
 访问官网
访问官网 Github
Github 文档
文档 论文
论文这是一篇关于使用分层三维高斯表示进行大型数据集实时渲染的论文。主要包括以下内容:
一种用于大型数据集实时渲染的分层三维高斯表示
Bernhard Kerbl, Andreas Meuleman, Georgios Kopanas, Michael Wimmer, Alexandre Lanvin, George Drettakis (* 表示共同贡献)
项目主页 | 论文
该仓库包含了论文"用于大型数据集实时渲染的分层三维高斯表示"的官方作者实现。我们解释了运行算法所需的不同步骤。我们使用了一个包含1500张图像的"玩具示例"数据集来说明该方法的每个步骤,以促进复制。本文中介绍的完整数据集将在数据保护过程完成后发布(敬请关注)。




参考文献:
@Article{hierarchicalgaussians24,
author = {Kerbl, Bernhard and Meuleman, Andreas and Kopanas, Georgios and Wimmer, Michael and Lanvin, Alexandre and Drettakis, George},
title = {A Hierarchical 3D Gaussian Representation for Real-Time Rendering of Very Large Datasets},
journal = {ACM Transactions on Graphics},
number = {4},
volume = {43},
month = {July},
year = {2024},
url = {https://repo-sam.inria.fr/fungraph/hierarchical-3d-gaussians/}
}
路线图
请注意,代码发布目前处于Alpha阶段。我们打算为用户遇到的由于设置和/或环境问题而导致的问题提供修复。以下步骤已在Windows和Ubuntu 22上成功测试。我们感谢用户记录问题,并将尽力解决它们。此外,在未来几周内,我们还将集成几个要点:
- 数据集:我们将添加正在进行审核的大型数据集的链接。
- Windows二进制文件:一旦我们充分测试,我们将为Windows添加预编译的查看器二进制文件。
- 将传统3DGS模型直接转换:我们正在测试将使用普通3DGS训练的场景转换为分层模型的过程。一旦质量得到保证,我们将记录必要的步骤。
- 从磁盘进行流式传输:目前,数据是按需流式传输到GPU,但查看的数据集必须适合内存。这在层次合并和实时查看器中可能会变得prohibitive。我们将很快修改代码以允许从磁盘进行动态流式传输。
- 减少实时查看器资源使用:实时查看器的存储配置未经优化,速度也未经优化。用户可以为场景定义VRAM预算,但使用效率并不高。我们将努力确保更高质量的设置可以使用更低的预算和更好的帧率来实现。我们将努力确保预算有效地限制了应用程序的总VRAM,包括帧缓冲区结构。
设置
确保使用--recursive克隆存储库:
git clone https://github.com/graphdeco-inria/hierarchical-3d-gaussians.git --recursive
cd hierarchical-3d-gaussians
先决条件
重要提示:在Ubuntu上似乎存在未指定的PyTorch/CUB兼容性问题,我们正在调查。同时,如果可以,在Ubuntu上将为CUDA 12.1构建的PyTorch与CUDA Toolkit 12.5安装(是的,这应该没问题,允许版本小误差)的组合看起来是一个不错的选择,根据我们的Docker实验。这个帖子提供了一个看似稳定的Ubuntu Docker文件的初步示例。
我们在Ubuntu 22.04 和 Windows 11 上进行了测试,使用了以下软件:
- CMake 3.22.1
- gcc/g++ 11.4.0 或 Visual Studio 2019
- CUDA (11.8, 12.1 或 12.5)
- COLMAP 3.9.1(仅用于预处理)。Linux:从源码构建。Windows:将 COLMAP.bat 目录添加到PATH环境变量。
用于优化的Python环境
conda create -n hierarchical_3d_gaussians python=3.12 -y
conda activate hierarchical_3d_gaussians
# 如果使用CUDA 11.x,请将 cu121 替换为 cu118
pip install torch==2.3.0 torchvision==0.18.0 torchaudio==2.3.0 --index-url https://download.pytorch.org/whl/cu121
pip install -r requirements.txt
单目深度估计的模型权重
要启用深度损失,请下载以下方法之一的模型权重:
- Depth Anything V2(建议): 从Depth-Anything-V2-Large下载,并将其放置在
submodules/Depth-Anything-V2/checkpoints/下。 - DPT(用于论文): 从dpt_large-midas-2f21e586.pt下载,并将其放置在
submodules/DPT/weights/下。
编译层次生成器和合并器
cd submodules/gaussianhierarchy
cmake . -B build -DCMAKE_BUILD_TYPE=Release
cmake --build build -j --config Release
cd ../..
