
 Github
Github Huggingface
Huggingface 论文
论文分割任意异常


这个仓库包含了通过混合提示正则化实现无需训练的任意异常分割,SAA+的官方实现。
SAA+旨在无需训练即可分割任意异常。我们通过混合提示正则化来适配现有的基础模型,即Grounding DINO和Segment Anything,来实现这一目标。
:fire:最新动态
- 我们添加了一个Huggingface演示。尽情体验吧~
- 我们更新了colab演示。尽情体验吧~
- 我们已经为SAA+更新了这个仓库。
- 我们已发布通过混合提示正则化实现无需训练的任意异常分割,SAA+。
:gem:框架
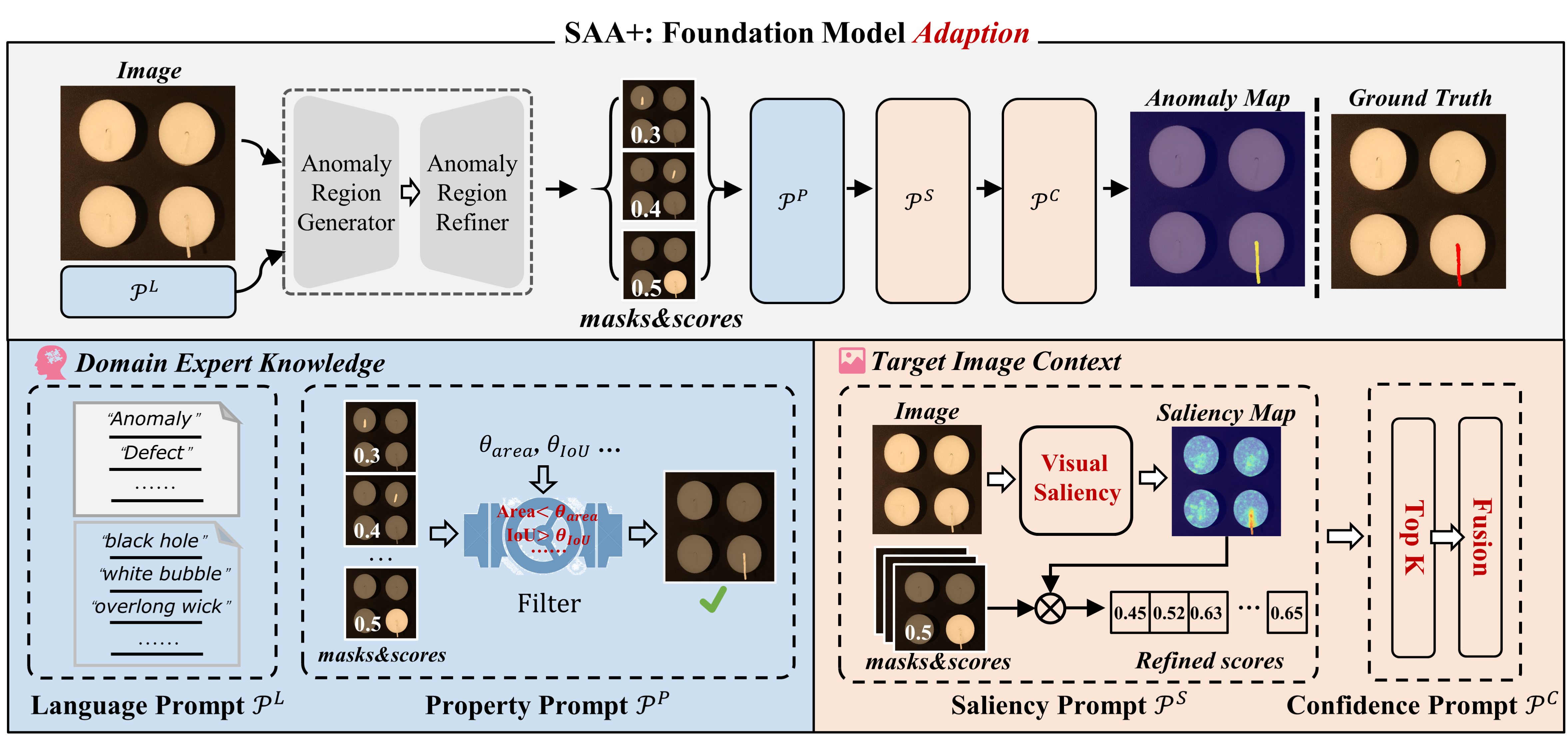
我们发现,简单组合基础模型会导致严重的语言歧义。因此,我们引入了源自领域专家知识和目标图像上下文的混合提示,以缓解语言歧义。框架如下图所示:
快速开始
:bank:数据集准备
我们在四个公开数据集上评估SAA+:MVTec-AD、VisA、KSDD2和MTD。此外,SAA+是VAND研讨会的获胜团队之一,该研讨会提供了一个特定的数据集VisA-Challenge。要准备数据集,请按照以下说明操作:
默认情况下,我们将数据保存在../datasets目录中。
cd $ProjectRoot # 例如,/home/SAA
cd ..
mkdir datasets
cd datasets
然后,按照相应的说明准备各个数据集:
:hammer:环境设置
您可以使用我们的脚本一键设置环境并下载检查点。
cd $ProjectRoot
bash install.sh
:page_facing_up:复现公开结果
MVTec-AD
python run_MVTec.py
VisA-Public
python run_VisA_public.py
VisA-Challenge
python run_VAND_workshop.py
提交文件可在./result_VAND_workshop/visa_challenge-k-0/0shot中找到。
KSDD2
python run_KSDD2.py
MTD
python run_MTD.py
:page_facing_up:演示结果
运行以下命令获取演示结果
python demo.py
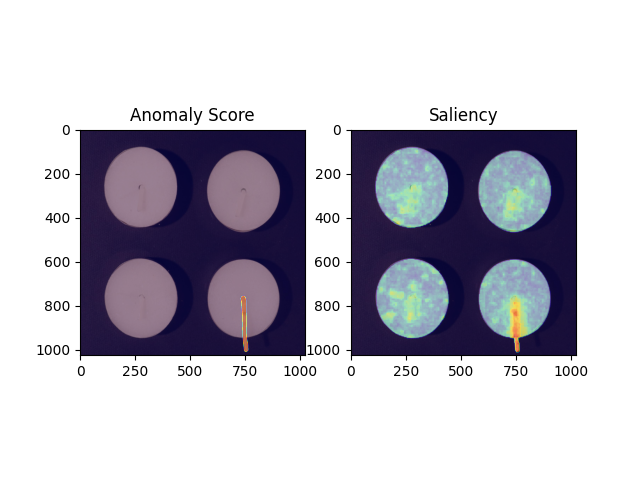
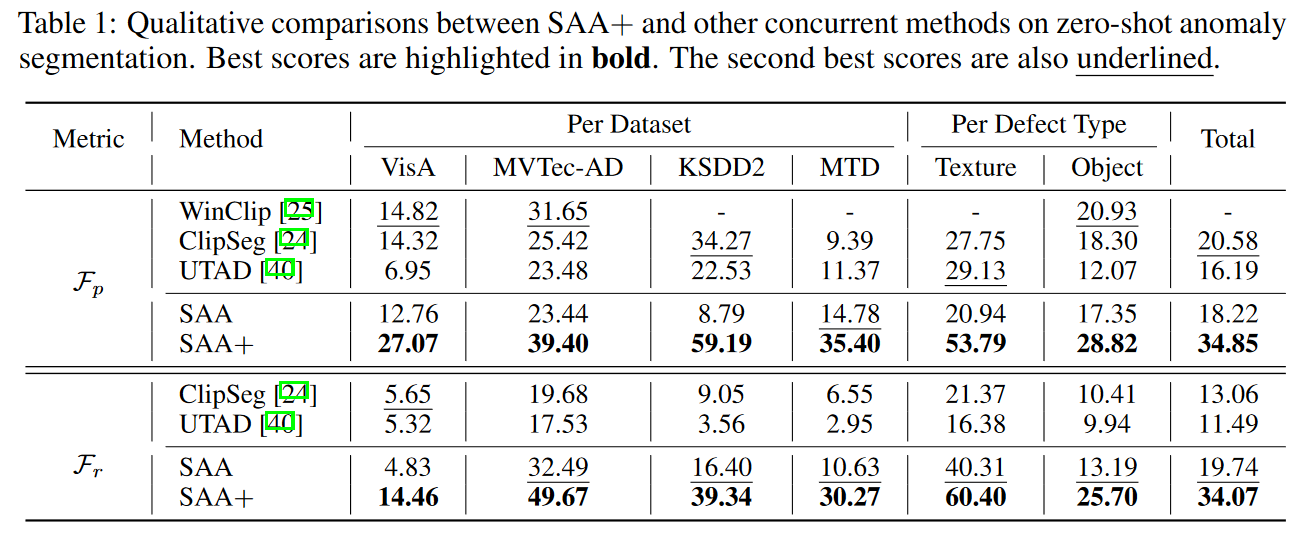
:dart:性能

