
 Github
Github 论文
论文
![]()
![]()






⚡ Jax中的高速缓冲区 ⚡
概述 🔍
Flashbax是一个旨在简化强化学习(RL)中经验回放缓冲区使用的库。它专为与JAX范式兼容而设计,允许这些缓冲区在完全编译的函数和训练循环中轻松使用。
Flashbax提供了各种不同类型缓冲区的实现,如平面缓冲区、轨迹缓冲区以及两者的优先级变体。无论是用于学术研究、工业应用还是个人项目,Flashbax都为RL经验回放处理提供了简单灵活的框架。
特性 🛠️
🚀 高效缓冲区变体:所有Flashbax缓冲区都是作为轨迹缓冲区的专门变体构建的,在各种类型的缓冲区中优化内存使用和功能。
🗄️ 平面缓冲区:平面缓冲区类似于DQN等算法中使用的转换缓冲区,是一个核心组件。它使用序列长度为2(即$s_t$, $s_{t+1}$),周期为1,以全面考虑转换对。
🧺 项目缓冲区:项目缓冲区是一个存储单个项目的简单缓冲区。它适用于存储相互独立的数据,如(观察、动作、奖励、折扣、下一个观察)元组或整个回合。
🛤️ 轨迹缓冲区:轨迹缓冲区便于采样多步轨迹,适用于使用循环网络的算法,如R2D2(Kapturowski等人,2018)。
🏅 优先级缓冲区:平面缓冲区和轨迹缓冲区都可以设置优先级,实现基于用户定义优先级的采样。优先机制与PER论文(Schaul等人,2016)中概述的原则一致。
🚶 轨迹/平面队列:提供了一种队列数据结构,用于按先进先出(FIFO)顺序采样数据。该队列可用于特定用例的在线策略算法。
设置 🎬
要将Flashbax集成到您的项目中,请按以下步骤操作:
- 安装:首先使用
pip安装Flashbax:
pip install flashbax
- 选择缓冲区:从平面缓冲区、轨迹缓冲区和优先级变体等多种缓冲区选项中选择。
import flashbax as fbx
buffer = fbx.make_trajectory_buffer(...)
# 或
buffer = fbx.make_prioritised_trajectory_buffer(...)
# 或
buffer = fbx.make_flat_buffer(...)
# 或
buffer = fbx.make_prioritised_flat_buffer(...)
# 或
buffer = fbx.make_item_buffer(...)
# 或
buffer = fbx.make_trajectory_queue(...)
# 初始化
state = buffer.init(example_timestep)
# 添加数据
state = buffer.add(state, example_data)