编译实时查看器
对于Ubuntu 22.04,安装依赖项:
sudo apt install -y cmake libglew-dev libassimp-dev libboost-all-dev libgtk-3-dev libopencv-dev libglfw3-dev libavdevice-dev libavcodec-dev libeigen3-dev libxxf86vm-dev libembree-dev
克隆层次查看器并构建:
cd SIBR_viewers
git clone https://github.com/graphdeco-inria/hierarchy-viewer.git src/projects/hierarchyviewer
cmake . -B build -DCMAKE_BUILD_TYPE=Release -DBUILD_IBR_HIERARCHYVIEWER=ON -DBUILD_IBR_ULR=OFF -DBUILD_IBR_DATASET_TOOLS=OFF -DBUILD_IBR_GAUSSIANVIEWER=OFF
cmake --build build -j --target install --config Release
运行该方法
我们的方法有两个主要阶段:重建,它以(通常很大的)一组图像为输入,并输出一个"合并层次",以及运行时,它实时显示完整的层次。
重建有两个主要步骤:1)预处理输入图像和2)优化。我们接下来详细介绍这些。对于每个步骤,我们都有自动化的脚本来执行所有必需的步骤,我们还提供了各个组件的详细信息。
数据集
要开始,准备一个数据集或下载并提取玩具示例。
数据集应该在 ${DATASET_DIR}/inputs/images/ 中按相机文件夹排序的图像,以及可选的掩码(带有.png扩展名)在 ${DATASET_DIR}/inputs/masks/ 中。掩码将乘以输入图像和渲染,然后计算损失。
您也可以使用我们的完整场景。由于我们提供了校准和细分的数据,您可以跳到生成单目深度图。数据集:
在下面,用您的数据集路径替换 ${DATASET_DIR},或设置 DATASET_DIR:
# Bash:
DATASET_DIR=<Path to your dataset>
# PowerShell:
${DATASET_DIR} = "<Path to your dataset>"
这是一个从英文到中文的翻译,请提供以下源文本的中文翻译。
注意:翻译需要符合中文语序、流程、通顺。
跳过重建并仅显示场景,下载预训练的等级和脚手架,将它们放在
${DATASET_DIR}/output/下,并遵循 查看器说明。预训练等级:
1. 预处理
如同 3dgs 中所述,我们需要经过校准的相机和点云来训练等级。
1.1 校准相机
第一步是生成一个"全局 colmap"。以下命令使用 COLMAP 的分层映射器、校正图像和掩码,并对稀疏重建进行对齐和缩放,以便细分。
python preprocess/generate_colmap.py --project_dir ${DATASET_DIR}
使用校准的图像
如果您的数据集已经有 COLMAP (带有 2D 和 3D SfM 点)和校正后的图像,它们应该放在 ${DATASET_DIR}/camera_calibration/rectified 下。由于它们仍需要对齐,请运行:
python preprocess/auto_reorient.py --input_path ${DATASET_DIR}/camera_calibration/rectified/sparse --output_path ${DATASET_DIR}/camera_calibration/aligned/sparse/0
在我们的示例数据集上,使用 RTX A6000 时,这一步大约需要 47 分钟,有关脚本每个步骤的更多详细信息,请参阅 这里。
1.2 生成块
一旦生成了"全局 colmap",它应该被分割成块。我们还对每个块运行一次捆绑调整,因为 COLMAP 的分层映射器更快但不太准确(如果您的全局 colmap 足够准确,您可以使用 --skip_bundle_adjustment 跳过这个耗时的步骤)。
python preprocess/generate_chunks.py --project_dir ${DATASET_DIR}
在我们的示例数据集上,使用 RTX A6000 时,这一步大约需要 95 分钟,有关脚本每个步骤的更多详细信息,请参阅 这里。
请注意,通过使用
--use_slurm,您可以并行细化块,请记得在preprocess/prepare_chunks.slurm中设置您的 slurm 参数(gpu、帐户等)。
1.3 生成单目深度图
为了在训练每个块时使用深度正则化,必须为每个校正后的图像生成深度图。然后还需要计算深度缩放参数,这两个步骤可以使用以下命令完成:
python preprocess/generate_depth.py --project_dir ${DATASET_DIR}
项目结构
现在你应该有以下文件结构,这是训练部分所需要的:
project
└── camera_calibration
├── aligned
│ └── sparse/0
│ ├── images.bin
│ ├── cameras.bin
│ └── points3D.bin
├── chunks
│ ├── 0_0
│ └── 0_1
│ .
│ .
│ .
