
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文InstanceDiffusion:图像生成的实例级控制
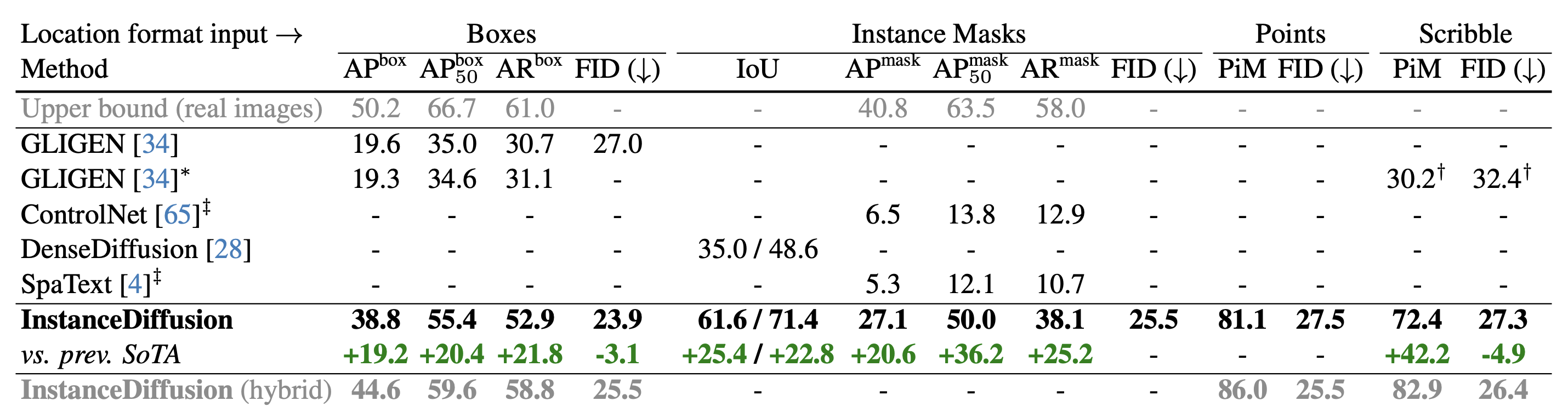
我们推出了InstanceDiffusion,为文本到图像的扩散模型增加了精确的实例级控制。InstanceDiffusion支持每个实例的自由语言条件,并允许灵活的方式来指定实例位置,如简单的单点、涂鸦、边界框或复杂的实例分割掩码,以及它们的组合。 与之前的最先进技术相比,InstanceDiffusion在框输入上实现了2.0倍更高的AP50,在掩码输入上实现了1.7倍更高的IoU。

InstanceDiffusion: 图像生成的实例级控制
Xudong Wang、Trevor Darrell、Saketh Rambhatla、 Rohit Girdhar、Ishan Misra
Meta GenAI;加州大学伯克利分校BAIR
CVPR 2024
免责声明
本代码库代表了第一作者在加州大学伯克利分校期间对InstanceDiffusion的重新实现。与原论文报告的结果可能存在轻微的性能差异。本代码库的目标是复现原论文的发现和见解,主要用于学术和研究目的。
更新
- 2024年2月25日 - InstanceDiffusion已移植到ComfyUI。查看一些很酷的视频演示!(感谢Tucker Darby)
- 2024年2月21日 - 支持快速注意力,内存使用可以减少一半以上。
- 2024年2月19日 - 增加基于涂鸦/点的图像生成的PiM评估
- 2024年2月10日 - 增加属性绑定的模型评估
- 2024年2月9日 - 使用MSCOCO数据集增加模型评估
- 2024年2月5日 - 初始提交。敬请期待
安装
要求
