
 访问官网
访问官网 Github
Github Huggingface
Huggingface 文档
文档🐈 friendly-stable-audio-tools
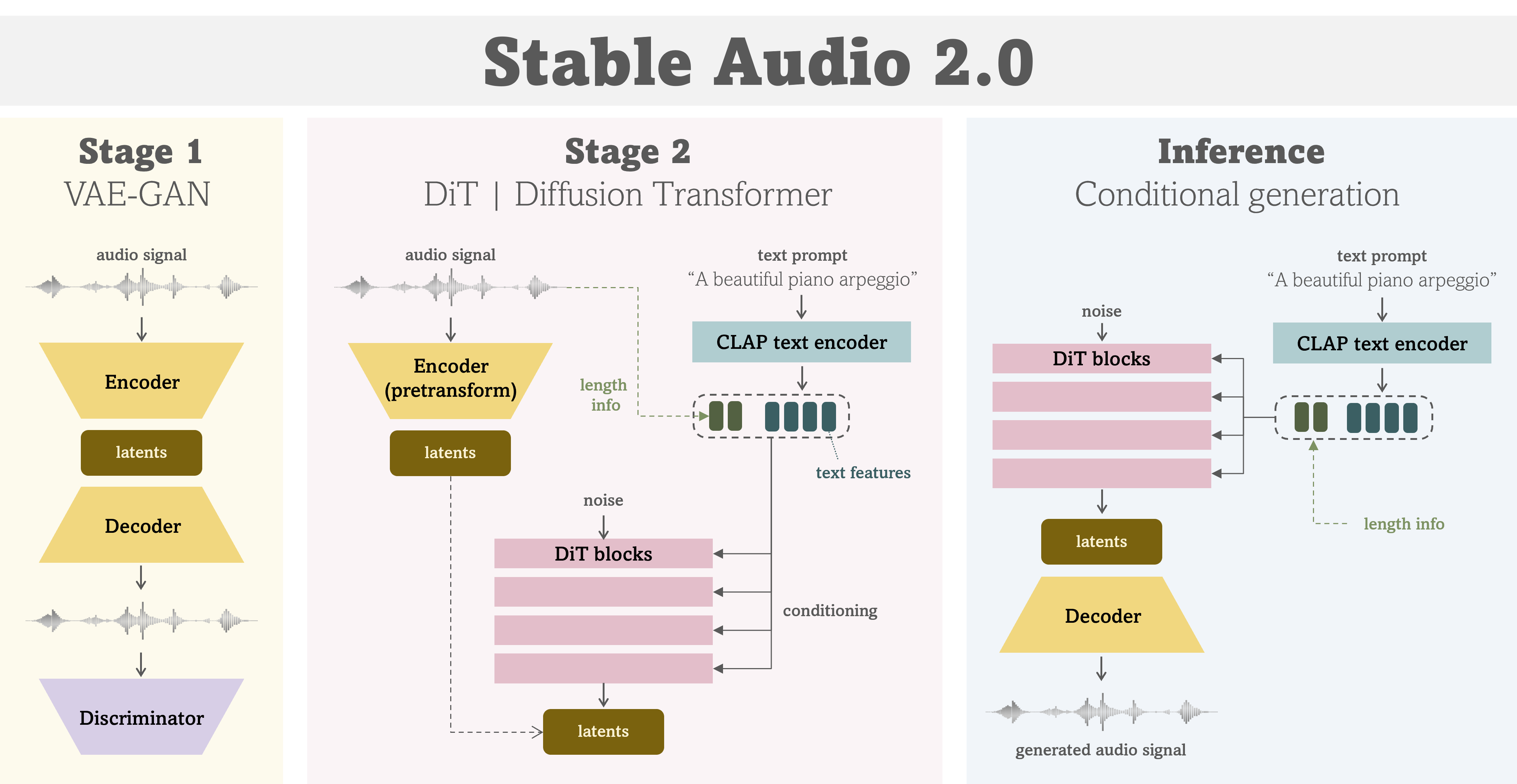
本仓库是对 stable-audio-tools 的重构/更新版本,stable-audio-tools 是 Stability AI 最初开发的音频/音乐生成模型开源代码。
本仓库包含以下额外功能:
- 🔥 重构了
stable-audio-tools的代码,提高了可读性和易用性。 - 🔥 提供了用于评估和使用自己训练模型的实用脚本。
- 🔥 提供了如何训练
Stable Audio 2.0等模型的说明。 - 🔥 为使用
Stable Audio Open 1.0提供了详细文档和便捷脚本。
🔥 Stable Audio Open
Stability AI 现已开源 Stable Audio 的预训练模型。
如果您对如何使用 Stable Audio Open 感兴趣,请参阅以下文档以获取详细说明。
- 🔥 Stable Audio Open 1.0 文档
- 🔥 现在您可以使用通过 YAML 文件提供的提示输入进行多 GPU/节点生成。 请参见此处的示例 -> generate_conditions.yaml。
要求
- PyTorch 2.0 或更高版本,以支持 Flash Attention
- 本仓库的开发在 Python 3.8.10 或更高版本中进行
安装
要运行训练脚本或推理代码,您需要克隆此仓库,导航到根目录,然后执行以下 pip 命令:
$ git clone https://github.com/yukara-ikemiya/friendly-stable-audio-tools.git
$ cd friendly-stable-audio-tools
$ pip install .
$ # 为避免 Accelerate 导入错误,您可能需要执行以下命令
$ pip uninstall -y transformer-engine
构建训练环境
为简化训练环境的设置,我建议使用 Docker 或 Singularity 等容器系统,而不是在每台 GPU 机器上安装依赖项。以下是创建 Docker 和 Singularity 容器的步骤。
所有示例脚本都存储在 container 文件夹中。
请确保事先安装了 Docker 和 Singularity。
1. 创建 Docker 镜像
$ # 创建 Docker 镜像
$ NAME=friendly-stable-audio-tools
$ docker build -t ${NAME} -f ./container/${NAME}.Dockerfile .