│ └── m_n
│ ├── center.txt
│ ├── extent.txt
│ └── sparse/0
│ ├── cameras.bin
│ ├── images.bin
│ ├── points3d.bin
│ └── depth_params.json
└── rectified
├── images
├── depths
└── masks
2. 优化
场景训练过程分为五个步骤:1) 我们首先训练一个全局的、粗糙的 3D 高斯溅射场景("脚手架"),然后 2) 独立并行地训练每个块, 3) 构建等级,4) 优化每个块中的等级,最后 5) 整合块以创建最终的等级。
确保您正确设置了环境并编译了等级合并器/创建器
full_train.py 脚本执行所有这些步骤来从预处理的场景训练一个等级。在训练过程中,可以使用原始的 3DGS 远程查看器可视化进度(构建说明)。
python scripts/full_train.py --project_dir ${DATASET_DIR}
命令行参数
--colmap_dir
输入已校准的 colmap。
--images_dir
校正图像的路径。
--depths_dir
校正深度的路径。
--masks_dir
校正掩码的路径。
--chunks_dir
输入块文件夹的路径。
--env_name
您创建的 conda 环境的名称。
--output_dir
输出目录的路径。
--use_slurm
启用使用 slurm 进行并行训练的标志(Falseby default).
请注意,通过使用
--use_slurm,块将被并行训练,以利用例如多 GPU 设置。要控制该过程,请记得在coarse_train.slurm、consolidate.slurm和train_chunk.slurm中设置您的 slurm 参数(gpu、帐户等)
在我们的示例数据集上,使用 RTX A6000 时,这一步大约需要 171 分钟,有关脚本每个步骤的更多详细信息,请参阅 这里。
3. 实时查看器
实时查看器基于 SIBR,类似于原始的 3DGS。有关设置,请参见 这里
在合并的等级上运行查看器
基于等级的实时查看器用于可视化我们训练的等级。它有一个"顶视图",显示结构从运动点云以及绿色的输入校准相机。等级块也以线框模式显示。
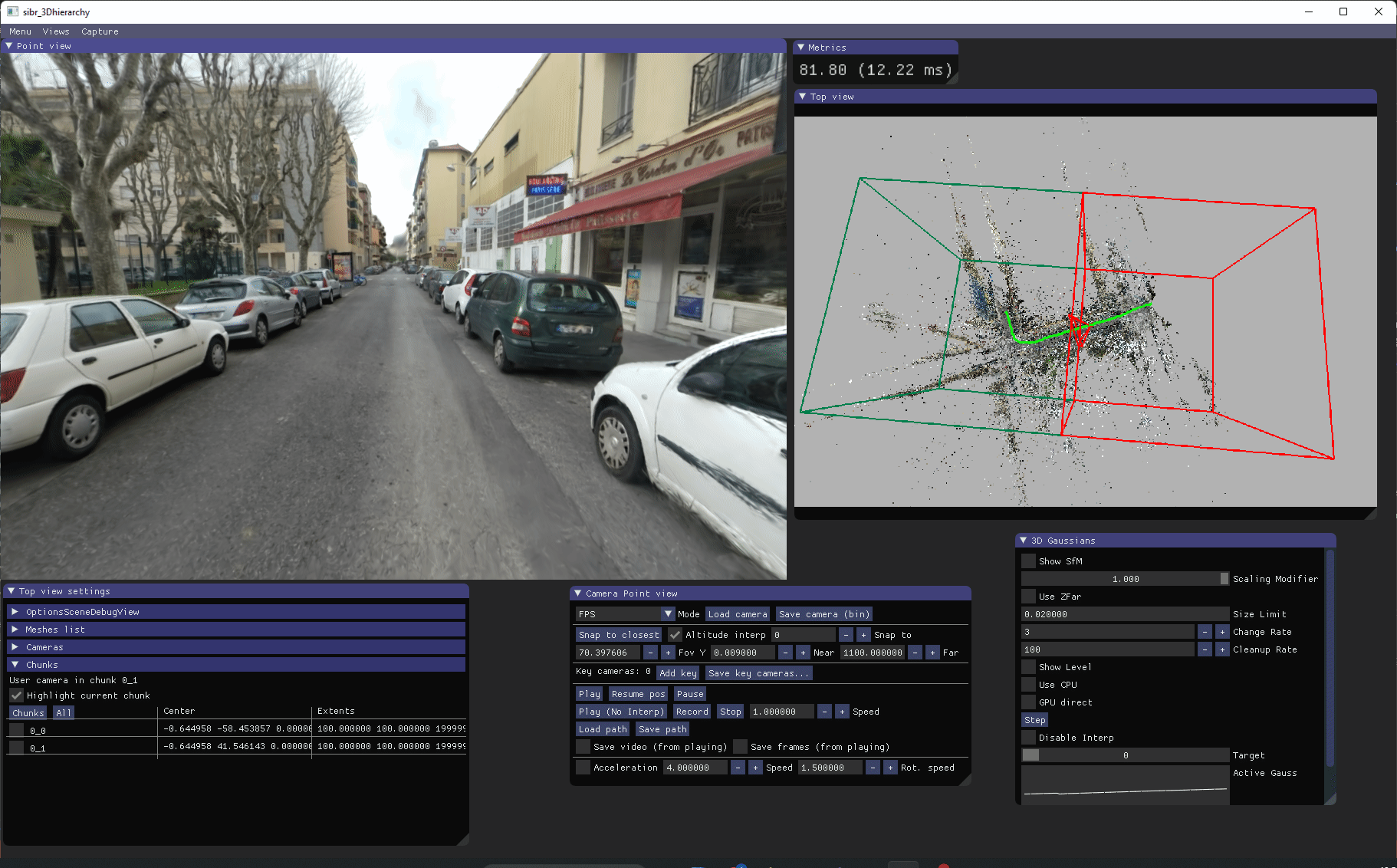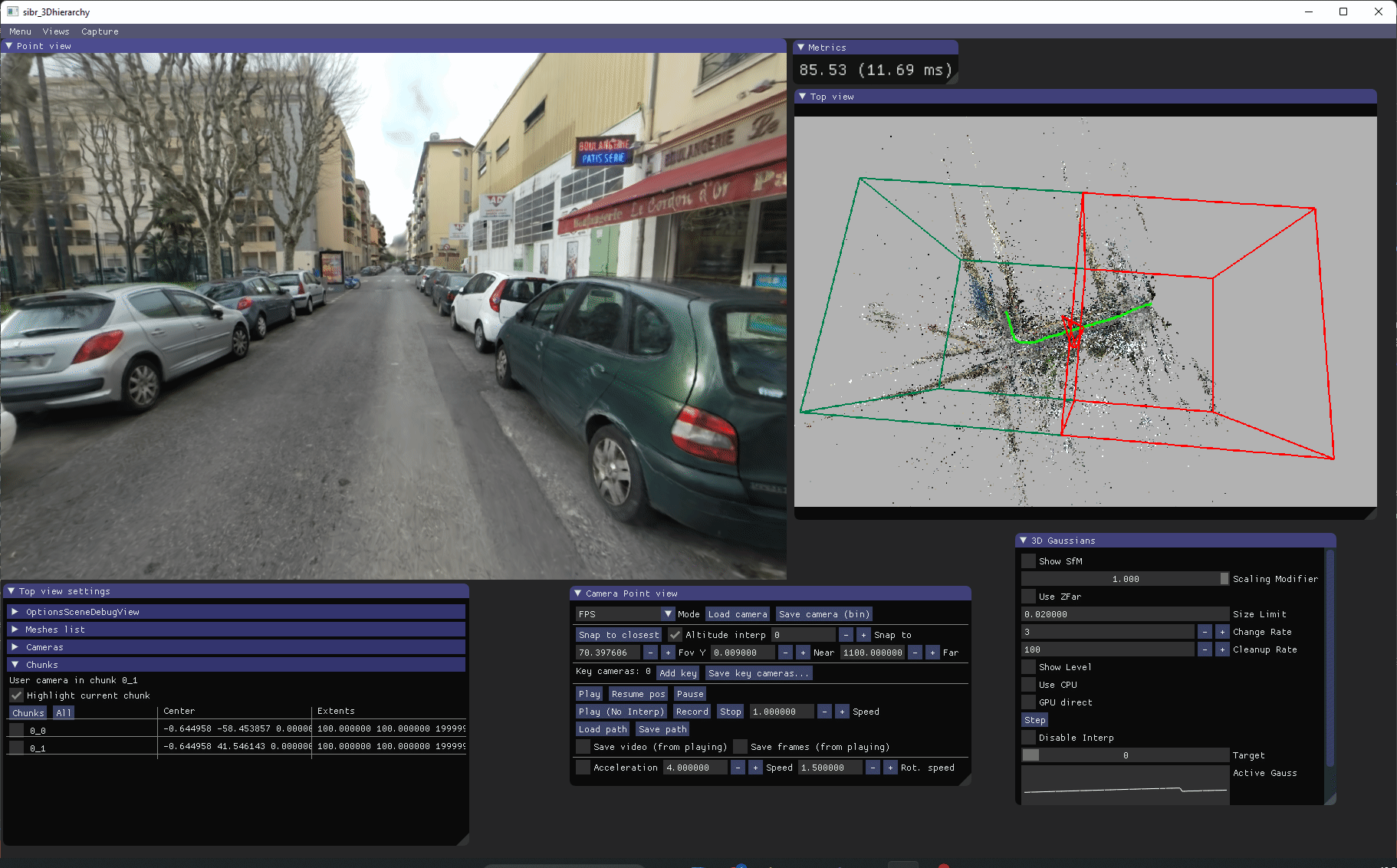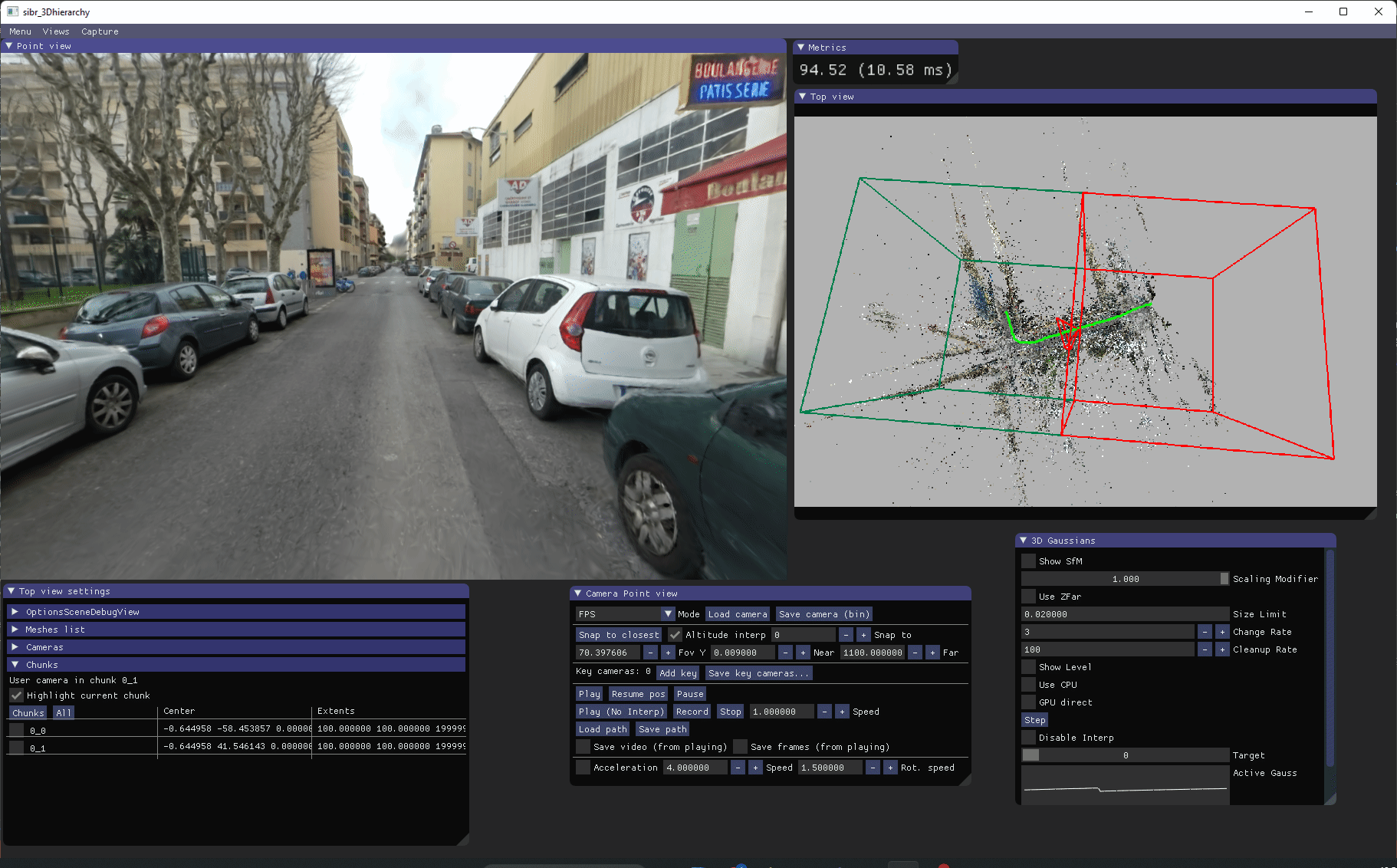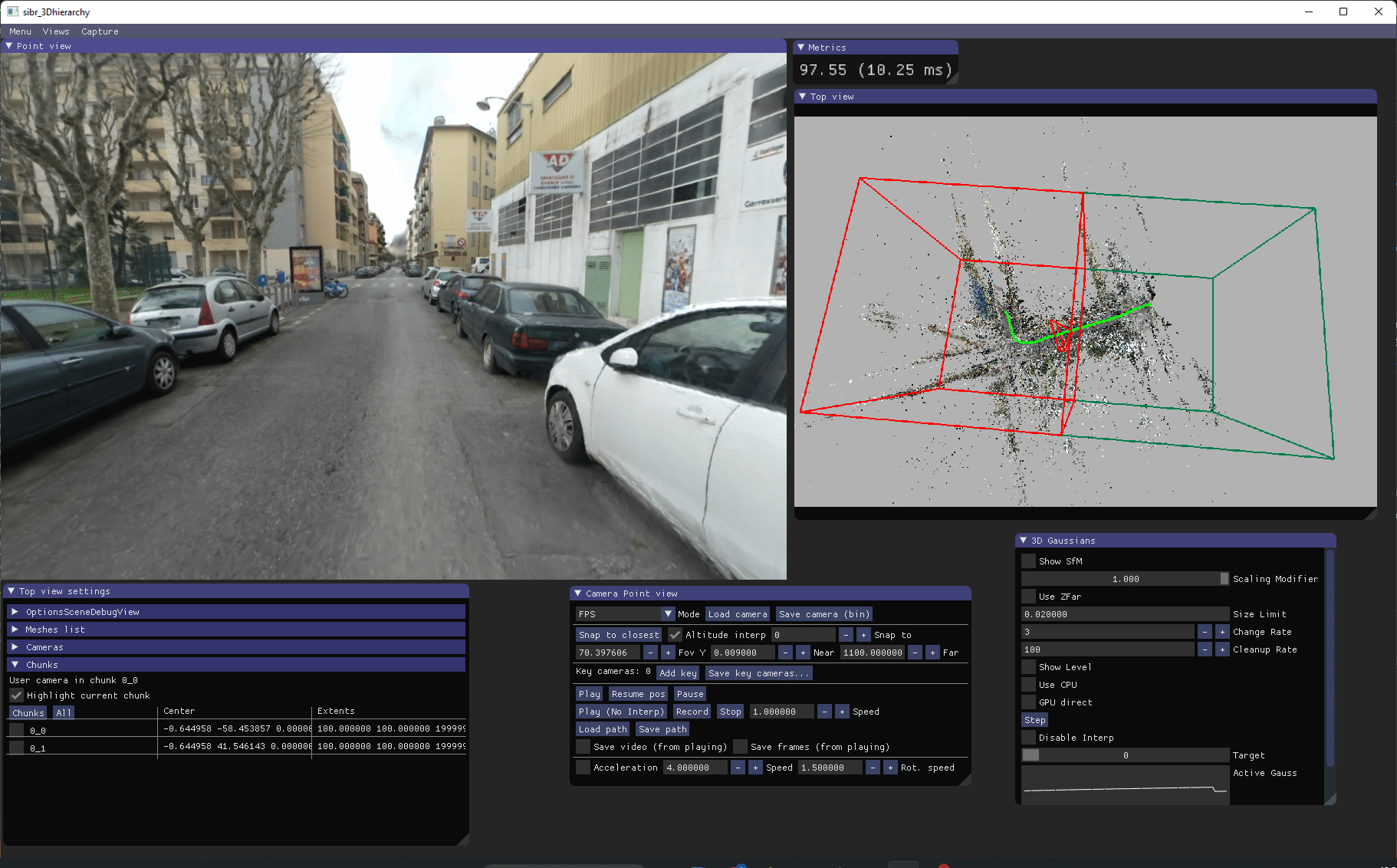
在安装查看器后,您可以在 <SIBR install dir>/bin/ 中运行编译的 SIBR_gaussianHierarchyViewer_app。控制说明在这里。
如果显存不多,请添加 --budget <Budget for the parameters in MB> (默认设置为 16000,假设至少有 16 GB 的显存)。请注意,这只定义了场景表示的预算。渲染将需要一些额外的显存(最多 1.5 GB)用于帧缓冲结构。另请注意,实时渲染器假设您的系统上可用 CUDA/OpenGL 互操作(详见原始 3DGS 文档)。