# 采样数据
batch = buffer.sample(state, rng_key)
快速开始 🏁
以下我们提供了使用平面缓冲区的最小代码示例。在此示例中,我们展示了如何使用定义平面缓冲区的每个纯函数。请注意,这些纯函数都与jax.pmap和jax.jit兼容,但为简单起见,以下示例中未使用这些函数。
import jax
import jax.numpy as jnp
import flashbax as fbx
# 使用简单配置通过`make_flat_buffer`实例化平面缓冲区NamedTuple。
# 返回的`buffer`只是使用平面缓冲区所需的纯函数的容器。
buffer = fbx.make_flat_buffer(max_length=32, min_length=2, sample_batch_size=1)
# 初始化缓冲区的状态。
fake_timestep = {"obs": jnp.array([0, 0]), "reward": jnp.array(0.0)}
state = buffer.init(fake_timestep)
# 现在我们向缓冲区添加数据。
state = buffer.add(state, {"obs": jnp.array([1, 2]), "reward": jnp.array(3.0)})
print(buffer.can_sample(state)) # False,因为尚未达到min_length。
state = buffer.add(state, {"obs": jnp.array([4, 5]), "reward": jnp.array(6.0)})
print(buffer.can_sample(state)) # 仍为False,因为我们需要2个*转换*(即3个时间步)。
state = buffer.add(state, {"obs": jnp.array([7, 8]), "reward": jnp.array(9.0)})
print(buffer.can_sample(state)) # True!我们有2个转换(3个时间步)。
# 从缓冲区获取一个转换。
rng_key = jax.random.PRNGKey(0) # 随机源。
batch = buffer.sample(state, rng_key) # 采样
# 我们有一个转换!打印:obs = [[4 5]], obs' = [[7 8]]
print(
f"obs = {batch.experience.first['obs']}, obs' = {batch.experience.second['obs']}"
)
示例 🧑💻