2. 将 Docker 镜像转换为 Singularity 容器
$ # 将 Docker 镜像转换为 Singularity 容器
$ singularity build friendly-stable-audio-tools.sif docker-daemon://friendly-stable-audio-tools
运行上述脚本后,应在工作目录中创建 friendly-stable-audio-tools.sif。
界面
提供了一个基本的 Gradio 界面来测试训练好的模型。
例如,要为 stable-audio-open-1.0 模型创建界面,一旦您在 Hugging Face 上接受了模型条款,您可以运行:
$ python3 ./run_gradio.py --pretrained-name stabilityai/stable-audio-open-1.0
如果您需要关于 Stable Audio Open 的更详细说明,我建议参考 Stable Audio Open 文档中的 Gradio 界面 部分。
run_gradio.py 脚本接受以下命令行参数:
--pretrained-namePRETRAINED_NAME(可选)- Hugging Face Hub 上的模型名称(例如
stabilityai/stable-audio-open-1.0) - 将优先选择仓库中的
model.safetensors而非model.ckpt - 指定此参数时,将忽略
model-config和ckpt-path。
- Hugging Face Hub 上的模型名称(例如
--model-configMODEL_CONFIG(可选)- 本地模型的模型配置文件路径
--ckpt-pathCKPT_PATH(可选)- 本地模型的未包装模型检查点文件路径
--pretransform-ckpt-pathPRETRANSFORM_CKPT_PATH(可选)- 未包装的预转换检查点路径。这将替换模型中的预转换。
--usernameUSERNAME /--passwordPASSWORD(可选)- 用于设置 Gradio 演示的登录信息
--model-half(可选)- 是否使用半精度
--tmp-dirTMP_DIR(可选)- 保存输出文件的临时目录
日志记录
WandB 设置
训练代码还需要一个 Weights & Biases 账户来记录训练输出和演示。创建账户并使用以下命令登录:
$ wandb login
或者您也可以通过环境变量 WANDB_API_KEY 传递 API 密钥。
(登录账户后,您可以从 https://wandb.ai/authorize 获取 API 密钥。)
$ WANDB_API_KEY="12345x6789y..."