该界面包括一个用于 tau (size limit) 的字段,它定义了所需的粒度设置。请注意, tau = 0 将尝试渲染整个数据集(所有叶节点)。如果粒度设置超出可用的显存预算,而不是耗尽内存,查看器将自动调节并提高粒度,直到场景可以装入定义的显存预算中。
SIBR_viewers/install/bin/SIBR_gaussianHierarchyViewer_app --path ${DATASET_DIR}/camera_calibration/aligned --scaffold ${DATASET_DIR}/output/scaffold/point_cloud/iteration_30000 --model-path ${DATASET_DIR}/output/merged.hier --images-path ${DATASET_DIR}/camera_calibration/rectified/images
实时查看器的命令行参数
--model-path / -m
训练等级的路径。
--iteration
如果有多个可用,指定加载哪个状态。默认为最新可用的迭代。
--path / -s
参数来覆盖模型的源数据集路径。
--rendering-size
接受两个空格分隔的数字来定义实时渲染的分辨率,默认为 1200 宽。 注意,如果要强制执行与输入图像不同的宽高比,你需要 --force-aspect-ratio。
--images-path
可在顶视图中查看的校正输入图像的路径。
--device
如果有多个可用,用于光栅化的 CUDA 设备的索引, 0 默认。
--budget
可用于层次 3DGS 场景表示的显存量。
各个步骤的详细信息
生成 colmap
请注意,在我们的实验中,我们使用了 colmap 3.9.1 with cuda support
每个 colmap 命令的参数以及我们的脚本是我们在示例数据集中使用的。
可以在这里找到这些参数的更多详细信息
-
创建一个
project文件夹,并创建以下所需的文件夹:project ├── camera_calibration │ ├── aligned │ ├── rectified │ └── unrectified └── output -
在
unrectified子文件夹中生成一个database.db,通过从图像中提取特征: 输入图像文件夹应该按照每个相机一个子文件夹的方式组织。cd project/unrectified colmap feature_extractor --database_path database.db --image_path <path to images> --ImageReader.single_camera_per_folder 1 --ImageReader.default_focal_length_factor 0.5 --ImageReader.camera_model OPENCV
