
 访问官网
访问官网 Github
Github 论文
论文PnPInversion
本仓库包含了ICLR2024论文"PnP Inversion: 仅需3行代码即可提升基于扩散模型的图像编辑"的实现
关键词:扩散模型、图像反演、图像编辑
Xuan Ju12, Ailing Zeng2*, Yuxuan Bian1, Shaoteng Liu1, Qiang Xu1*
1香港中文大学 2国际数字经济研究院 *通讯作者
项目主页 | Arxiv | Readpaper | 基准测试 | 代码 | 视频 |
📖 目录
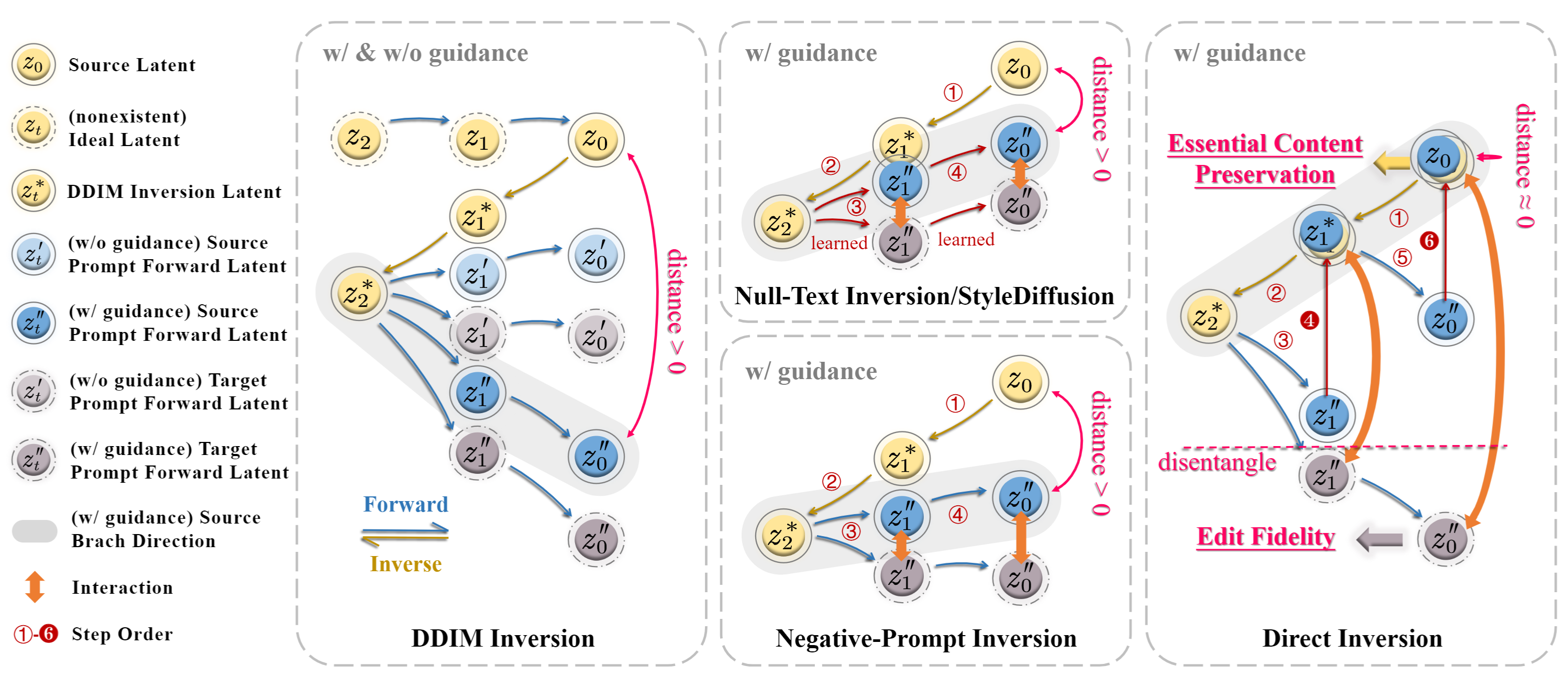
🛠️ 方法概述
文本引导的扩散模型彻底改变了图像生成和编辑,提供了卓越的真实感和多样性。具体来说,在基于扩散的编辑背景下,常见做法是从源图像和目标编辑提示开始。它涉及使用扩散模型获取与源图像对应的噪声潜在向量,然后将其提供给单独的源和目标扩散分支进行编辑。这个反演过程的准确性显著影响最终的编辑结果,影响源图像的基本内容保留和根据目标提示的编辑保真度。
先前的反演技术试图在源和目标扩散分支中找到统一的解决方案。然而,理论和实证分析表明,实际上,两个分支的解耦导致基本内容保留和编辑保真度责任的明确分离,从而在两个方面都取得更好的结果。在本文中,我们引入了一种名为"PnP反演"的新技术,它仅用三行代码直接纠正源扩散分支中的反演偏差,同时保持目标扩散分支不变。为了系统地评估图像编辑性能,我们提出了PIE-Bench,这是一个编辑基准,包含700张具有多样场景和编辑类型的图像,并配有多样化的注释。我们的评估指标着重于可编辑性和结构/背景保留,展示了PnP反演在八种编辑方法中相比五种反演技术的卓越编辑性能和推理速度。

🚀 入门指南
环境要求 🌍
这很重要!!!由于不同的模型有不同的Python环境要求(例如diffusers的版本),我们将环境列在"environment"文件夹中,详细如下:
- p2p_requirements.txt:用于
run_editing_p2p.py、run_editing_blended_latent_diffusion.py、run_editing_stylediffusion.py和run_editing_edit_friendly_p2p.py中的模型 - instructdiffusion_requirements.txt:用于
run_editing_instructdiffusion.py和run_editing_instructpix2pix.py中的模型 - masactrl_requirements.txt:用于
run_editing_masactrl.py中的模型 - pnp_requirements.txt:用于
run_editing_pnp.py中的模型 - pix2pix_zero_requirements.txt:用于
run_editing_pix2pix_zero.py中的模型 - edict_requirements.txt:用于
run_editing_edict.py中的模型
例如,如果你想使用run_editing_p2p.py中的模型,你需要按以下方式安装环境:
conda create -n p2p python=3.9 -y
conda activate p2p
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
pip install -r environment/p2p_requirements.txt
基准测试数据集下载 ⬇️
你可以在这里下载基准测试数据集PIE-Bench(提示驱动的图像编辑基准)。数据结构应该如下:
|-- data
|-- annotation_images
|-- 0_random_140
|-- 000000000000.jpg
|-- 000000000001.jpg
|-- ...
