
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文 
🌐 网站 • 🤗 Hugging Face • ⏬ 数据 • 📃 论文 📖 教程(中文)
中文 | 英文
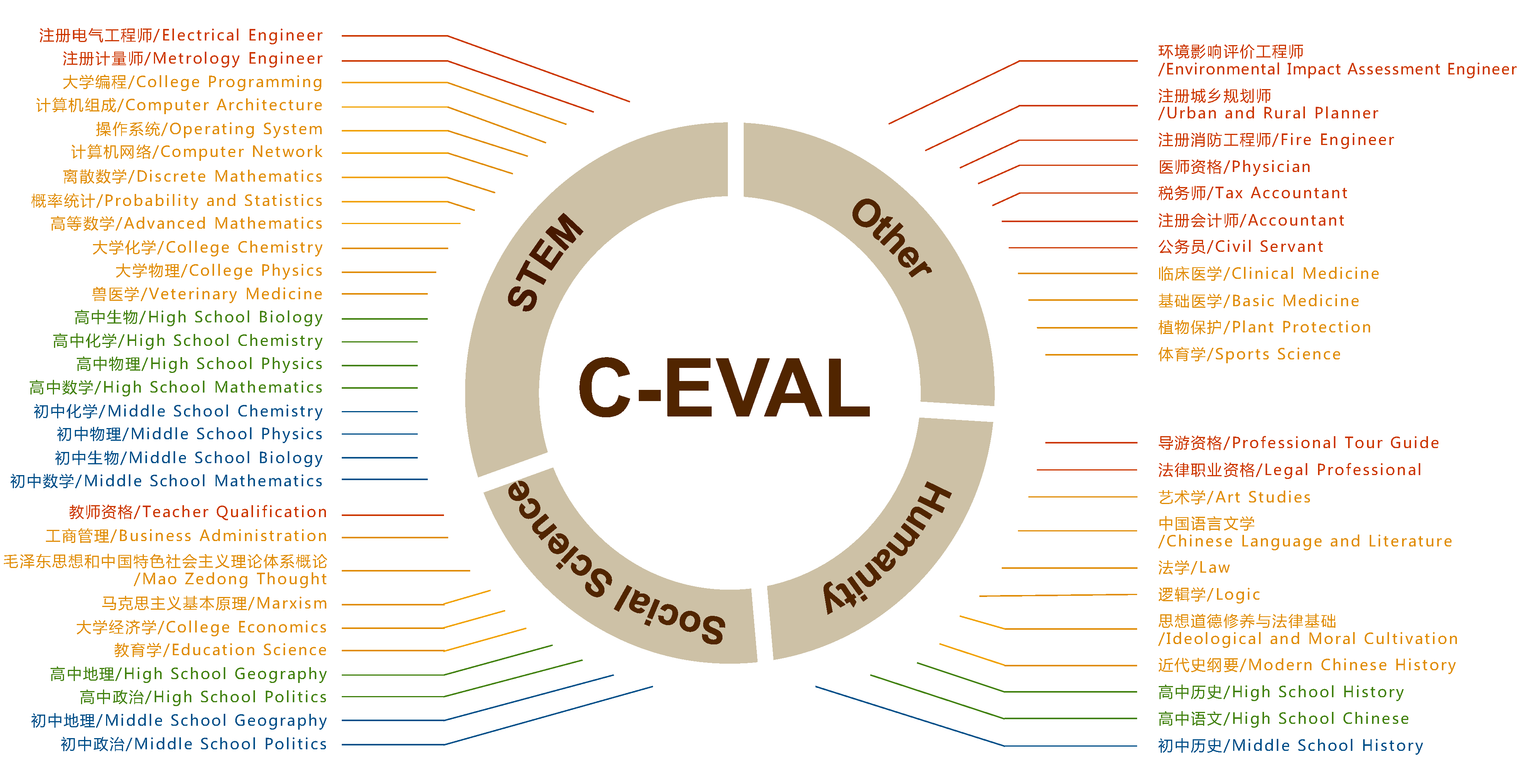
C-Eval是一个全面的中文基础模型评估套件。它包含13948个多选题,涵盖52个不同学科和四个难度级别,如下图所示。请访问我们的网站或查看我们的论文以获取更多详细信息。
我们希望C-Eval能帮助开发者跟踪进展并分析他们模型的重要优势和不足。
新闻
- [2023.10.26] C-Eval已被NeurIPS 2023接收 🎉🎉🎉
- [2023.07.17] C-Eval现已被添加到lm-evaluation-harness 🚀🚀🚀 详情请参阅通过评估工具使用。
目录
排行榜
以下是我们在初始发布中评估的模型的零样本和五样本准确率,请访问我们的官方排行榜以获取最新的模型及其在每个科目上的详细结果。我们注意到,对于许多经过指令微调的模型,零样本性能优于五样本性能。
零样本
| 模型 | STEM | 社会科学 | 人文 | 其他 | 平均 |
|---|---|---|---|---|---|
| GPT-4 | 65.2 | 74.7 | 62.5 | 64.7 | 66.4 |
| ChatGPT | 49.0 | 58.0 | 48.8 | 50.4 | 51.0 |
| Claude-v1.3 | 48.5 | 58.6 | 47.3 | 50.1 | 50.5 |
| Bloomz-mt-176B | 39.1 | 53.0 | 47.7 | 42.7 | 44.3 |
| GLM-130B | 36.7 | 55.8 | 47.7 | 43.0 | 44.0 |
| Claude-instant-v1.0 | 38.6 | 47.6 | 39.5 | 39.0 | 40.6 |
| ChatGLM-6B | 33.3 | 48.3 | 41.3 | 38.0 | 38.9 |
| LLaMA-65B | 32.6 | 41.2 | 34.1 | 33.0 | 34.7 |
| MOSS | 31.6 | 37.0 | 33.4 | 32.1 | 33.1 |
| Chinese-Alpaca-13B | 27.4 | 39.2 | 32.5 | 28.0 | 30.9 |
| Chinese-LLaMA-13B | 28.8 | 32.9 | 29.7 | 28.0 | 29.6 |
五样本
| 模型 | STEM | 社会科学 | 人文 | 其他 | 平均 |
|---|---|---|---|---|---|
| GPT-4 | 67.1 | 77.6 | 64.5 | 67.8 | 68.7 |
| ChatGPT | 52.9 | 61.8 | 50.9 | 53.6 | 54.4 |
| Claude-v1.3 | 51.9 | 61.7 | 52.1 | 53.7 | 54.2 |
| Claude-instant-v1.0 | 43.1 | 53.8 | 44.2 | 45.4 | 45.9 |
| GLM-130B | 34.8 | 48.7 | 43.3 | 39.8 | 40.3 |
