
模块化交互式视频对象分割:交互到遮罩、传播和差异感知融合(MiVOS)
Ho Kei Cheng, Yu-Wing Tai, Chi-Keung Tang
CVPR 2021
[arXiv] [论文PDF] [项目页面] [演示] [Papers with Code] [补充材料]
最新:查看我们的新作品Cutie。它还包含一个交互式GUI!
新:查看STCN分支以获得更好更快的版本。



来源(从左到右): DAVIS 2017, Academy of Historical Fencing, Modern History TV
我们使用三个不同的仓库管理项目(它们实际上是论文标题中的内容)。这是主要仓库,另请参阅Mask-Propagation和Scribble-to-Mask。
整体结构和功能
| MiVOS | Mask-Propagation | Scribble-to-Mask | |
|---|---|---|---|
| DAVIS/YouTube 半监督评估 | :x: | :heavy_check_mark: | :x: |
| DAVIS 交互式评估 | :heavy_check_mark: | :x: | :x: |
| 用户交互GUI工具 | :heavy_check_mark: | :x: | :x: |
| 密集对应 | :x: | :heavy_check_mark: | :x: |
| 训练传播模块 | :x: | :heavy_check_mark: | :x: |
| 训练S2M(交互)模块 | :x: | :x: | :heavy_check_mark: |
| 训练融合模块 | :heavy_check_mark: | :x: | :x: |
| 生成更多合成数据 | :heavy_check_mark: | :x: | :x: |
框架
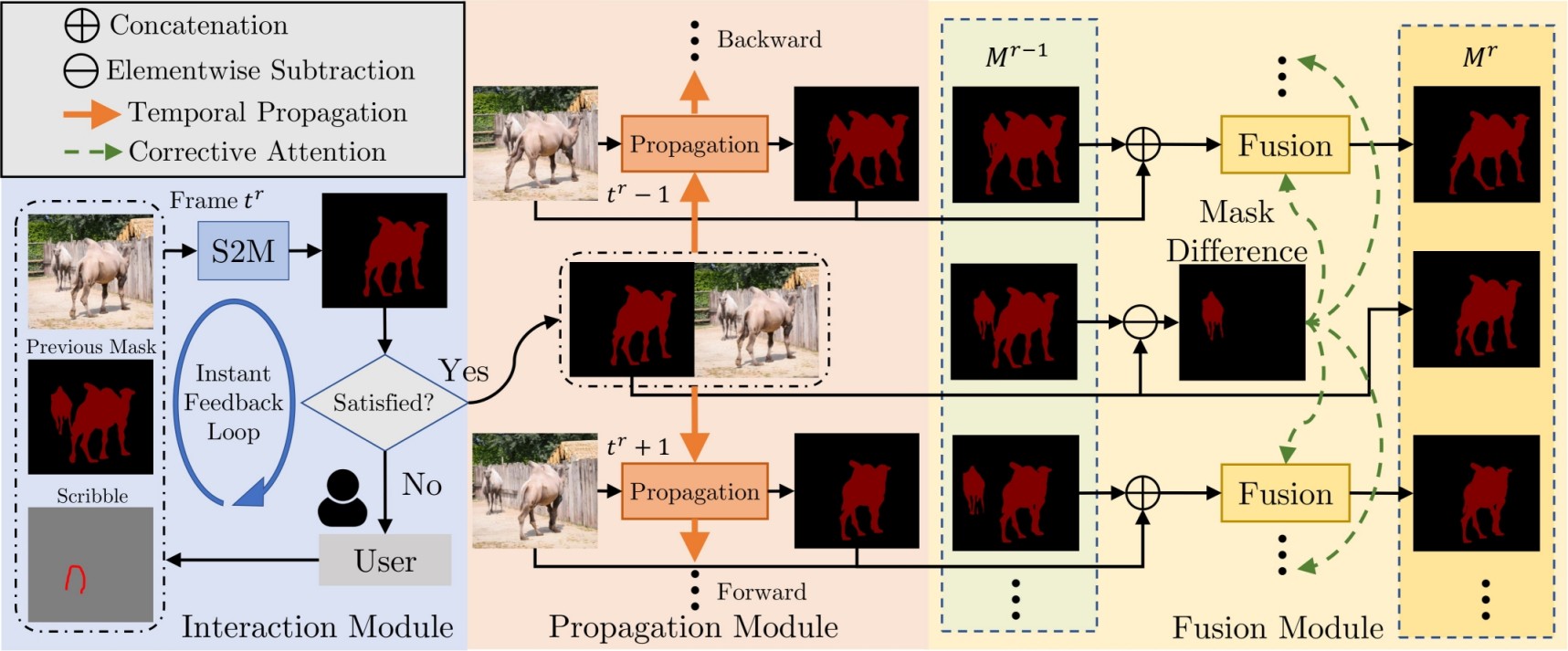
要求
我们在开发此项目时使用了以下软件包/版本。同一软件包的更高版本也很可能可以工作。这不是一个详尽的列表 - 预期会使用其他常见的Python包(例如pillow),这里没有列出。
- PyTorch
1.7.1 - torchvision
0.8.2 - OpenCV
4.2.0 - Cython
- progressbar
- davis-interactive (https://github.com/albertomontesg/davis-interactive)
- PyQt5用于GUI
- networkx
2.4用于DAVIS - gitpython用于训练
- gdown用于下载预训练模型
请参考官方PyTorch指南安装PyTorch/torchvision。其余可以通过以下方式安装:
pip install PyQt5 davisinteractive progressbar2 opencv-python networkx gitpython gdown Cython
快速开始
GUI
python download_model.py获取所有需要的模型。python interactive_gui.py --video <视频路径>或python interactive_gui.py --images <图像文件夹路径>。example/example.mp4中已为您准备了一个视频。- 如果您需要标注多个对象,还要额外指定
--num_objects <对象数量>。使用python interactive_gui.py --help查看所有参数选项。 - GUI中有说明。您也可以观看演示视频获取一些想法。
DAVIS交互式VOS
参见eval_interactive_davis.py。如果您已使用我们的脚本下载了数据集和预训练模型,您只需要指定输出路径,即python eval_interactive_davis.py --output [某处]。
DAVIS/YouTube半监督VOS
转到此仓库:Mask-Propagation。
主要结果
DAVIS/YouTube半监督结果
DAVIS交互式赛道
所有结果都是使用未修改的官方DAVIS交互式机器人生成的,没有保存遮罩(未指定--save_mask)并使用RTX 2080Ti。我们遵循官方协议。
预计算结果,包含json摘要:[Google Drive] [OneDrive]
eval_interactive_davis.py
| 模型 | AUC-J&F | J&F @ 60s |
|---|---|---|
| 基线 | 86.0 | 86.6 |
| (+) Top-k | 87.2 | 87.8 |
| (+) BL30K预训练 | 87.4 | 88.0 |
| (+) 可学习融合 | 87.6 | 88.2 |
| (+) 差异感知融合(完整模型) | 87.9 | 88.5 |
| 完整模型,不使用BL30K进行传播/融合 | 87.4 | 88.0 |
| 完整模型,STCN主干网络 | 88.4 | 88.8 |
预训练模型
python download_model.py应该可以获取您需要的所有模型。(需要pip install gdown)
训练
数据准备
数据集应按以下布局排列。您可以使用download_datasets.py(与Mask-Propagation中的相同)获取DAVIS数据集,并手动下载和提取fusion_data ([OneDrive])和BL30K。
├── BL30K
├── DAVIS
│ └── 2017
│ ├── test-dev
│ │ ├── Annotations
│ │ └── ...
│ └── trainval
│ ├── Annotations
│ └── ...