|-- 1_change_object_80
|-- 1_artificial
|-- 1_animal
|-- 111000000000.jpg
|-- 111000000001.jpg
|-- ...
|-- 2_human
|-- 3_indoor
|-- 4_outdoor
|-- 2_natural
|-- ...
|-- ...
|-- mapping_file_ti2i_benchmark.json # TI2I基准测试的映射文件,包含编辑文本
|-- mapping_file.json # PIE-Bench的映射文件,包含编辑文本、混合词和掩码注释
PIE-Bench基准测试:
包含700张图像,有10种编辑类型。"annotation images"文件夹中的文件夹名称表示编辑类型。[展开查看详情]
| 文件夹名称 | 编辑类型 | 说明 |
|---|---|---|
| 0_random_140 | 0. 随机编辑 | 由志愿者撰写或来自之前研究的示例的随机提示。共140张图像。 |
| 1_change_object_80 | 1. 更改对象 | 将一个对象更改为另一个,例如将点变成猫。共80张图像。 |
| 2_add_object_80 | 2. 添加对象 | 添加一个对象,例如添加花朵。共80张图像。 |
| 3_delete_object_80 | 3. 删除对象 | 删除一个对象,例如删除图像中的云朵。共80张图像。 |
| 4_change_attribute_content_40 | 4. 更改某物的内容 | 更改某物的内容,例如通过编辑面部表情将微笑的人变成生气的人。共40张图像。 |
| 5_change_attribute_pose_40 | 5. 更改某物的姿势 | 更改某物的姿势,例如将站立的狗变成奔跑的狗。共40张图像。 |
| 6_change_attribute_color_40 | 6. 更改某物的颜色 | 更改某物的颜色,例如将红心变成粉红心。共40张图像。 |
| 7_change_attribute_material_40 | 7. 更改某物的材质 | 更改某物的材质,例如将木桌变成玻璃桌。共40张图像。 |
| 8_change_background_80 | 8. 更改图像背景 | 更改图像背景,例如将白色背景变成草地。共80张图像。 |
| 9_change_style_80 | 9. 更改图像风格 | 更改图像风格,例如将照片变成水彩画。共80张图像。 |
在编辑类型1-9中,我们将图像平均分配给人工图像和自然图像*(注意这两类都是真实图像,人工图像是绘画或其他人为生成的图像,自然图像是照片)*。在这两个类别中,图像又平均分配给动物、人物、室内场景和室外场景。
"mapping_file_ti2i_benchmark.json"包含PIE-Bench的编辑文本、混合词和掩码注释。[展开查看详情]
mapping_file_ti2i_benchmark.json包含一个具有以下结构的字典:
{
"000000000000": {
"image_path": "0_random_140/000000000000.jpg", # 图像路径
"original_prompt": "路上倾斜的山地自行车,前面是一栋建筑", # 原始图像的提示,[]显示与editing_prompt的区别
"editing_prompt": "路上倾斜的[生锈的]山地自行车,前面是一栋建筑", # 编辑后图像的提示,[]显示与original_prompt的区别
"editing_instruction": "使自行车车架生锈", # 图像编辑指令
"editing_type_id": "0", # 图像编辑类型
"blended_word": "自行车 自行车", # 需要编辑的词
"mask": [...] # 使用RLE编码的掩码,需要编辑的部分为1,否则为0。
},
...
