
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文splatter-image
"Splatter Image: 超快单视图3D重建"(CVPR 2024)的官方实现
[2024年4月16日] 自首次发布以来,该项目有几个重大更新:
- 我们现在可以重建任何物体:我们在Objaverse上训练的开放类别模型仅用了7个GPU天
- 我们现在有一个演示,您可以上传任何物体的图片,让我们的模型重建它
- 所有6个数据集的模型现已发布!我们训练了6个模型:Objaverse、多类别ShapeNet、CO3D消防栓、CO3D泰迪熊、ShapeNet汽车和ShapeNet椅子
- 在多类别ShapeNet上达到了最先进水平
- 支持多GPU训练
- CO3D中不需要相机姿态预处理
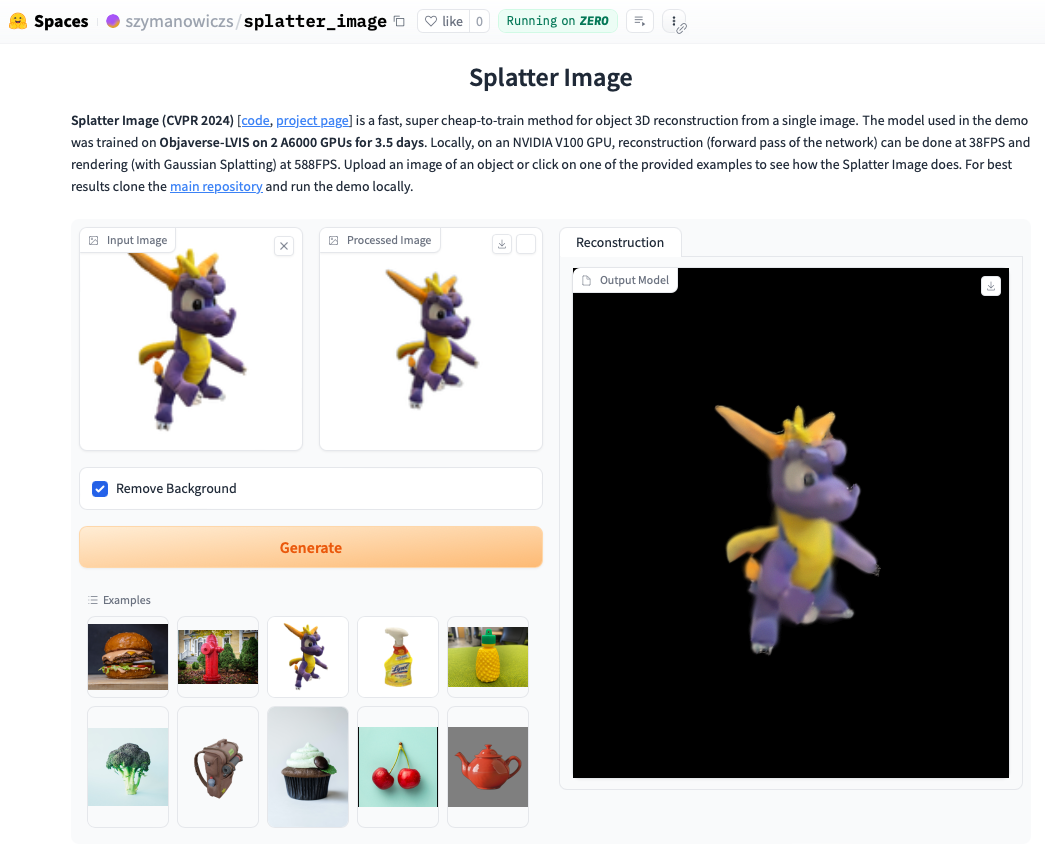
演示
查看在线演示。在本地运行演示通常会更快,您还可以看到用高斯喷溅渲染的循环(而不是提取的.ply对象,后者可能会显示伪影)。要在本地运行演示,只需按照以下安装说明操作,然后调用:
python gradio_app.py
安装
- 创建conda环境:
conda create --name splatter-image
conda activate splatter-image
按照官方说明安装Pytorch。经验证可用的Pytorch / Python / Pytorch3D组合是:
- Python 3.8, Pytorch 1.13.0, CUDA 11.6, Pytorch3D 0.7.2 或者,您可以创建一个单独的环境,安装Pytorch3D 0.7.2,仅用于CO3D数据预处理。一旦CO3D预处理完成,您也可以使用以下Python / Pytorch组合:
- Python 3.7, Pytorch 1.12.1, CUDA 11.6
- Python 3.8, Pytorch 2.1.1, CUDA 12.1
安装其他要求:
pip install -r requirements.txt
-
安装高斯喷溅渲染器,即用于将高斯点云渲染为图像的库。为此,克隆高斯喷溅仓库,并在激活conda环境的情况下运行
pip install submodules/diff-gaussian-rasterization。您需要满足硬件和软件要求。我们在NVIDIA A6000 GPU上进行了所有实验,并在NVIDIA V100 GPU上进行了速度测量。 -
如果您想在CO3D数据上进行训练,需要安装Pytorch3D 0.7.2。请参阅此处的说明。建议使用pip从预构建的二进制文件安装。在这里找到兼容的二进制文件,并使用
pip安装。例如,对于Python 3.8, Pytorch 1.13.0, CUDA 11.6,运行pip install --no-index --no-cache-dir pytorch3d -f https://anaconda.org/pytorch3d/pytorch3d/0.7.2/download/linux-64/pytorch3d-0.7.2-py38_cu116_pyt1130.tar.bz2。
数据
ShapeNet汽车和椅子
要在ShapeNet-SRN类(汽车、椅子)上进行训练/评估,请从PixelNeRF数据文件夹下载srn_.zip(=cars或chairs)。解压数据文件,并在datasets/srn.py中将SHAPENET_DATASET_ROOT更改为解压文件夹的父文件夹。例如,如果您的文件夹结构是:/home/user/SRN/srn_cars/cars_train,在datasets/srn.py中设置SHAPENET_DATASET_ROOT="/home/user/SRN"。无需额外预处理。