当您想使用 Docker 或 Singularity 等容器执行代码时,这种方法很方便。
训练
配置文件
在开始训练之前,您需要准备以下两个配置文件。
- 模型配置文件
- 数据集配置文件
有关这些文件的更多信息,请参阅下面的配置部分。
从头开始训练
要开始训练,请在仓库根目录中运行 train.py 脚本:
$ python3 train.py --dataset-config /path/to/dataset/config --model-config /path/to/model/config --name my_experiment
--name 参数将设置您的 Weights and Biases 运行的项目名称。
微调
微调涉及从预训练检查点恢复训练运行。
- 要从包装的检查点恢复训练,您可以使用
--ckpt-path标志将检查点路径 (.ckpt) 传递给train.py。 - 要从预训练的未包装模型开始全新训练,您可以使用
--pretrained-ckpt-path标志将未包装的检查点路径 (.ckpt) 传递给train.py。
解包模型
stable-audio-tools 使用 PyTorch Lightning 来实现多 GPU 和多节点训练。
当模型正在训练时,它被包装在一个"训练包装器"中,这是一个包含所有仅用于训练的相关对象的 pl.LightningModule。这包括自动编码器的判别器、模型的 EMA 副本以及所有优化器状态等内容。
训练期间创建的检查点文件包括这个训练包装器,这大大增加了检查点文件的大小。
unwrap_model.py 接收一个包装的模型检查点,并保存一个仅包含模型本身的新检查点文件。
可以从存储库根目录运行以下命令:
$ python3 unwrap_model.py --model-config /path/to/model/config --ckpt-path /path/to/wrapped/ckpt.ckpt --name /new/path/to/new_ckpt_name
未包装的模型检查点是以下情况所必需的:
- 推理脚本
- 将模型用作另一个模型的预转换(例如,将自动编码器模型用于潜在扩散)
- 使用修改后的配置对预训练模型进行微调(即部分初始化)
配置
stable-audio-tools 的训练和推理代码基于 JSON 配置文件,这些文件定义了模型超参数、训练设置和有关训练数据集的信息。
模型配置
模型配置文件定义了加载模型进行训练或推理所需的所有信息。它还包含微调模型或从头开始训练所需的训练配置。
模型配置的顶层定义了以下属性:
model_type- 正在定义的模型类型,目前仅限于
"autoencoder", "diffusion_uncond", "diffusion_cond", "diffusion_cond_inpaint", "diffusion_autoencoder", "lm"之一。
- 正在定义的模型类型,目前仅限于
sample_size- 训练期间提供给模型的音频长度,以样本为单位。对于扩散模型,这也是推理时使用的原始音频样本长度。
sample_rate- 训练期间提供给模型的音频采样率,以及推理期间生成的音频采样率,单位为 Hz。
audio_channels- 训练期间提供给模型的音频通道数,以及推理期间生成的音频通道数。默认为 2。单声道设置为 1。
model- 正在定义的模型的具体配置,根据
model_type而变化。
- 正在定义的模型的具体配置,根据
training- 模型的训练配置,根据
model_type而变化。提供训练参数以及演示。
- 模型的训练配置,根据
数据集配置
stable-audio-tools 目前支持两种数据源:本地音频文件目录和存储在 Amazon S3 中的 WebDataset 数据集。更多信息可以在数据集配置文档中找到。
其他训练标志
train.py 的其他可选标志包括:
--config-file- 存储库根目录中 defaults.ini 文件的路径,如果从存储库根目录以外的目录运行
train.py,则需要此标志。
- 存储库根目录中 defaults.ini 文件的路径,如果从存储库根目录以外的目录运行
--pretransform-ckpt-path- 用于各种模型类型,如潜在扩散模型,以加载预训练的自动编码器。需要未包装的模型检查点。
