
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文ReNoise:通过迭代噪声实现真实图像反演
Daniel Garibi, Or Patashnik, Andrey Voynov, Hadar Averbuch-Elor, Daniel Cohen-Or
文本引导扩散模型的最新进展已经解锁了强大的图像操作能力。然而,将这些方法应用于真实图像需要将图像反演到预训练扩散模型的域中。实现忠实的反演仍然是一个挑战,特别是对于最近训练的模型,这些模型使用少量去噪步骤生成图像。在这项工作中,我们提出了一种具有高质量操作比的反演方法,在不增加操作数的情况下提高重建精度。基于反转扩散采样过程,我们的方法在每个反演采样步骤中采用迭代重噪机制。该机制通过迭代应用预训练的扩散模型并平均这些预测,来改进前向扩散轨迹上预测点的近似。我们使用各种采样算法和模型(包括最新的加速扩散模型)评估了我们的ReNoise技术的性能。通过全面的评估和比较,我们展示了其在精度和速度方面的有效性。此外,我们通过展示对真实图像的文本驱动图像编辑,确认我们的方法保留了可编辑性。


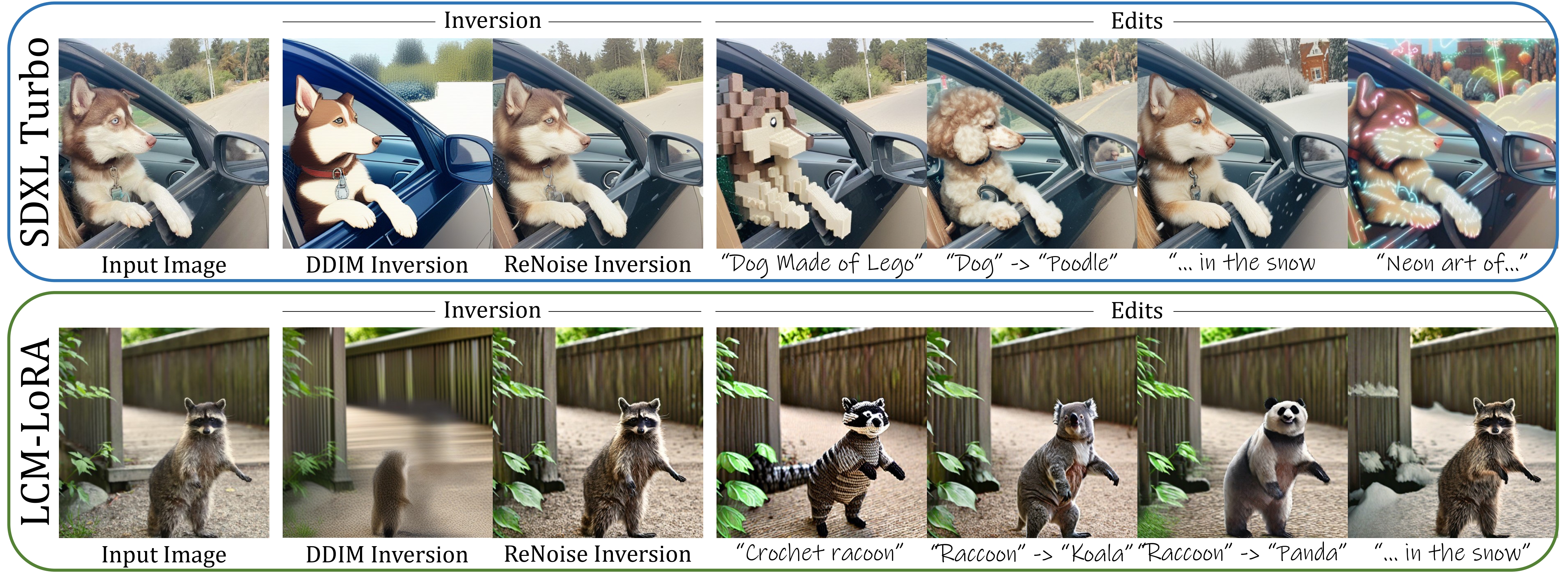
描述
我们ReNoise论文的官方实现。
环境设置
我们的代码基于diffusers库的要求构建。要设置环境,请运行:
conda env create -f environment.yaml
conda activate renoise_inversion
或安装要求:
pip install -r requirements.txt
演示
要运行项目的本地演示,请运行以下命令:
gradio gradio_app.py
使用方法
在examples/目录中有三个如何在Stable Diffusion、SDXL和SDXL Turbo中使用反演的示例。
反演
我们创建了一个diffusers管道来执行反演。您可以使用以下代码在项目中使用ReNoise:
from src.eunms import Model_Type, Scheduler_Type
from src.utils.enums_utils import get_pipes
from src.config import RunConfig
from main import run as invert
model_type = Model_Type.SDXL_Turbo
scheduler_type = Scheduler_Type.EULER
pipe_inversion, pipe_inference = get_pipes(model_type, scheduler_type, device=device)
input_image = Image.open("example_images/lion.jpeg").convert("RGB").resize((512, 512))
prompt = "a lion in the field"
config = RunConfig(model_type = model_type,
scheduler_type = scheduler_type)
rec_img, inv_latent, noise, all_latents = invert(input_image,
prompt,
config,
pipe_inversion=pipe_inversion,
pipe_inference=pipe_inference,
do_reconstruction=False)
您可以使用RunConfig中的以下属性控制反演参数:
num_inference_steps- 去噪步骤数。num_inversion_steps- 反演步骤数。guidance_scale- 反演过程中的引导比例。num_renoise_steps- ReNoise步骤数。max_num_renoise_steps_first_step- 当T<250时的最大ReNoise步骤数。inversion_max_step- 反演强度。去噪步骤的数量取决于最初添加的噪声量。当强度为1.0时,图像将被反演为完全噪声,去噪过程将运行完整的步骤数。当强度为0.5时,图像将被反演为半噪声,去噪过程将运行一半的步骤。num_inference_steps- 去噪步骤数average_latent_estimations- 执行估计平均。average_first_step_range- 当T<250时的平均范围。值是一个元组,例如(0, 5)。average_first_step_range- 当T>250时的平均范围。值是一个元组,例如(8, 10)。noise_regularization_lambda_ac- 噪声正则化成对lambda。noise_regularization_lambda_kl- 噪声正则化补丁KL散度lambda。perform_noise_correction- 执行噪声校正。
对于随机采样器,添加以下内容以使用与反演过程相同的\epsilon_t。
pipe_inference.scheduler.set_noise_list(noise)
编辑
要使用ReNoise编辑图像,您可以使用以下代码:
from src.eunms import Model_Type, Scheduler_Type
from src.utils.enums_utils import get_pipes
from src.config import RunConfig
from main import run as invert
model_type = Model_Type.SDXL_Turbo
scheduler_type = Scheduler_Type.EULER
pipe_inversion, pipe_inference = get_pipes(model_type, scheduler_type, device=device)
input_image = Image.open("example_images/lion.jpeg").convert("RGB").resize((512, 512))
prompt = "a lion in the field"
config = RunConfig(model_type = model_type,
scheduler_type = scheduler_type)
edit_img, inv_latent, noise, all_latents = invert(input_image,
prompt,
config,
pipe_inversion=pipe_inversion,
pipe_inference=pipe_inference,
do_reconstruction=True,
edit_prompt="a tiger in the field"
)
edit_img.save("result.png")
致谢
这段代码基于diffusers库的代码构建。此外,我们借鉴了以下仓库的代码:
- Pix2PixZero用于噪声正则化。
- sdxl_inversions用于SDXL中DDIM反演的初始实现。
引用
如果您在研究中使用此代码,请引用以下工作:
@misc{garibi2024renoise,
title={ReNoise: Real Image Inversion Through Iterative Noising},
author={Daniel Garibi and Or Patashnik and Andrey Voynov and Hadar Averbuch-Elor and Daniel Cohen-Or},
year={2024},
eprint={2403.14602},
archivePrefix={arXiv},
primaryClass={cs.CV}
}