这是一个从英语翻译到中文的文本:
-
使用以下方法创建一个自定义的
matching.txt文件:cd hierarchical_3d_gaussians python preprocess/make_colmap_custom_matcher.py --image_path <图像路径> --output_path <matching.txt 文件路径><matching.txt 文件路径>将包含使用图像顺序和 GPS 数据(如果可用)进行接近的相机索引对。 -
之前创建的
matching.txt文件将用于特征匹配:cd ${DATASET_DIR}/unrectified colmap matches_importer --database_path <database.db> --match_list_path <matching.txt 文件路径> -
启动
hierarchical mapper创建 colmap 场景:colmap hierarchical_mapper --database_path <database.db> --image_path <图像路径> --output_path <稀疏> --Mapper.ba_global_function_tolerance=0.000001 -
移除没有 sfm 点的浮动相机和特征点,使 colmap 更轻:
cd hierarchical_3d_gaussians python preprocess/simplify_images.py --base_dir ${DATASET_DIR}/unrectified/sparse/0 -
对校准的相机去畸变,得到用于训练的图像:
cd ${DATASET_DIR} colmap image_undistorter --image_path <图像路径> --input_path <unrectified/sparse/0> --output_path <rectified> --output_type COLMAP --max_image_size 2048 -
对校准的 colmap 进行对齐和缩放:
cd hierarchical_3d_gaussians python preprocess/auto_reorient.py --input_path <project_dir/rectified/sparse> --output_path <project_dir/aligned>
生成块
最后一步是将 colmap 划分为块,每个块都有自己的 colmap,将通过两轮束调整和三角化来细化:
-
将
project/camera_calibration/aligned下的校准切割成块,每个块都有自己的 colmap:python preprocess/make_chunk.py --base_dir <project/aligned/sparse/0> --images_dir <project/rectified/images> --output_path <project/raw_chunks> -