}
TI2I基准测试:
我们还在数据中添加了TI2I基准测试以便使用。TI2I基准测试包含55张图像,每张图像都有编辑后的图像提示。 图像位于data/annotation_images/ti2i_benchmark,映射文件位于data/mapping_file_ti2i_benchmark.json。
🏃🏼 运行脚本
推理 📜
运行基准测试
您可以通过run_editing_p2p.py、run_editing_edit_friendly_p2p.py、run_editing_masactrl.py、run_editing_pnp.py、run_editing_edict.py、run_editing_pix2pix_zero.py、run_editing_instructdiffusion.py、run_editing_blended_latent_diffusion.py、run_editing_stylediffusion.py和run_editing_instructpix2pix.py运行整个图像编辑结果。这些Python文件包含以下模型(请展开):
run_editing_p2p.py
| 反转方法 | 编辑方法 | 索引 | 说明 | :-----: | :----: | :----: | :----: | | DDIM | 提示词到提示词 | ddim+p2p | | | 空文本反转 | 提示词到提示词 | null-text-inversion+p2p | | | 负面提示词反转 | 提示词到提示词 | negative-prompt-inversion+p2p | | | 直接反转(本文方法) | 提示词到提示词 | directinversion+p2p | | | 直接反转(本文方法)(消融:使用不同的引导尺度) | 提示词到提示词(消融:使用不同的引导尺度) | directinversion+p2p_guidance_{i}_{f} | 用于消融研究。{i}表示反转引导尺度,{f}表示前向引导尺度。{i}可从[0,1,25,5,75]中选择。{f}可从[1,25,5,75]中选择。例如,directinversion+p2p_guidance_1_75表示反转时引导尺度为1.0,前向时为7.5。 | | 空文本反转 | 近端引导 | null-text-inversion+proximal-guidance | | | 负面提示词反转 | 近端引导 | negative-prompt-inversion+proximal-guidance | | | 空潜在空间反转 | 提示词到提示词 | ablation_null-latent-inversion+p2p | 用于消融研究。将空文本反转改为空潜在空间反转。 | | 空文本反转(消融:单分支) | 提示词到提示词 | ablation_null-text-inversion_single_branch+p2p | 用于消融研究。编辑空文本反转,仅在源分支交换空嵌入。 | | 直接反转(本文方法)(消融:按比例添加) | 提示词到提示词(消融:按比例添加) | ablation_directinversion_{s}+p2p | 用于消融研究。{s}表示添加的比例。{s}可从[04,08]中选择。例如,ablation_directinversion_02+p2p表示按0.2的比例添加。 | | 直接反转(本文方法)(消融:跳过步骤) | 提示词到提示词(消融:跳过步骤) | ablation_directinversion_interval_{s}+p2p | 用于消融研究。{s}表示跳过的步骤数。{s}可从[2,5,10,24,49]中选择。例如,ablation_directinversion_interval_2+p2p表示每2步跳过一次。 | | 直接反转(本文方法)(消融:为目标潜在变量添加源偏移) | 提示词到提示词(消融:为目标潜在变量添加源偏移) | ablation_directinversion_add-source+p2p | | | 直接反转(本文方法)(消融:为目标潜在变量添加目标偏移) | 提示词到提示词(消融:为目标潜在变量添加目标偏移) | ablation_directinversion_add-target+p2p | || 反转方法 | 编辑方法 | 索引 | 说明 |
|---|---|---|---|
| 风格扩散 | 提示词到提示词 | stylediffusion+p2p |
| 反转方法 | 编辑方法 | 索引 | 说明 |
|---|---|---|---|
| 易编辑反转 | 提示词到提示词 | edit-friendly-inversion+p2p |
| 反转方法 | 编辑方法 | 索引 | 说明 |
|---|---|---|---|
| DDIM | MasaCtrl | ddim+masactrl | |
| 直接反转(本文方法) | MasaCtrl | directinversion+masactrl |
| 反转方法 | 编辑方法 | 索引 | 说明 |