我们提供以下Colab示例,作为如何使用每个flashbax缓冲区的更高级教程以及使用示例:
| Colab 笔记本 | 描述 |
|---|---|
 | 平面缓冲区快速入门 |
| 轨迹缓冲区快速入门 |
| 优先级平面缓冲区快速入门 |
| 使用 Matrax 的项目缓冲区示例 |
| Anakin DQN |
| Anakin 优先级 DQN |
| Anakin PPO |
| 使用向量化 Gym 环境的 DQN |
- 👾 Anakin - 基于 JAX 的架构,用于端到端地即时编译强化学习代理的训练。
- 🎮 DQN - 实现改编自 CleanRL 的 DQN JAX 示例。
- 🦎 Jumanji - 利用 Jumanji 基于 JAX 的环境(如贪吃蛇)进行完全即时编译的示例。
- ✖️ Matrax - JAX 中的双人矩阵游戏。
保险库 💾
保险库是一种将 Flashbax 缓冲区保存到持久数据存储的高效机制,例如用于离线强化学习。考虑一个维度为 $(B, T, *E)$ 的 Flashbax 缓冲区,其中 $B$ 是批次维度(用于同步记录独立轨迹),$T$ 是时间/序列维度,$*E$ 表示经验数据本身的一个或多个维度。由于特定环境可能会生成大量数据,保险库通过沿时间轴读写缓冲区切片来将 $T$ 维度扩展到几乎不受限制的程度。这样,巨大的缓冲区存储可以驻留在磁盘上,从中可以将子缓冲区加载到 RAM/VRAM 中进行高效的离线训练。保险库已经在项目、平面和轨迹缓冲区上进行了测试。
更多信息,请参阅演示笔记本:
重要考虑事项 ⚠️
在使用 Flashbax 缓冲区时,需要注意某些考虑事项以确保强化学习代理的正常功能。
顺序数据添加
Flashbax 使用轨迹缓冲区作为所有缓冲区类型的基础。这意味着数据必须按顺序添加。具体而言,对于平面缓冲区,每个添加的时间步必须紧跟其连续的时间步。在大多数情况下,这个要求自然得到满足,不需要过多考虑。然而,当添加完全独立的数据批次时,必须注意这个限制。未能维持时间步之间的序列关系可能导致算法问题。用户需要处理从最后一个时间步到第一个时间步的情况。这发生在同一批次中从第 n 个情节到第 n+1 个情节时。例如,我们使用自动重置包装器在终止时间步时自动重置环境。此外,我们使用折扣值(非终止状态为 1,终止状态为 0)来相应地掩蔽价值函数和奖励折扣。
有效缓冲区大小