- Linux或macOS,Python ≥ 3.8
- PyTorch ≥ 2.0和匹配的torchvision。 请在pytorch.org一起安装它们以确保兼容性。
- OpenCV ≥ 4.6,用于演示和可视化。
Conda环境设置
conda create --name instdiff python=3.8 -y
conda activate instdiff
pip install -r requirements.txt
训练数据生成
方法概述
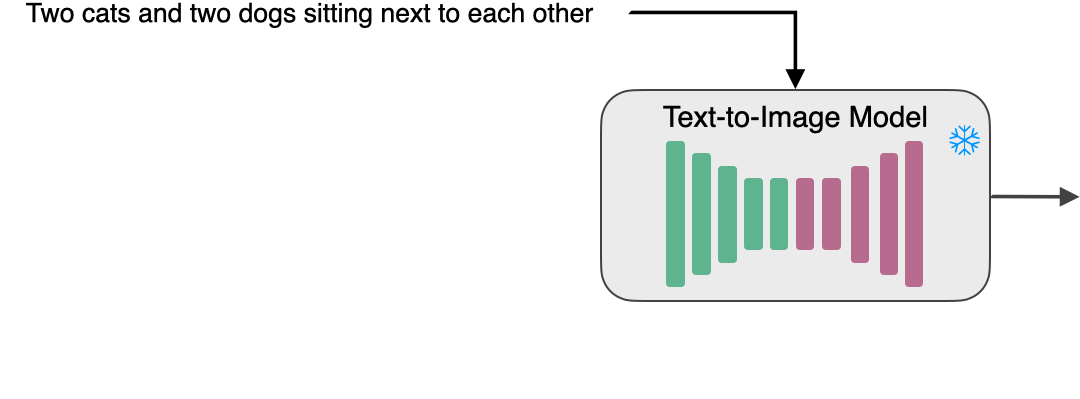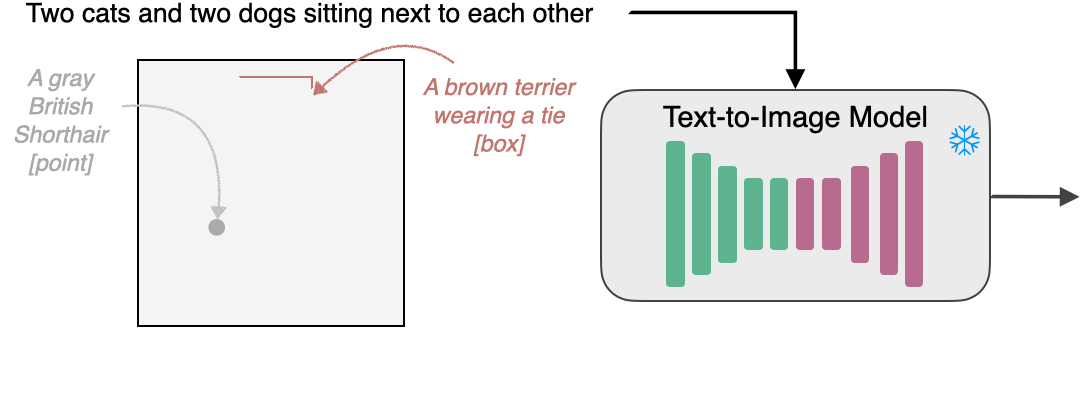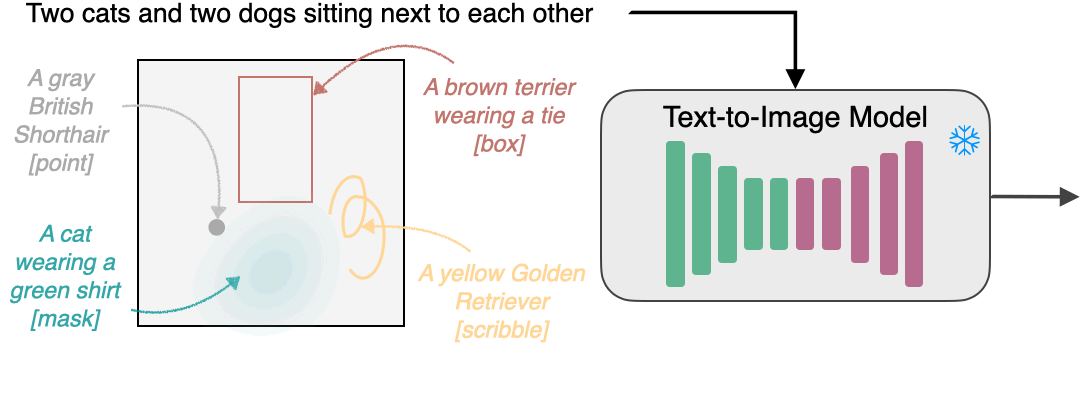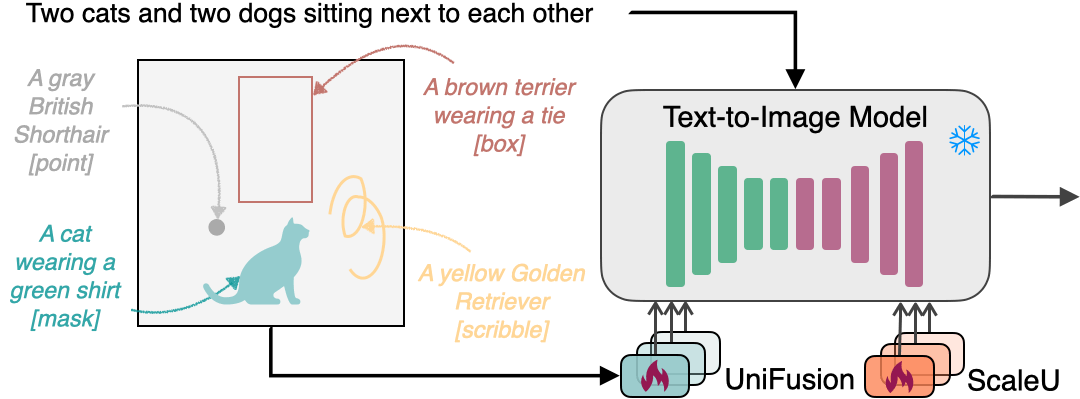
InstanceDiffusion通过提供额外的实例级控制来增强文本到图像模型。除了全局文本提示外,InstanceDiffusion还允许在生成图像时指定成对的实例级提示及其位置(如点、框、涂鸦或实例掩码)。 我们添加了我们提出的可学习的UniFusion模块来处理额外的每个实例的条件。UniFusion将实例条件与骨干网络融合,并调制其特征以实现实例条件下的图像生成。此外,我们提出了ScaleU模块,通过重新缩放UNet中产生的跳跃连接和骨干特征图来提高UNet尊重实例条件的能力。在推理时,我们提出了多实例采样器,可以减少多个实例之间的信息泄漏。
InstanceDiffusion推理演示
如果你想在本地运行InstanceDiffusion演示,我们提供了inference.py。请从Hugging Face或Google Drive下载预训练的InstanceDiffusion模型和SD1.5,将它们放在pretrained文件夹下,然后运行:
python inference.py \
--num_images 8 \
--output OUTPUT/ \
--input_json demos/demo_cat_dog_robin.json \
--ckpt pretrained/instancediffusion_sd15.pth \
--test_config configs/test_box.yaml \
--guidance_scale 7.5 \
--alpha 0.8 \
--seed 0 \
--mis 0.36 \
--cascade_strength 0.4 \
JSON文件input_json指定了生成图像的文本提示和位置条件,demos目录下有几个演示JSON文件可用。
num_images参数表示要生成多少张图像。
mis设置调整了使用多实例采样器的时间步比例,建议低于0.4。较高的mis值可以减少实例之间的信息泄漏并提高图像质量,但可能会减慢生成过程。
调整alpha会修改使用实例级条件的时间步分数,较高的alpha确保更好地遵守位置条件,但可能以图像质量为代价,这是一个权衡。
如果cascade_strength大于0,则会激活SDXL细化器。注意:论文中的定量评估没有使用SDXL细化器,但我们最近发现它可以提高图像生成质量。
我们的实现支持Flash/Math/MemEfficient注意力,利用PyTorch的torch.backends.cuda.sdp_kernel。要禁用它,只需在配置.yaml文件中设置efficient_attention: False。
边界框应遵循[xmin, ymin, width, height]格式。掩码应为RLE(游程编码)格式。涂鸦应指定为[x1, y1,..., x20, y20],可以有重复点,点用[x, y]表示。
让每个人都转头吧!