对每个块应用两轮
三角化和束调整进行细化:python preprocess/prepare_chunk.py --raw_chunk <原始块路径> --out_chunk <输出块路径> --images_dir <project/rectified/images> --depths_dir <project/rectified/depths> --preprocess_dir <hierarchical_gaussians/preprocess_dir 路径>
单目深度图
-
生成深度图:
- 使用 Depth Anything V2:
cd submodules/Depth-Anything-V2 python run.py --encoder vitl --pred-only --grayscale --img-path [输入图像目录路径] --outdir [输出深度目录路径] - 使用 DPT:
cd submodules/DPT python run_monodepth.py -t dpt_large -i [输入图像目录路径] -o [输出深度目录路径]
- 使用 Depth Anything V2:
-
生成
depth_params.json文件:cd ../../ python preprocess/make_depth_scale.py --base_dir [colmap 路径] --depths_dir [输出深度目录路径]
训练步骤
-
粗化优化
python train_coarse.py -s <project/aligned 路径> -i <../rectified/images> --skybox_num 100000 --position_lr_init 0.00016 --position_lr_final 0.0000016 --model_path <输出脚手架路径> -
单块训练
python -u train_single.py -s [project/chunks/chunk_name] --model_path [output/chunks/chunk_name] -i [project/rectified/images] -d [project/rectified/depths] --alpha_masks [project/rectified/masks] --scaffold_file [output/scaffold/point_cloud/iteration_30000] --skybox_locked --bounds_file [project/chunks/chunk_name] -
每个块的层次结构构建
# Linux: submodules/gaussianhierarchy/build/GaussianHierarchyCreator [输出块 point_cloud.ply 路径] [块 colmap 路径] [输出块路径] [脚手架路径] # Windows: submodules/gaussianhierarchy/build/Release/GaussianHierarchyCreator.exe [输出块 point_cloud.ply 路径] [块 colmap 路径] [输出块路径] [脚手架路径] -
单块优化后处理