| Bloomz-mt-176B | 35.3 | 45.1 | 40.5 | 38.5 | 39.0 |
| LLaMA-65B | 37.8 | 45.6 | 36.1 | 37.1 | 38.8 |
| ChatGLM-6B | 30.4 | 39.6 | 37.4 | 34.5 | 34.5 |
| 中文LLaMA-13B | 31.6 | 37.2 | 33.6 | 32.8 | 33.3 |
| MOSS | 28.6 | 36.8 | 31.0 | 30.3 | 31.1 |
| 中文Alpaca-13B | 26.0 | 27.2 | 27.8 | 26.4 | 26.7 |
C-Eval 困难题目排行榜
我们从C-Eval中选择了8个具有挑战性的数学、物理和化学科目,组成了一个单独的基准测试C-Eval Hard,包括高等数学、离散数学、概率统计、大学化学、大学物理、高中数学、高中化学和高中物理。这些科目通常涉及复杂的LaTeX方程式,需要非凡的推理能力来解决。零样本和五样本准确率如下所示。
| 模型 | 零样本 | 五样本 |
|---|---|---|
| GPT-4 | 53.3 | 54.9 |
| Claude-v1.3 | 37.6 | 39.0 |
| ChatGPT | 36.7 | 41.4 |
| Claude-instant-v1.0 | 32.1 | 35.5 |
| Bloomz-mt | 30.8 | 30.4 |
| GLM-130B | 30.7 | 30.3 |
| LLaMA-65B | 29.8 | 31.7 |
| ChatGLM-6B | 29.2 | 23.1 |
| MOSS | 28.4 | 24.0 |
| 中文LLaMA-13B | 27.5 | 27.3 |
| 中文Alpaca-13B | 24.4 | 27.1 |
验证集结果
由于我们不公开发布测试集的标签,我们提供了验证集上的零样本和五样本平均准确率作为开发者的参考。验证集共包含1346个问题。下表报告了所有科目的仅答案平均准确率。验证集的平均准确率与排行榜中呈现的测试集平均准确率非常接近。
| 模型 | 零样本 | 五样本 |
|---|---|---|
| GPT-4 | 66.7 | 69.9 |
| Claude-v1.3 | 52.1 | 55.5 |
| ChatGPT | 50.8 | 53.5 |
| Bloomz-mt | 45.9 | 38.0 |
| GLM-130B | 44.2 | 40.8 |
| Claude-instant-v1.0 | 43.2 | 47.4 |
| ChatGLM-6B | 39.7 | 37.1 |
| LLaMA-65B | 38.6 | 39.8 |
| MOSS | 35.1 | 28.9 |
| 中文Alpaca-13B | 32.0 | 27.2 |
| 中文LLaMA-13B | 29.4 | 33.1 |
数据
下载
-
方法1:下载zip文件(您也可以直接在浏览器中打开以下链接):
wget https://huggingface.co/datasets/ceval/ceval-exam/resolve/main/ceval-exam.zip然后解压缩,您可以使用pandas加载数据:
import os import pandas as pd File_Dir="ceval-exam" test_df=pd.read_csv(os.path.join(File_Dir,"test","computer_network_test.csv")) -
方法2:直接使用Hugging Face datasets加载数据集:
from datasets import load_dataset dataset=load_dataset(r"ceval/ceval-exam",name="computer_network") print(dataset['val'][0]) # {'id': 0, 'question': '使用位填充方法,以01111110为位首flag,数据为011011111111111111110010,求问传送时要添加几个0____', 'A': '1', 'B': '2', 'C': '3', 'D': '4', 'answer': 'C', 'explanation': ''}
注意事项
为了方便使用,我们整理了52个科目对应的科目名称处理程序和英文/中文名称。详情请参考subject_mapping.json。格式如下:
# 字典的键是科目处理程序,字典的值是(英文名称、中文名称、类别)元组
{
"computer_network": [
"Computer Network",
"计算机网络",
"STEM"
],
...
"filename":[
"英文名称",
"中文名称"
"超级类别标签(STEM、社会科学、人文或其他)"
]
}
每个科目包含三个划分:dev、val和test。每个科目的dev集包含五个带有解释的示例,用于少样本评估。val集用于超参数调整。test集用于模型评估。test划分的标签未公开发布,用户需要提交他们的结果以自动获取测试准确率。如何提交?
以下是来自计算机网络的dev示例:
id: 1
引用
如果您使用了C-Eval数据集,请引用我们的论文:
@article{huang2023ceval,
title={C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models},
author={Huang, Yuzhen and Bai, Yuzhuo and Zhu, Zhihao and Zhang, Junlei and Zhang, Jinghan and Su, Tangjun and Liu, Junteng and Lv, Chuancheng and Zhang, Yikai and Lei, Jiayi and Fu, Yao and Sun, Maosong and He, Junxian},
journal={arXiv preprint arXiv:2305.08322},
year={2023}
}
如果您使用我们的数据集,请引用我们的论文。
@inproceedings{huang2023ceval, title={C-Eval: 一个多层次多学科的中文基础模型评估套件}, author={黄宇臻 and 白宇卓 and 朱志浩 and 张俊磊 and 张静涵 and 苏谭君 and 刘俊腾 and 吕川程 and 张一凯 and 雷嘉仪 and 傅尧 and 孙茂松 and 何俊贤}, booktitle={神经信息处理系统进展}, year={2023} }