CO3D消防栓和泰迪熊
要在CO3D上进行训练/评估,请从CO3D发布下载消防栓和泰迪熊类。运行以下命令:
git clone https://github.com/facebookresearch/co3d.git
cd co3d
mkdir DOWNLOAD_FOLDER
python ./co3d/download_dataset.py --download_folder DOWNLOAD_FOLDER --download_categories hydrant,teddybear
接下来,在data_preprocessing/preoprocess_co3d.py中将CO3D_RAW_ROOT设置为您的DOWNLOAD_FOLDER。将CO3D_OUT_ROOT设置为您想存储预处理数据的位置。运行
python -m data_preprocessing.preprocess_co3d
并设置CO3D_DATASET_ROOT:=CO3D_OUT_ROOT。
多类别ShapeNet
对于多类别ShapeNet,我们使用DVR作者托管的NMR的ShapeNet 64x64数据集,可以在这里下载。
解压文件夹,并将NMR_DATASET_ROOT设置为解压后包含子类别文件夹的目录。换句话说,NMR_DATASET_ROOT目录应包含文件夹02691156、02828884、02933112等。
Objaverse
要在Objaverse上进行训练,我们使用了Zero-1-to-3的渲染,可以用以下命令下载:
wget https://tri-ml-public.s3.amazonaws.com/datasets/views_release.tar.gz
免责声明:请注意,这些渲染是使用Objaverse生成的。渲染整体以ODC-By 1.0许可发布。个别对象渲染的许可与它们在Objaverse中的创意共享许可相同。
此外,请从模型仓库下载lvis-annotations-filtered.json。
这个json文件包含LVIS子集中对象ID的列表。这些资产质量更高。
在datasets/objaverse.py中将OBJAVERSE_ROOT设置为解压后渲染文件夹的目录,并在同一文件中将OBJAVERSE_LVIS_ANNOTATION_PATH设置为下载的.json文件的目录。
请注意,Objaverse数据集仅用于训练和验证。它没有测试子集。
Google扫描对象
为了评估在Objaverse上训练的模型,我们使用Google扫描对象数据集以确保与训练集没有重叠。下载Free3D提供的渲染。解压下载的文件夹,并在datasets/gso.py中将GSO_ROOT设置为解压文件夹的目录。
请注意,Google扫描对象数据集不用于训练。它用于测试在Objaverse上训练的模型。
使用本仓库
预训练模型
所有数据集的预训练模型现在可以通过Huggingface Models获取。如果你只想运行定性/定量评估,不需要手动下载它们,运行评估脚本时会自动使用(见下文)。
如果你希望手动下载,可以在Huggingface模型文件页面上手动点击下载按钮。同时下载配置文件,参见eval.py了解如何加载模型。
评估
下载相关数据集后,可以通过以下命令运行评估:
python eval.py $dataset_name
$dataset_name是数据集的名称。我们支持:
gso(Google扫描物体),objaverse(Objaverse-LVIS),nmr(多类别ShapeNet),hydrants(CO3D消防栓),teddybears(CO3D泰迪熊),cars(ShapeNet汽车),chairs(ShapeNet椅子)。 代码会自动下载所请求数据集的相关模型。
你也可以训练自己的模型并通过以下命令评估:
python eval.py $dataset_name --experiment_path $experiment_path