python -u train_post.py -s [project/chunks/chunk_name] --model_path [output/chunks/chunk_name] --hierarchy [output/chunks/chunk_name/hierarchy_name.hier] --iterations 15000 --feature_lr 0.0005 --opacity_lr 0.01 --scaling_lr 0.001 --save_iterations -1 -i [project/rectified/images] --alpha_masks [project/rectified/masks] --scaffold_file [output/scaffold/point_cloud/iteration_30000] --skybox_locked --bounds_file [project/chunks/chunk_name]
- 合并 请确保您已按照生成层次结构合并可执行文件的步骤进行了操作。 现在我们将合并所有块的层次结构:
# Linux:
submodules/gaussianhierarchy/build/GaussianHierarchyMerger [path to output/trained_chunks] "0" [path to chunk colmap] [list of all the chunk names]
# Windows:
submodules/gaussianhierarchy/build/Release/GaussianHierarchyMerger.exe [path to output/trained_chunks] "0" [path to chunk colmap] [list of all the chunk names]
Slurm 参数
每个.slurm脚本的开头必须有以下参数:
#!/bin/bash
#SBATCH --account=xyz@v100 # 您的 slurm 账户 (ex: xyz@v100)
#SBATCH --constraint=v100-32g # 您需要的 gpu (ex: v100-32g)
#SBATCH --ntasks=1 # 您需要的进程数
#SBATCH --nodes=1 # 您需要的节点数
#SBATCH --gres=gpu:1 # 您需要的 gpu 数
#SBATCH --cpus-per-task=10 # 您需要的每个任务的 cpu 数
#SBATCH --time=01:00:00 # 最大分配时间
请注意, slurm 脚本尚未经过全面测试。
评估
我们使用一个 test.txt 文件, 该文件由数据加载器读取并在传递 --eval 到训练脚本时分为训练/测试集。此文件应位于每个块的 sprase/0/ 目录以及对齐的"全局 colmap"(如果适用)中。