添加数据批次时,缓冲区以块状结构创建。这意味着有效缓冲区大小取决于批次维度的大小。轨迹缓冲区允许用户指定添加批次维度和时间轴的最大长度。这将创建一个 (批次, 时间) 的块状结构,允许存储的最大时间步数为 批次*时间。为了便于使用,我们提供了 max_size 参数,允许用户设置所需的总时间步数,我们根据提供的添加批次维度计算时间轴的最大长度。因此,重要的是要注意,使用 max_size 参数时,时间轴的最大长度将等于 max_size // 添加批次大小,这将向下取整,从而减少有效缓冲区大小。这意味着人们可能认为他们增加了一定量的缓冲区大小,但实际上并没有增加。因此,为避免这种情况,我们建议采取以下两种方法之一:明确使用最大时间轴长度参数,或者以添加批次大小的倍数增加 max_size 参数。
处理情节截断
另一个关键方面是情节截断。当截断情节并将数据添加到缓冲区时,必须确保适当设置完成标志或"折扣"值。忽视这一点可能会给算法的实现和行为带来挑战。如前所述,预期算法会适当处理这些情况。使用平面缓冲区或轨迹缓冲区处理截断可能很困难,因为算法必须处理一个情节的最后时间步后面跟着下一个情节的第一个时间步的情况。为了牺牲内存效率来换取易用性,可以使用项目缓冲区来独立存储转换或整个轨迹。这意味着算法不需要处理一个情节的最后时间步后面跟着下一个情节的第一个时间步的情况,因为只有明确插入的数据才能被采样。
独立数据使用
对于打算使用缺乏顺序信息的数据的缓冲区的情况,你可以利用项目缓冲区,它是一个具有特定配置的包装轨迹缓冲区。通过将序列维度设置为 1 并将周期设置为 1,每个项目将被视为独立的。然而,当处理独立的转换项目(如观察、动作、奖励、折扣、下一个观察)时,请注意这种方法将导致缓冲区中的观察重复,从而导致不必要的内存消耗。值得注意的是,平面缓冲区的实现速度会比以这种方式使用项目缓冲区慢,这是由于硬件加速器上数据索引的固有速度问题;然而,这种权衡是为了提高内存效率。如果速度远比内存效率更重要,那么使用序列为 1 和周期为 1 的轨迹缓冲区存储完整的转换数据项。
缓冲区状态的原地更新
由于缓冲区通常很大并占用设备内存的大部分,因此执行原地更新是有益的。为此,重要的是要向顶级编译函数指定你希望执行这种原地更新操作。这表示如下:
def train(train_state, buffer_state):
...
return train_state, buffer_state
# 初始化缓冲区状态
buffer_fn = fbx.make_trajectory_buffer(...)
buffer_state = buffer_fn.init(example_timestep)
# 初始化一些训练状态
train_state = train_state.init(...)
# 编译训练函数并指定缓冲区状态参数的捐赠
train_state, buffer_state = jax.jit(train, donate_argnums=(1,))(
train_state, buffer_state