$experiment_path应包含model_latest.pth文件和一个.hydra文件夹,其中有config.yaml。
要在验证集上评估,请使用选项--split val。
要保存物体的渲染图,相机在循环中移动,请使用选项--split vis。使用此选项时不会返回定量分数,因为并非所有数据集都有真实图像。
你可以使用选项--save_vis设置要保存多少个物体的渲染图。
你可以使用选项--out_folder设置保存渲染图的位置。
训练
单视图模型分两个阶段训练,首先不使用LPIPS(大部分训练),然后用LPIPS微调。
- 第一阶段使用以下命令运行:
其中$dataset_name是[cars,chairs,hydrants,teddybears,nmr,objaverse]之一。 完成后,将输出目录路径放在configs/experiment/lpips_$experiment_name.yaml中的python train_network.py +dataset=$dataset_nameopt.pretrained_ckpt选项中(默认设置为null)。 - 使用以下命令运行第二阶段:
使用哪个python train_network.py +dataset=$dataset_name +experiment=$lpips_experiment_name$lpips_experiment_name取决于数据集。 如果$dataset_name是[cars,hydrants,teddybears]中的一个,使用lpips_100k.yaml。 如果$dataset_name是chairs,使用lpips_200k.yaml。 如果$dataset_name是nmr,使用lpips_nmr.yaml。 如果$dataset_name是objaverse,使用lpips_objaverse.yaml。 记得在启动第二阶段之前,将第一阶段模型的目录放在适当的.yaml文件中。
要训练2视图模型,运行:
python train_network.py +dataset=cars cam_embd=pose_pos data.input_images=2 opt.imgs_per_obj=5
代码结构
训练循环在train_network.py中实现,评估代码在eval.py中。数据集在datasets/srn.py和datasets/co3d.py中实现。模型在scene/gaussian_predictor.py中实现。渲染器的调用可以在gaussian_renderer/__init__.py中找到。
相机约定
高斯光栅化器假设刚体变换矩阵是行主序,即位置向量是行向量。它还要求相机采用COLMAP / OpenCV约定,即x指向右,y指向下,z指向远离相机(前方)。
BibTeX
@inproceedings{szymanowicz24splatter,
title={Splatter Image: Ultra-Fast Single-View 3D Reconstruction},
author={Stanislaw Szymanowicz and Christian Rupprecht and Andrea Vedaldi},
year={2024},
booktitle={The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
}
致谢
S. Szymanowicz得到EPSRC博士培训合作奖学金(DTP) EP/R513295/1和Oxford-Ashton奖学金的支持。 A. Vedaldi得到ERC-CoG UNION 101001212的支持。 我们感谢Eldar Insafutdinov在安装要求方面的帮助。