单块
我们用于评估的单个块:
要对一个块进行评估:
python train_single.py -s ${CHUNK_DIR} --model_path ${OUTPUT_DIR} -d depths --exposure_lr_init 0.0 --eval --skip_scale_big_gauss
# Windows: build/Release/GaussianHierarchyCreator
submodules/gaussianhierarchy/build/GaussianHierarchyCreator ${OUTPUT_DIR}/point_cloud/iteration_30000/point_cloud.ply ${CHUNK_DIR} ${OUTPUT_DIR}
python train_post.py -s ${CHUNK_DIR} --model_path ${OUTPUT_DIR} --hierarchy ${OUTPUT_DIR}/hierarchy.hier --iterations 15000 --feature_lr 0.0005 --opacity_lr 0.01 --scaling_lr 0.001 --eval
python render_hierarchy.py -s ${CHUNK_DIR} --model_path ${OUTPUT_DIR} --hierarchy ${OUTPUT_DIR}/hierarchy.hier_opt --out_dir ${OUTPUT_DIR} --eval
大型场景
确保 test.txt 文件存在于所有 sparse/0/ 文件夹中。preprocess/copy_file_to_chunks.py 可以帮助将其复制到每个块。
然后, 可以使用 eval 优化整个场景:
python scripts/full_train.py --project_dir ${DATASET_DIR} --extra_training_args '--exposure_lr_init 0.0 --eval'
以下命令会从优化的层次结构中渲染测试集。请注意, 当前实现会将整个层次结构加载到 GPU 内存中。
python render_hierarchy.py -s ${DATASET_DIR} --model_path ${DATASET_DIR}/output --hierarchy ${DATASET_DIR}/output/merged.hier --out_dir ${DATASET_DIR}/output/renders --eval --scaffold_file ${DATASET_DIR}/output/scaffold/point_cloud/iteration_30000
曝光优化
我们通常在评估中禁用曝光优化。如果您想使用它, 可以在测试图像的左半部分优化曝光, 并在右半部分进行评估。要实现这一点, 请从上述命令中删除 --exposure_lr_init 0.0, 并在所有训练脚本中添加 --train_test_exp。