:hammer: 待办事项
我们计划在近期添加以下功能:
- 更新SAA+的仓库
- 详细说明零样本异常检测框架
- 在其他图像异常检测数据集上进行评估
- 添加UI以便于评估
- 更新Colab演示
- HuggingFace演示
💘 致谢
我们的工作在很大程度上受到以下项目的启发。感谢他们令人钦佩的贡献。
随时间变化的Star数

引用
如果您发现这个项目对您的研究有帮助,请考虑引用以下BibTeX条目。
@article{cao_segment_2023,
title = {Segment Any Anomaly without Training via Hybrid Prompt Regularization},
url = {http://arxiv.org/abs/2305.10724},
number = {{arXiv}:2305.10724},
publisher = {{arXiv}},
author = {Cao, Yunkang and Xu, Xiaohao and Sun, Chen and Cheng, Yuqi and Du, Zongwei and Gao, Liang and Shen, Weiming},
urldate = {2023-05-19},
date = {2023-05-18},
langid = {english},
eprinttype = {arxiv},
eprint = {2305.10724 [cs]},
keywords = {Computer Science - Computer Vision and Pattern Recognition, Computer Science - Artificial Intelligence},
}
@article{kirillov2023segany,
title={Segment Anything},
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C. and Lo, Wan-Yen and Doll{\'a}r, Piotr and Girshick, Ross},
journal={arXiv:2304.02643},
year={2023}
}
@inproceedings{ShilongLiu2023GroundingDM,
title={Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection},
author={Shilong Liu and Zhaoyang Zeng and Tianhe Ren and Feng Li and Hao Zhang and Jie Yang and Chunyuan Li and Jianwei Yang and Hang Su and Jun Zhu and Lei Zhang},
year={2023}
}