├── fusion_data
└── MiVOS
BL30K
BL30K是一个使用Blender和ShapeNet数据渲染的合成数据集。我们将数据集分成六个部分,每个部分约有5K个视频。
视频的组织格式与DAVIS和YouTubeVOS类似,因此可以直接使用这些数据集的数据加载器。每个视频有160帧,每帧分辨率为768*512。每个视频有3-5个对象,每个对象都有一个随机平滑轨迹 - 我们尝试贪婪地优化轨迹以最小化对象交叉(不能保证),但仍可能发生遮挡(在现实中经常发生)。详见generation/blender/generate_yaml.py。
我们注意到使用大约一半的数据就足以达到完全性能(尽管我们仍然使用了全部),但使用少于六分之一(5K)是不够的。
下载
您可以使用自动脚本download_bl30k.py或手动下载。请注意,每个部分大约115GB - 总共700GB。您需要~1TB的可用磁盘空间来运行脚本(包括提取缓冲区)。
根据我的经验,Google Drive速度更快。您的体验可能有所不同。
手动下载:[Google Drive] [OneDrive]
注意:Google可能会阻止Google Drive链接。您可以1)在自己的Google Drive中为该文件夹创建快捷方式,2)使用rclone从自己的Google Drive复制(不会计入您的存储限制)。
[UST镜像] (不保证可靠性,速度受限,如果其他选项可用请勿使用): ckcpu1.cse.ust.hk:8080/MiVOS/BL30K_{a-f}.tar (将{a-f}替换为您需要的部分)。
MD5校验和:
35312550b9a75467b60e3b2be2ceac81 BL30K_a.tar
269e2f9ad34766b5f73fa117166c1731 BL30K_b.tar
a3f7c2a62028d0cda555f484200127b9 BL30K_c.tar
e659ed7c4e51f4c06326855f4aba8109 BL30K_d.tar
d704e86c5a6a9e920e5e84996c2e0858 BL30K_e.tar
bf73914d2888ad642bc01be60523caf6 BL30K_f.tar
生成
- 下载 ShapeNet。
- 安装 Blender。(我们使用的是2.82版本)
- 下载一批背景和纹理图像。我们使用了这个仓库(我们在脚本中指定了"非商业重复使用"),关键词列表在generation/blender/*.json中提供。
- 生成配置文件列表(generation/blender/generate_yaml.py)。
- 对配置运行渲染。参见此处 (未详细记录,如有疑问请询问)
融合数据
我们使用传播模块处理一些数据并获取实际输出来训练融合模块。请参见脚本generate_fusion.py。
或者您可以下载预生成的融合数据:[Google Drive] [OneDrive]
训练命令
这些命令仅用于训练融合模块。
CUDA_VISIBLE_DEVICES=[a,b] OMP_NUM_THREADS=4 python -m torch.distributed.launch --master_port [cccc] --nproc_per_node=2 train.py --id [defg] --stage [h]
我们使用两个11GB的GPU实现了分布式数据并行(DDP)训练。将a, b替换为GPU ID,cccc替换为未使用的端口号,defg替换为唯一的实验标识符,h替换为训练阶段(0/1)。
模型通过不同的阶段进行渐进式训练(0: BL30K; 1: DAVIS)。每个阶段结束后,我们通过加载训练好的权重开始下一个阶段。训练融合模块需要预训练的传播模型。
一个具体的例子是:
在BL30K数据集上预训练:CUDA_VISIBLE_DEVICES=0,1 OMP_NUM_THREADS=4 python -m torch.distributed.launch --master_port 7550 --nproc_per_node=2 train.py --load_prop saves/propagation_model.pth --stage 0 --id retrain_s0
主要训练:CUDA_VISIBLE_DEVICES=0,1 OMP_NUM_THREADS=4 python -m torch.distributed.launch --master_port 7550 --nproc_per_node=2 train.py --load_prop saves/propagation_model.pth --stage 1 --id retrain_s012 --load_network [path_to_trained_s0.pth]
致谢
f-BRS: https://github.com/saic-vul/fbrs_interactive_segmentation
ivs-demo: https://github.com/seoungwugoh/ivs-demo
deeplab: https://github.com/VainF/DeepLabV3Plus-Pytorch
STM: https://github.com/seoungwugoh/STM
BlenderProc: https://github.com/DLR-RM/BlenderProc
引用
如果您觉得这个仓库有用,请引用我们的论文!
@inproceedings{cheng2021mivos,
title={Modular Interactive Video Object Segmentation: Interaction-to-Mask, Propagation and Difference-Aware Fusion},
author={Cheng, Ho Kei and Tai, Yu-Wing and Tang, Chi-Keung},
booktitle={CVPR},
year={2021}
}
如果您想引用数据集:
[bibtex内容略]
联系方式:hkchengrex@gmail.com