InstanceDiffusion支持从整个实例到部件和子部件的图像组合。部件/子部件的定位可以隐式改变物体的整体姿态。
python inference.py \
--num_images 8 \
--output OUTPUT/ \
--input_json demos/eagle_left.json \
--ckpt pretrained/instancediffusion_sd15.pth \
--test_config configs/test_box.yaml \
--guidance_scale 7.5 \
--alpha 0.8 \
--seed 0 \
--mis 0.2 \
--cascade_strength 0.4 \
使用单点生成图像
InstanceDiffusion支持使用点(每个实例一个点)和相应的实例标题生成图像。

python inference.py \
--num_images 8 \
--output OUTPUT/ \
--input_json demos/demo_corgi_kitchen.json \
--ckpt pretrained/instancediffusion_sd15.pth \
--test_config configs/test_point.yaml \
--guidance_scale 7.5 \
--alpha 0.8 \
--seed 0 \
--mis 0.2 \
--cascade_strength 0.4 \
迭代图像生成
InstanceDiffusion还可以支持迭代图像生成,对预生成的实例和整体场景进行最小化更改。使用相同的初始噪声和图像标题,InstanceDiffusion可以通过修改边界框来选择性地引入新实例、用一个实例替换另一个、重新定位实例或调整实例的大小。
python inference.py \
--num_images 8 \
--output OUTPUT/ \
--input_json demos/demo_iterative_r1.json \
--ckpt pretrained/instancediffusion_sd15.pth \
--test_config configs/test_box.yaml \
--guidance_scale 7.5 \
--alpha 0.8 \
--seed 0 \
--mis 0.2 \
--cascade_strength 0.4 \
--input_json可以设置为demo_iterative_r{k+1}.json以生成后续轮次的图像。
MSCOCO上的模型定量评估(零样本)
我们的模型从未在MSCOCO的图像上训练过,我们在MSCOCO上进行零样本评估以展示InstanceDiffusion的泛化能力。
位置条件(点、涂鸦、框和实例掩码)
下载MSCOCO 2017数据集并将其存储在datasets文件夹中,确保数据组织如下:
coco/
annotations/
instances_val2017.json
images/
val2017/
000000000139.jpg
000000000285.jpg
...
请下载定制的instances_val2017.json,它将所有图像调整为512x512并相应调整掩码/框。组织好数据后,执行以下命令:
CUDA_VISIBLE_DEVICES=0 python eval_local.py \
--job_index 0 \
--num_jobs 1 \
--use_captions \
--save_dir "eval-cocoval17" \
--ckpt_path pretrained/instancediffusion_sd15.pth \
--test_config configs/test_mask.yaml \
--test_dataset cocoval17 \
--mis 0.36 \
--alpha 1.0
pip install ultralytics
mv datasets/coco/images/val2017 datasets/coco/images/val2017-official
ln -s generation_samples/eval-cocoval17 datasets/coco/images/val2017
yolo val segment model=yolov8m-seg.pt data=coco.yaml device=0
我们将所有样本均匀分配到--num_jobs个分割中,每个作业(GPU)负责生成验证数据集的一部分。--job_index参数指定每个单独作业的作业索引。
属性绑定
test_attribute="colors" # colors, textures
CUDA_VISIBLE_DEVICES=0 python eval_local.py \
--job_index 0 \
--num_jobs 1 \
--use_captions \
--save_dir "eval-cocoval17-colors" \
--ckpt_path pretrained/instancediffusion_sd15.pth \
--test_config configs/test_mask.yaml \
--test_dataset cocoval17 \
--mis 0.36 \
--alpha 1.0
--add_random_${test_attribute}
# 评估实例级CLIP分数和属性绑定性能
python eval/eval_attribute_binding.py --folder eval-cocoval17-colors --test_random_colors
