt experiment.tasks=[validation] algorithm.guidance_scale=2 algorithm.open_loop_horizon=10 +name=maze2d_large_xva_sampling
训练
视频
视频预测需要下载大型数据集。首先,如果你按照"使用预训练检查点快速开始"部分下载了mini子集,请删除mini子集文件夹data/minecraft和data/dmlab,因为这次我们必须下载完整的数据集。我们已经在Python中编写了代码,如果数据集不存在,它会为你下载。由于源代码的下载速度较慢,这可能需要几天时间。如果你更喜欢自己通过bash脚本来完成,请参考原始TECO数据集中的bash脚本,并使用他们README的Dataset部分中的dmlab.sh和minecraft.sh,也许可以将bash脚本分割成并行脚本。
然后只需运行相应的命令:
Minecraft
python -m main +name=your_experiment_name algorithm=df_video dataset=video_minecraft
DMLab
python -m main +name=your_experiment_name algorithm=df_video dataset=video_dmlab algorithm.weight_decay=1e-3 algorithm.diffusion.architecture.network_size=48 algorithm.diffusion.architecture.attn_dim_head=32 algorithm.diffusion.architecture.attn_resolutions=[8,16,32,64] algorithm.diffusion.beta_schedule=cosine
无因果掩码
只需在命令后添加algorithm.causal=False即可。
尝试采样
请查看"加载检查点以进行评估"段落,了解如何使用load=加载检查点。然后,运行完全相同的训练命令,添加experiment.tasks=[validation] load={wandb_run_id}来加载检查点并尝试采样。
要了解如何生成比训练序列更长的序列,你可以在"使用预训练检查点快速开始"部分找到说明。请记住,无限滚动而不使用滑动窗口是paper分支上原始RNN实现的特性,而这个版本必须使用滑动窗口,因为它是时间注意力。
默认情况下,我们运行带稳定化的自回归采样。要联合采样下两个标记,你可以在上述命令后添加以下内容:algorithm.scheduling_matrix=full_sequence algorithm.chunk_size=2。
迷宫规划
对于那些只想重现原始论文而不是transformer架构的人,请查看代码的paper分支。
中等迷宫
python -m main experiment=exp_planning algorithm=df_planning dataset=maze2d_medium dataset.action_mean=[] dataset.action_std=[] dataset.observation_mean=[3.5092521,3.4765592] dataset.observation_std=[1.3371079,1.52102] +name=maze2d_medium_x
大型迷宫
python -m main experiment=exp_planning algorithm=df_planning dataset=maze2d_large dataset.observation_mean=[3.7296331,5.3047247] dataset.observation_std=[1.8070312,2.5687592] dataset.action_mean=[] dataset.action_std=[] +name=maze2d_large_x
模型训练后运行规划
请查看"加载检查点以进行评估"段落,了解如何使用load=加载检查点。要进行采样,只需在上述训练完成的命令后添加load={wandb_id_of_above_runs} experiment.tasks=[validation] algorithm.guidance_scale=2 +name=maze2d_sampling。你可以自由调整guidance_scale,范围从1到5。
这个版本的迷宫规划使用了与原始论文不同的扩散强制版本 - 在对扩散强制进行后续研究时,我们意识到使用独立噪声进行训练实际上也构建了因果和非因果模型之间的平滑插值,因为我们可以通过完全噪声(完全因果)或部分噪声(插值)来掩盖未来。最好的是,在这种设置下,你仍然可以通过金字塔采样考虑因果不确定性,方法是在不同噪声级别掩盖标记,并且你仍然可以拥有灵活的视野,因为你可以告诉模型填充的条目是纯噪声,这是扩散强制的独特能力。
我们还反思了一下环境,得出结论认为原始指标不一定是一个好指标,因为迷宫规划应该奖励那些能够最快规划到达目标路线的人,而不是最终到达那里的缓慢行走代理。数据集从未包含停留在目标处的数据,所以代理应该在达到目标后离开。我认为Diffuser有一个不公平的优势,只是生成缓慢的计划,恰好让代理在目标附近停留更长时间并获得很高的奖励,利用了环境设计的缺陷(一个好的设计应该包括对到达目标所需时间较长的惩罚)。因此,在这个版本的代码中,我们只是优化了灵活视野的规划,试图尽快到达目标,如果离开目标,规划器会自动返回目标,因为停留从未出现在数据集中。你可以在wandb日志界面中看到我们设计的新指标。
时间序列和机器人
请查看paper分支获取原始论文使用的代码。如果我以后有时间,我也会用transformer重新实现这两个领域,以完成这个分支。
更新日志
| 日期 | 备注 |
|---|---|
| 2024/7/30 | 将RNN升级为时间注意力,将原始代码移至'paper'分支 |
| 2024/7/3 | 代码初始发布。如果你有问题或发现此版本中的任何错误,请给我发邮件。 |
基础设施说明
本仓库源自Boyuan Chen的研究模板仓库。根据MIT许可证,你必须在README.md中保留上述句子并保留LICENSE文件以对作者表示致谢。
