
 访问官网
访问官网 Github
GithubPython音频加载基准测试
本仓库旨在评估从Python接口调用的各种音频I/O包的加载性能。
这对于当今经常处理原始(时域)音频并即时组装批次的机器学习模型来说很重要。因此,尽可能快速地加载音频变得至关重要。同时,理想情况下,一个库应该支持各种未压缩和压缩的音频格式,并且能够只加载音频的部分内容(定位)。后者对于那些无法轻松处理可变长度样本的模型(如卷积网络)尤为重要。
测试的库
| 库 | 版本 | 简称/代码 | 输出类型 | 支持的编解码器 | 摘录/定位 |
|---|---|---|---|---|---|
| scipy.io.wavfile | 1.9.3 | scipy | Numpy | PCM(仅16位) | ❌ |
| scipy.io.wavfile memmap | 1.9.3 | scipy_mmap | Numpy | PCM(仅16位) | ✅ |
| soundfile (libsndfile) | 0.12.1 | soundfile | Numpy | PCM, Ogg, Flac, MP3 | ✅ |
| pydub | 0.25.1 | pydub | Python数组 | PCM, MP3, OGG或其他FFMPEG/libav支持的编解码器 | ❌ |
| aubio | 0.4.9 | aubio | Numpy数组 | PCM, MP3, OGG或其他avconv支持的编码 | ✅ |
| audioread (FFMPEG) | 2.1.9 | ar_ffmpeg | Numpy数组 | FFMPEG支持的所有格式 | ❌ |
| librosa | 0.10.0 | librosa | Numpy数组 | soundfile支持的所有格式 | ✅ |
tensorflow tf.io.audio.decode_wav | 2.11.0 | tf_decode_wav | Tensorflow张量 | PCM(仅16位) | ❌ |
tensorflow-io from_audio | 0.30.0 | tfio_fromaudio | Tensorflow张量 | PCM, Ogg, Flac | ✅ |
| torchaudio (sox_io) | 0.13.1 | torchaudio | PyTorch张量 | Sox支持的所有编解码器 | ✅ |
| torchaudio (soundfile) | 0.13.1 | torchaudio | PyTorch张量 | Soundfile支持的所有编解码器 | ✅ |
| soxbindings | 0.9.0 | soxbindings | Numpy张量 | Soundfile支持的所有编解码器 | ✅ |
| stempeg | 0.2.3 | stempeg | Numpy张量 | FFMPEG支持的所有编解码器 | ✅ |
未包含的库
- audioread (coreaudio):仅在macOS上可用。
- audioread (gstreamer):安装过于困难。
- madmom:与
ar_ffmpeg使用相同的ffmpeg接口。 - pymad:仅支持MP3,且速度很慢。