要评估InstanceDiffusion在纹理属性绑定方面的性能,将test_attribute设置为textures,并将--test_random_colors替换为--test_random_textures。
基于涂鸦/点的图像生成的PiM评估
python eval_local.py \
--job_index 0 \
--num_jobs 1 \
--use_captions \
--save_dir "eval-cocoval17-point" \
--ckpt_path pretrained/instancediffusion_sd15.pth \
--test_config configs/test_point.yaml \
--test_dataset cocoval17 \
--mis 0.36 \
--alpha 1.0
pip install ultralytics
mv datasets/coco/images/val2017 datasets/coco/images/val2017-official
ln -s generation_samples/eval-cocoval17-point datasets/coco/images/val2017
yolo val segment model=yolov8m-seg.pt data=coco.yaml device=0
# 请指明上一步生成的predictions.json文件的路径
python eval/eval_pim.py --pred_json /path/to/predictions.json
要评估基于涂鸦的图像生成的PiM,在执行python eval_local.py时将--test_config更改为configs/test_scribble.yaml。此外,运行python eval/eval_pim.py时需要包含--test_scribble。
我们将所有样本平均分配到--num_jobs个分割中,每个作业(GPU)负责生成验证数据集的一部分。--job_index参数指定每个单独作业的索引。
InstanceDiffusion模型训练
要使用submitit训练InstanceDiffusion,首先按照INSTALL中的说明设置conda环境。然后,按照此链接中的指南准备训练数据。接下来,将SD1.5下载到pretrained文件夹。最后,运行以下命令:
run_name="instancediffusion"
python run_with_submitit.py \
--workers 8 \
--ngpus 8 \
--nodes 8 \
--batch_size 8 \
--base_learning_rate 0.00005 \
--timeout 20000 \
--warmup_steps 5000 \
--partition learn \
--name=${run_name} \
--wandb_name ${run_name} \
--yaml_file="configs/train_sd15.yaml" \
--official_ckpt_name='pretrained/v1-5-pruned-emaonly.ckpt' \
--train_file="train.txt" \
--random_blip 0.5 \
--count_dup true \
--add_inst_cap_2_global false \
--enable_ema true \
--re_init_opt true \
更多选项,请参见python run_with_submitit.py -h。
第三方实现
ComfyUI-InstanceDiffusion:Tucker Darby帮助将InstanceDiffusion移植到ComfyUI。以下是Tucker创建的几个视频演示(视频使用ComfyUI工作流制作,该工作流使用AnimateDiff和AnimateLCM作为一致性方法):
| 演示1 | 演示2 |
|---|---|
许可和致谢
InstanceDiffusion的大部分内容均遵循Apache许可,但项目的某些部分受单独的许可条款约束:CLIP、BLIP、Stable Diffusion和GLIGEN均遵循其各自的许可;如果您之后添加其他第三方代码,请保持此许可信息更新,如果该组件使用的许可不是Apache、CC-BY-NC、MIT或CC0,请告知我们。
道德考量
InstanceDiffusion广泛的图像生成能力可能会带来与许多其他文本到图像生成方法类似的挑战。
如何获得我们的支持?
如果您有任何一般性问题,请随时发送电子邮件至XuDong Wang。如果您有代码或实现相关的问题,请随时向我们发送电子邮件或在此代码库中提出问题(我们建议您在此代码库中提出问题,因为您的问题可能会帮助到其他人)。
引用
如果您发现我们的工作具有启发性或在研究中使用了我们的代码库,请考虑给予星标⭐并引用。
@misc{wang2024instancediffusion,
title={InstanceDiffusion: Instance-level Control for Image Generation},
author={Xudong Wang and Trevor Darrell and Sai Saketh Rambhatla and Rohit Girdhar and Ishan Misra},
year={2024},
eprint={2402.03290},
archivePrefix={arXiv},
primaryClass={cs.CV}
}