--save-dir- 保存模型检查点的目录。
--checkpoint-every- 保存检查点之间的步数。
- 默认值:10000
--batch-size- 训练期间每个 GPU 的样本数。应设置为 GPU VRAM 所允许的最大值。
- 默认值:8
--num-gpus- 每个节点用于训练的 GPU 数量。
- 默认值:1
--num-nodes- 用于训练的 GPU 节点数量。
- 默认值:1
--accum-batches- 启用并设置梯度批累积的批次数。在较小的 GPU 上训练时,用于增加有效批量大小。
--strategy- 分布式训练的多 GPU 策略。设置为
deepspeed将启用 DeepSpeed ZeRO Stage 2。 - 默认值:如果
--num_gpus> 1,则为ddp,否则为 None
- 分布式训练的多 GPU 策略。设置为
--precision- 训练期间使用的浮点精度。
- 默认值:16
--num-workers- 数据加载器使用的 CPU 工作进程数。
--seed- PyTorch 的 RNG 种子,有助于确定性训练。
🔥 让我们训练 Stable Audio 2.0
先决条件
准备 CLAP 编码器的检查点
要使用 CLAP 编码器进行音乐生成的条件控制,您必须准备 CLAP 的预训练检查点文件。
- 从 LAION CLAP 存储库 下载使用音乐数据集训练的预训练 CLAP 检查点(
music_audioset_epoch_15_esc_90.14.pt)。 - 将检查点文件存储到您选择的目录中。
- 按如下方式编辑 Stable Audio 2.0 的
模型配置文件
= stable_audio_2_0.json =
...
"model": {
...
"conditioning": {
"configs": [
{
...
"config": {
...
"clap_ckpt_path": "ckpt/clap/music_audioset_epoch_15_esc_90.14.pt",
...
准备用于训练的音频和元数据
由于 Stable Audio 使用文本提示作为音乐生成的条件,因此除了音频数据之外,您还必须准备它们作为元数据。
在本地环境中使用数据集时,我建议使用以下 JSON 格式的元数据。
- 您可以在 JSON 文件中包含任何信息作为元数据,但必须始终包含名为
prompt的文本数据,这是 Stable Audio 训练所需的。 = music_2.json =
{
"prompt": "这是一首传递正能量的电子音乐。"
}
- 元数据文件必须与相应的音频文件放在同一目录下。文件名也必须相同。
.
└── dataset/
├── music_1.wav
├── music_1.json
├── music_2.wav
├── music_2.json
└── ...
第一阶段:VAE-GAN(压缩模型)
训练
作为Stable Audio 2.0的第一阶段,你将训练一个VAE-GAN,这是一个音频信号的压缩模型。
VAE-GAN的模型配置文件位于configs目录中。关于数据集配置,请根据你自己的数据集准备相应的数据集配置文件。
准备好配置文件后,你可以这样执行训练任务:
CONTAINER_PATH="/path/to/sif/friendly-stable-audio-tools.sif"
ROOT_DIR="/path/to/friendly-stable-audio-tools/"
DATASET_DIR="/path/to/your/dataset/"
OUTPUT_DIR="/path/to/output/directory/"
MODEL_CONFIG="stable_audio_tools/configs/model_configs/autoencoders/stable_audio_2_0_vae.json"
DATASET_CONFIG="stable_audio_tools/configs/dataset_configs/local_training_example.json"
BATCH_SIZE=10 # 警告:这是每个GPU的批量大小
WANDB_API_KEY="12345x6789y..."