|---|---|---|---|
| DDIM | 即插即用 | ddim+pnp | |
| 直接反转(本文方法) | 即插即用 | directinversion+pnp |
| 反转方法 | 编辑方法 | 索引 | 说明 |
|---|---|---|---|
| DDIM | Pix2Pix-Zero | ddim+pix2pix-zero | |
| 直接反转(本文方法) | Pix2Pix-Zero | directinversion+pix2pix-zero |
| 反转方法 | 编辑方法 | 索引 | 说明 |
|---|---|---|---|
| EDICT | edict+direct_forward |
| 反转方法 | 编辑方法 | 索引 | 说明 |
|---|---|---|---|
| 指令扩散 | instruct-diffusion |
| 反转方法 | 编辑方法 | 索引 | 说明 |
|---|---|---|---|
| 指令Pix2Pix | instruct-pix2pix |
| 反转方法 | 编辑方法 | 索引 | 说明 |
|---|---|---|---|
| 混合潜在扩散 | blended-latent-diffusion | ||
例如,如果你想运行DirectInversion(本方法) + Prompt-to-Prompt,你可以在run_editing_p2p.py中找到这个方法的索引directinversion+p2p。然后,你可以通过以下命令运行编辑类型0的DirectInversion(本方法) + Prompt-to-Prompt: |
python run_editing_p2p.py --output_path output --edit_category_list 0 --edit_method_list directinversion+p2p
你也可以运行多个编辑方法和多个编辑类型:
python run_editing_p2p.py --edit_category_list 0 1 2 3 4 5 6 7 8 9 --edit_method_list directinversion+p2p null-text+p2p
你还可以指定--rerun_exist_images来选择是否重新运行已存在的图像。你还可以指定--data_path和--output来设置图像路径和输出路径。
运行任意图像
你可以将自己的图像和编辑提示处理成与我们给出的基准相同的格式,以运行大量图像。你也可以编辑给定的Python文件以适用于你自己的图像。我们已经提供了run_editing_p2p.py的编辑版本run_editing_p2p_one_image.py。你可以通过以下命令运行单个图像的编辑:
python -u run_editing_p2p_one_image.py --image_path scripts/example_cake.jpg --original_prompt "一个圆形的橙色糖霜蛋糕放在木盘上" --editing_prompt "一个方形的橙色糖霜蛋糕放在木盘上" --blended_word "蛋糕 蛋糕" --output_path "directinversion+p2p.jpg" "ddim+p2p.jpg" --edit_method_list "directinversion+p2p" "ddim+p2p"
我们还提供了Jupyter notebook演示run_editing_p2p_one_image.ipynb。
请注意,我们在代码中使用了默认参数。然而,这并不适用于所有图像。你可能需要根据你的输入调整它们。
评估 📐
你可以通过以下命令运行评估:
python evaluation/evaluate.py --metrics "structure_distance" "psnr_unedit_part" "lpips_unedit_part" "mse_unedit_part" "ssim_unedit_part" "clip_similarity_source_image" "clip_similarity_target_image" "clip_similarity_target_image_edit_part" --result_path evaluation_result.csv --edit_category_list 0 1 2 3 4 5 6 7 8 9 --tgt_methods 1_ddim+p2p 1_directinversion+p2p
你可以在evaluation/evaluate.py中的"all_tgt_image_folders"字典中找到tgt_methods的选项。
所有编辑结果可以在这里下载。你可以下载它们并按以下文件结构放置,以重现我们论文中的所有结果。
output
|-- ddim+p2p
|-- annotation_images
|-- ...
|-- directinversion+p2p
|-- annotation_images
|-- ...
...