- python内置
wave:编解码器支持过于有限。
结果
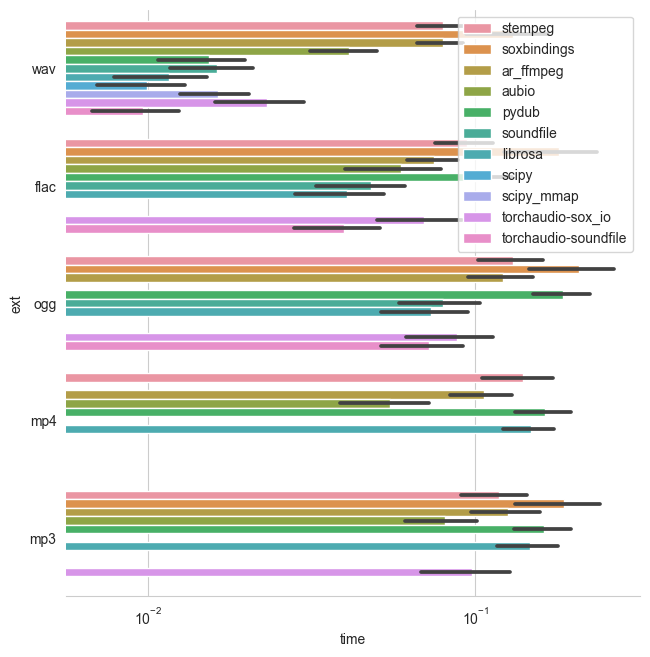
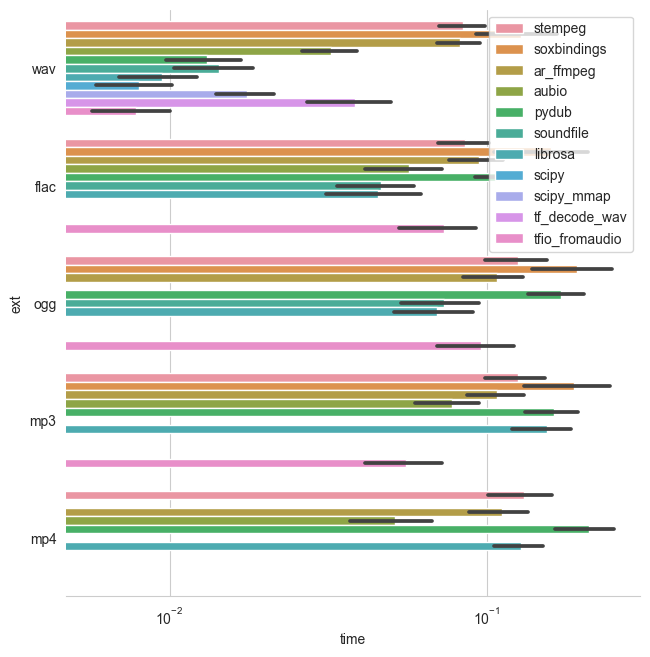
基准测试加载了不同长度(1到151秒之间)的多个(单声道)音频文件,并测量了将音频转换为张量所需的时间。根据目标张量类型(numpy、pytorch或tensorflow),比较了不同数量的库。例如,当输出类型为numpy且目标张量类型为tensorflow时,加载时间包括了转换为目标张量的操作。此外,数据加载器的多进程功能被禁用。因此,特别是对于深度学习应用,加载速度并不一定代表批次加载速度。
以下显示的所有结果都以秒**为单位表示加载时间。
加载到Numpy张量

加载到PyTorch张量
加载到Tensorflow张量
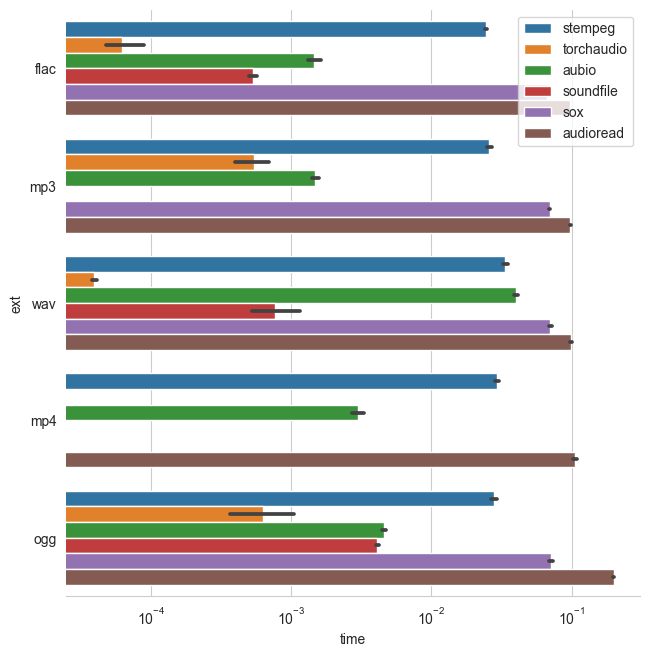
获取元数据信息
除了加载文件外,还可能需要提取元数据。为了对此进行基准测试,我们要求每个文件提供_采样率_、声道数、_样本数_和_持续时间_的元数据。这些都是连续调用的,这意味着不允许一次性打开文件并提取所有元数据。请注意,我们已经从元数据的基准测试结果中排除了pydub,因为它明显比其他工具慢得多。
运行基准测试
生成样本数据
为了测试加载速度,我们生成不同时长的随机(噪声)音频数据,并将其编码为PCM 16位WAV、MP3 CBR或MP4格式。
数据是通过使用shell脚本生成的。要在AUDIO文件夹中生成数据,请运行
generate_audio.sh
使用Docker设置
使用以下命令构建Docker容器
docker build -t audio_benchmark .
它会安装所有音频库所需的所有包依赖。
之后,将数据目录挂载到Docker容器中,并在容器内运行run.sh,例如:
docker run -v /home/user/repos/python_audio_loading_benchmark/:/app \
-it audio_benchmark:latest /bin/bash run.sh
在虚拟环境中设置
创建虚拟环境,安装必要的依赖项并运行基准测试:
virtualenv --python=/usr/bin/python3 --no-site-packages _env
source _env/bin/activate
pip install -r requirements.txt
pip install git+https://github.com/pytorch/audio.git
进行基准测试
运行基准测试:
bash run.sh
并使用以下命令绘制结果:
python plot.py
这将在results文件夹中生成PNG文件。
数据是通过使用shell脚本生成的。要在AUDIO文件夹中生成数据,请运行generate_audio.sh。
作者
@faroit, @hagenw
贡献
我们鼓励感兴趣的用户通过问题区和拉取请求为这个仓库做出贡献。特别感兴趣的是有关新工具和现有包新版本的通知。由于基准测试具有主观性,我(@faroit)将在我们的服务器上重新运行基准测试。