所有实验可以通过python -m main +name=xxxx {选项}来启动,你可以在本文后面找到更多细节。
代码库会在可用时自动使用CUDA或Macbook M1 GPU。
对于Slurm集群(如MIT超级云),你可以在登录节点上运行python -m main cluster=mit_supercloud {选项}。它会自动生成Slurm脚本并在计算节点上运行。即使计算节点离线,脚本仍会自动将wandb日志同步到云端,延迟不到1分钟。按照"添加Slurm集群"部分,添加你自己的Slurm也很容易。
为你的项目修改
首先,使用此模板创建一个新仓库。确保新仓库的名称是你想用于wandb日志记录的名称。
按照algorithms/README.md和algorithms/diffusion_forcing/df_video.py中的示例代码,在algorithms中添加你的方法和基准。对于PyTorch实验,将你的算法编写为pytorch lightning pl.LightningModule,它有详尽的文档。快速入门可以阅读此链接中的"Define a LightningModule"部分。最后,为你添加的每个算法在configurations/algorithm中添加一个yaml配置文件,仿照configurations/algorithm/df_video.yaml。
按照datasets/README.md和datasets/video中的示例代码,在datasets中添加你的数据集。最后,为你添加的每个数据集在configurations/dataset中添加一个yaml配置文件,仿照configurations/dataset/video_dmlab.yaml。
按照experiments/README.md或experiments/exp_video.py中的示例代码,在experiments中添加你的实验。然后在experiments/__init__.py中注册你的实验。最后,为你添加的每个实验在configurations/experiment中添加一个yaml配置文件,仿照configurations/experiment/exp_video.yaml。
修改configurations/config.yaml,将algorithm设置为你想在configurations/algorithm中使用的yaml文件;将experiment设置为你想在configurations/experiment中使用的yaml文件;将dataset设置为你想在configurations/dataset中使用的yaml文件,如果不需要数据集则设为null。注意字段不应包含.yaml后缀。
设置完成!
进入你的项目根目录。现在你可以通过python main.py +name=<为你的实验命名>来启动新实验。你可以通过添加algorithm=xxx或dataset=xxx等参数来运行基准或不同的数据集。你也可以按照下一节的说明覆盖任何yaml配置。
特别注意,如果你想为你的实验定义一个新任务(例如除了training和test之外的任务),你可以在实验类中将其定义为一个方法,并使用experiment.tasks=[task_name]来运行它。假设你在training任务之前有一个generate_dataset任务,并且你在实验类中实现了它,那么你可以运行python -m main +name xxxx experiment.tasks=[generate_dataset,training]来在训练前执行它。
传递参数
我们使用hydra而不是argparse来配置每个代码层级的参数。你既可以在configuration文件夹中编写静态配置,也可以在运行时覆盖部分静态配置,使用命令行参数。
例如,参数algorithm=example_classifier experiment.lr=1e-3将覆盖configurations/experiment/example_classifier.yaml中的lr变量。参数wandb.mode将覆盖configurations/config.yaml文件中wandb命名空间下的mode。
所有静态配置和运行时覆盖将自动记录到云端。
恢复检查点和日志
对于机器学习实验,所有检查点和日志都会自动记录到云端,因此你可以在另一台服务器上恢复它们。只需在命令行参数中添加resume={wandb_run_id}即可恢复。run_id可以在wandb仪表板中的wandb运行URL中找到。默认情况下,一次运行中的最新检查点会无限期存储,而该运行中较早的检查点会在5天后删除以节省存储空间。
另一方面,有时你可能想要使用不同的run_id启动新运行,但仍然加载先前的检查点。这可以通过设置load={wandb_run_id / ckpt path}标志来完成。
加载检查点进行评估
参数experiment.tasks=[task_name1,task_name2](注意这里需要[]括号)允许选择要执行的一系列任务,如training、validation和test。因此,要测试机器学习检查点,你可以运行python -m main load={your_wandb_run_id} experiment.tasks=[test]。
更一般地,任务名称是你的实验类中相应的方法名称。对于BaseLightningExperiment,我们已经为你定义了三个方法:training、validation和test,但你也可以通过在预期任务名称下为你的实验类创建方法来定义自己的任务。
调试
我们提供了一个有用的调试标志,你可以通过python main.py debug=True启用。这将启用数值错误跟踪,并为你的实验、算法和数据集类设置cfg.debug为True。但是,这个调试标志会使机器学习代码变得非常慢,因为它会自动跟踪所有参数和梯度!
添加Slurm集群
通过在configurations/cluster中添加yaml文件,可以很容易地添加你自己的Slurm集群。你可以参考configurations/cluster/mit_supercloud.yaml作为示例。