PORT=12345
# Singularity容器案例
# 注意:请根据需要修改各项配置
singularity exec --nv --pwd $ROOT_DIR -B $ROOT_DIR -B $DATASET_DIR \
--env WANDB_API_KEY=$WANDB_API_KEY \
${CONTAINER_PATH} \
torchrun --nproc_per_node gpu --master_port ${PORT} \
${ROOT_DIR}/train.py \
--dataset-config ${DATASET_CONFIG} \
--model-config ${MODEL_CONFIG} \
--name "vae_training" \
--num-gpus 8 \
--batch-size ${BATCH_SIZE} \
--num-workers 8 \
--save-dir ${OUTPUT_DIR}
模型解包
如解包模型部分所述, 完成VAE训练后, 你需要解包模型检查点以用于下一阶段的训练。
CKPT_PATH="/path/to/wrapped_ckpt/last.ckpt"
# 注意:文件扩展名".ckpt"将自动添加到OUTPUT_DIR名称的末尾
OUTPUT_PATH="/path/to/output_name/unwrapped_last"
singularity exec --nv --pwd $ROOT_DIR -B $ROOT_DIR \
--env WANDB_API_KEY=$WANDB_API_KEY \
${CONTAINER_PATH} \
torchrun --nproc_per_node gpu --master_port ${PORT} \
${ROOT_DIR}/unwrap_model.py \
--model-config ${MODEL_CONFIG} \
--ckpt-path ${CKPT_PATH} \
--name ${OUTPUT_PATH}
重构测试
完成VAE训练后,你可能想要测试和评估训练模型的重构质量。
我支持使用reconstruct_audios.py对目录中的音频文件进行重构,
你可以使用重构后的音频进行评估。
AUDIO_DIR="/path/to/original_audio/"
OUTPUT_DIR="/path/to/output_audio/"
FRAME_DURATION=1.0 # [秒]
OVERLAP_RATE=0.01
BATCH_SIZE=50
singularity exec --nv --pwd $ROOT_DIR -B $ROOT_DIR -B $DATASET_DIR \
--env WANDB_API_KEY=$WANDB_API_KEY \
${CONTAINER_PATH} \
torchrun --nproc_per_node gpu --master_port ${PORT} \
${ROOT_DIR}/reconstruct_audios.py \
--model-config ${MODEL_CONFIG} \
--ckpt-path ${UNWRAP_CKPT_PATH} \
--audio-dir ${AUDIO_DIR} \
--output-dir ${OUTPUT_DIR} \
--frame-duration ${FRAME_DURATION} \
--overlap-rate ${OVERLAP_RATE} \
--batch-size ${BATCH_SIZE}
第二阶段:扩散变换器(DiT)
训练
作为Stable Audio 2.0的第二阶段,你将训练一个DiT,这是一个潜在域中的生成模型。
在这一部分之前,请确保
现在,你可以按如下方式训练DiT模型:
CONTAINER_PATH="/path/to/sif/friendly-stable-audio-tools.sif"
ROOT_DIR="/path/to/friendly-stable-audio-tools/"
DATASET_DIR="/path/to/your/dataset/"
OUTPUT_DIR="/path/to/output/directory/"
MODEL_CONFIG="stable_audio_tools/configs/model_configs/txt2audio/stable_audio_2_0.json"
DATASET_CONFIG="stable_audio_tools/configs/dataset_configs/local_training_example.json"
# VAE(第一阶段)模型的预训练检查点
PRETRANSFORM_CKPT="/path/to/vae_ckpt/unwrapped_last.ckpt"
BATCH_SIZE=10 # 警告:这是每个GPU的批量大小
WANDB_API_KEY="12345x6789y..."
PORT=12345
singularity exec --nv --pwd $ROOT_DIR -B $ROOT_DIR -B $DATASET_DIR \
--env WANDB_API_KEY=$WANDB_API_KEY \
${CONTAINER_PATH} \
torchrun --nproc_per_node gpu --master_port ${PORT} \
${ROOT_DIR}/train.py \
--dataset-config ${DATASET_CONFIG} \
--model-config ${MODEL_CONFIG} \
--pretransform-ckpt-path ${PRETRANSFORM_CKPT} \
--name "dit_training" \
--num-gpus ${NUM_GPUS} \
--batch-size ${BATCH_SIZE} \
--save-dir ${OUTPUT_DIR}
待办事项
- 添加便捷的采样脚本
- 增加更多音频增强功能
- 为Gradio界面添加文档
- 添加故障排除部分
- 添加贡献指南