如果你想评估我们论文中显示的整个表格的结果,你可以运行:
python evaluation/evaluate.py --metrics "structure_distance" "psnr_unedit_part" "lpips_unedit_part" "mse_unedit_part" "ssim_unedit_part" "clip_similarity_source_image" "clip_similarity_target_image" "clip_similarity_target_image_edit_part" --result_path evaluation_result.csv --edit_category_list 0 1 2 3 4 5 6 7 8 9 --tgt_methods 1 --evaluate_whole_table
然后,表1中的所有结果将输出到evaluation_result.csv中。
🥇 定量结果
在各种编辑方法中将PnP Inversion与其他反演技术进行比较:
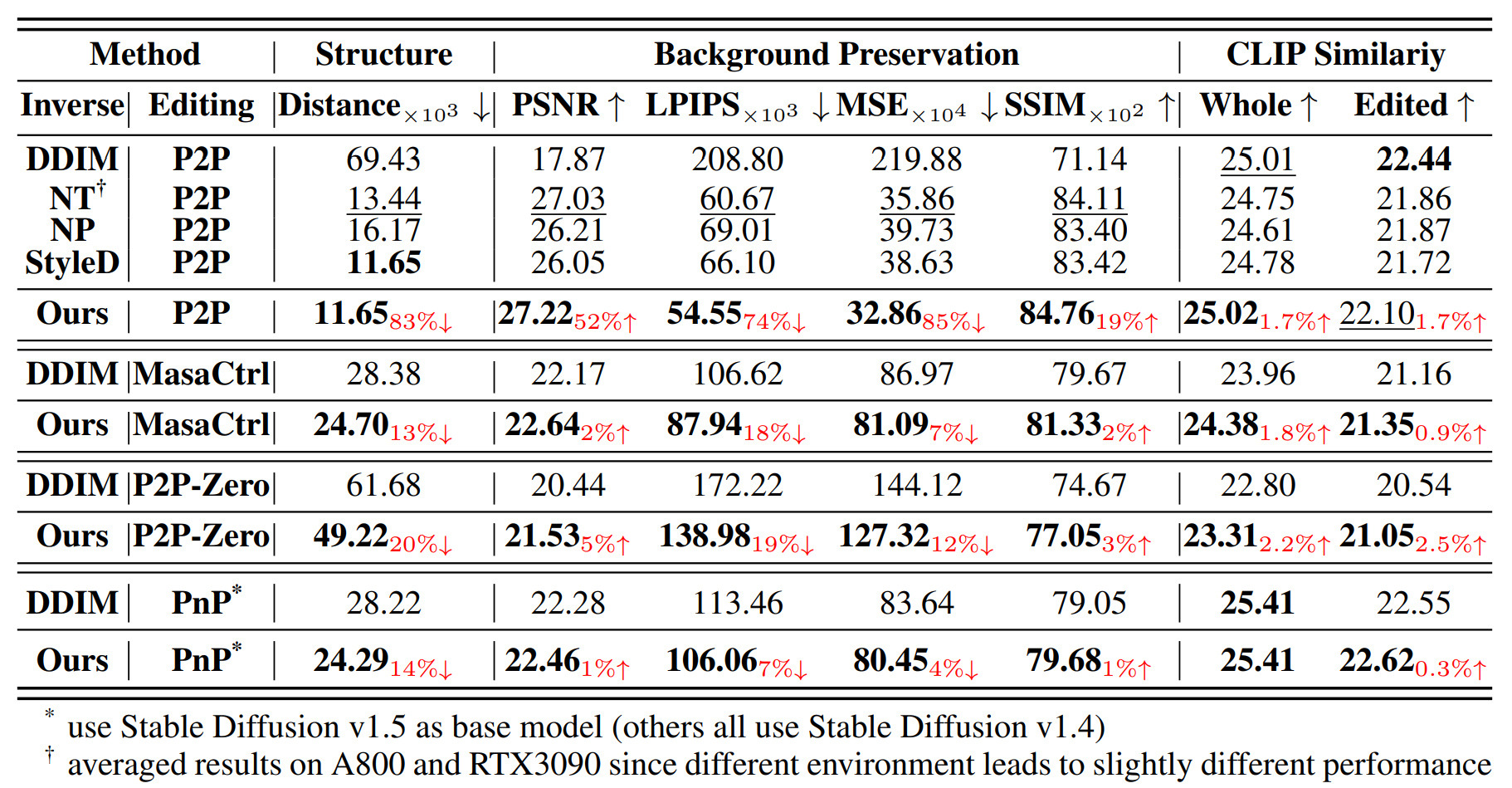
更多结果可以在主论文中找到。
🌟 定性结果
将PnP Inversion融入四种基于扩散的编辑方法的性能提升:

不同反演和编辑技术的可视化结果:

更多结果可以在主论文中找到。
🤝🏼 引用我们
@article{ju2023direct,
title={PnP Inversion: Boosting Diffusion-based Editing with 3 Lines of Code},
author={Ju, Xuan and Zeng, Ailing and Bian, Yuxuan and Liu, Shaoteng and Xu, Qiang},
journal={International Conference on Learning Representations ({ICLR})},
year={2024}
}
💖 致谢
我们的代码在prompt-to-prompt、StyleDiffusion、MasaCtrl、pix2pix-zero、Plug-and-Play、Edit Friendly DDPM Noise Space、Blended Latent Diffusion、Proximal Guidance和InstructPix2Pix的基础上进行了修改,感谢所有贡献者!