)
在调用 jax.jit 时包含 donate_argnums 很重要,这可以使 JAX 对回放缓冲区状态进行原地更新。如果省略 donate_argnums,JAX 将被迫为回放缓冲区状态的任何修改创建副本,可能会抵消所有性能优势。有关 JAX 中缓冲区捐赠的更多信息,可以在文档中找到。
使用 Vault 存储数据
如上所述,Vault 通过扩展 Flashbax 缓冲区状态的时间轴将经验数据存储到磁盘。默认情况下,Vault 方便地处理此过程的簿记:消耗缓冲区状态并保存任何新的、以前未见过的数据。例如,假设我们向 Flashbax 缓冲区写入 10 个时间步,然后将此状态保存到 Vault;由于所有这些数据都是新的,所有数据都将写入磁盘。但是,如果我们再写入一个时间步并将状态保存到 Vault,则只会写入该新时间步,防止重复已保存的数据。重要的是,必须记住 Flashbax 状态是作为环形缓冲区实现的,这意味着必须足够频繁地更新 Vault,然后再覆盖 Flashbax 缓冲区状态中未见过的数据。即如果我们的缓冲区状态的时间轴长度为 $\tau$,那么我们必须每 $\tau - 1$ 步保存到 vault 一次,以免覆盖(并丢失)未保存的数据。
总之,理解并解决这些考虑因素将帮助您避开潜在的陷阱,并确保在使用 Flashbax 缓冲区时强化学习策略的有效性。
基准测试 📈
这里我们提供了一系列初步基准测试,概述了各种 Flashbax 缓冲区与常用开源缓冲区相比的性能。在这些基准测试中,我们(除非另有明确说明)使用以下配置:
| 参数 | 值 |
|---|---|
| 缓冲区大小 | 500_000 |
| 采样批次大小 | 256 |
| 观察大小 | (32, 32, 3) |
| 添加序列长度 | 1 |
| 添加序列批次大小 | 1 |
| 采样序列长度 | 1 |
| 采样序列周期 | 1 |
我们使用采样序列长度和周期为 1 的原因是为了直接与其他缓冲区进行比较,这意味着轨迹缓冲区的速度与项目缓冲区的速度相当,因为项目缓冲区只是具有此配置的包装轨迹缓冲区。这实际上意味着轨迹缓冲区被用作内存效率低下的转换缓冲区。需要注意的是,Flat Buffer 实现使用采样序列长度为 2。此外,必须记住,并非所有其他缓冲区实现都能有效利用 GPU/TPU,因此它们只在 CPU 上运行并执行设备转换。最后,我们明确使用 Python 循环来公平比较其他缓冲区。使用扫描操作可以大大提高速度(取决于观察大小)。
CPU 速度
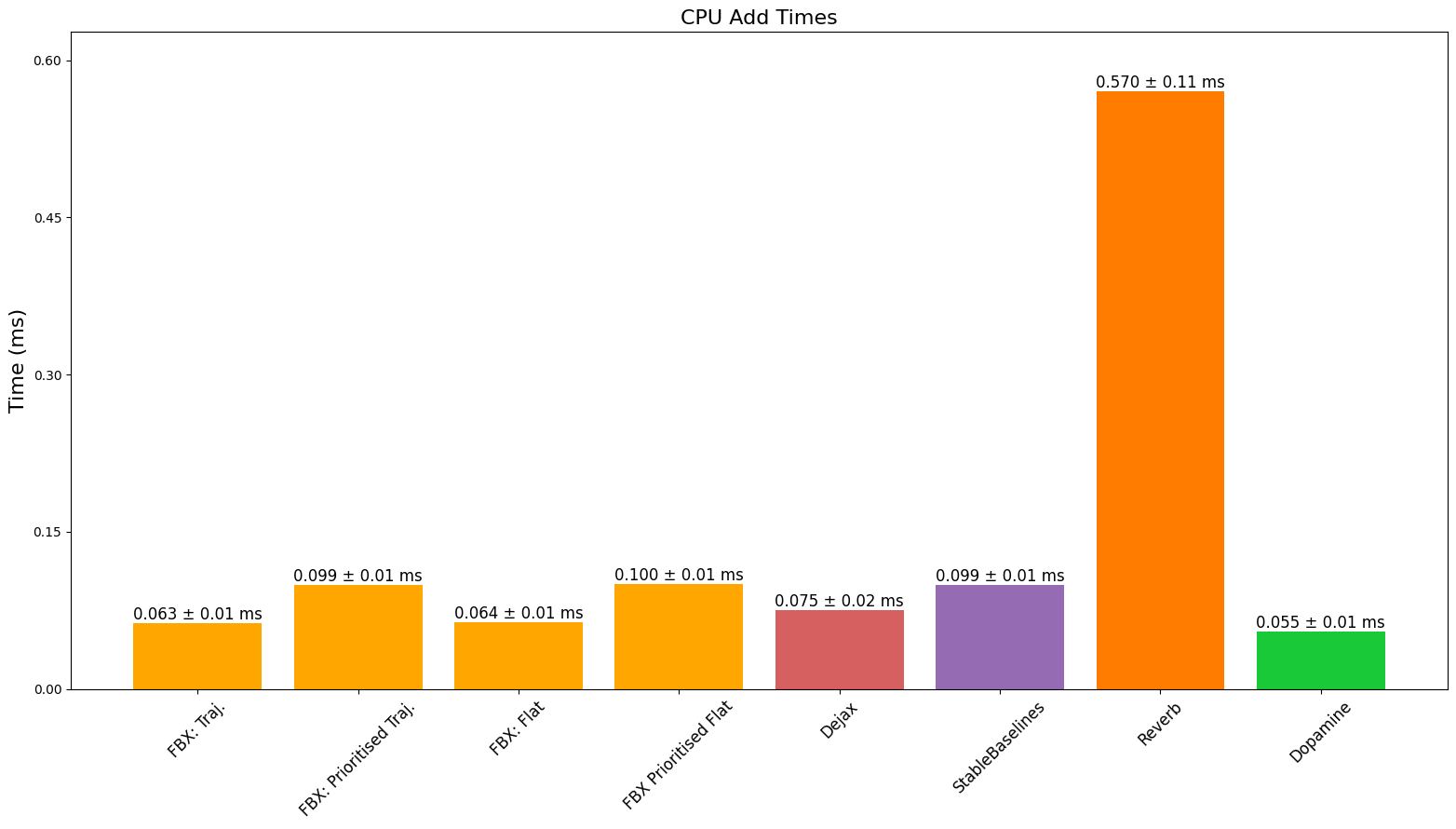
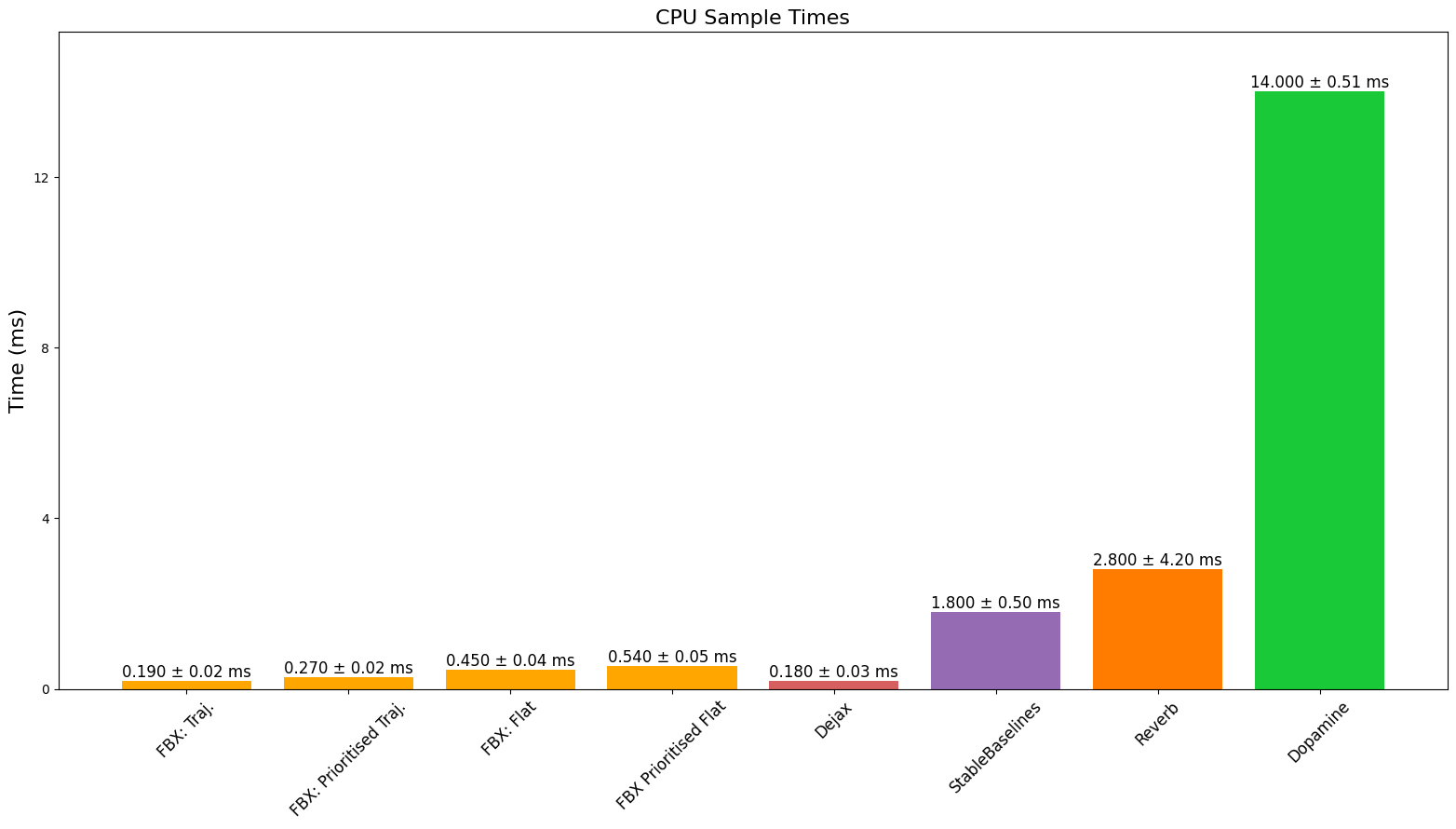
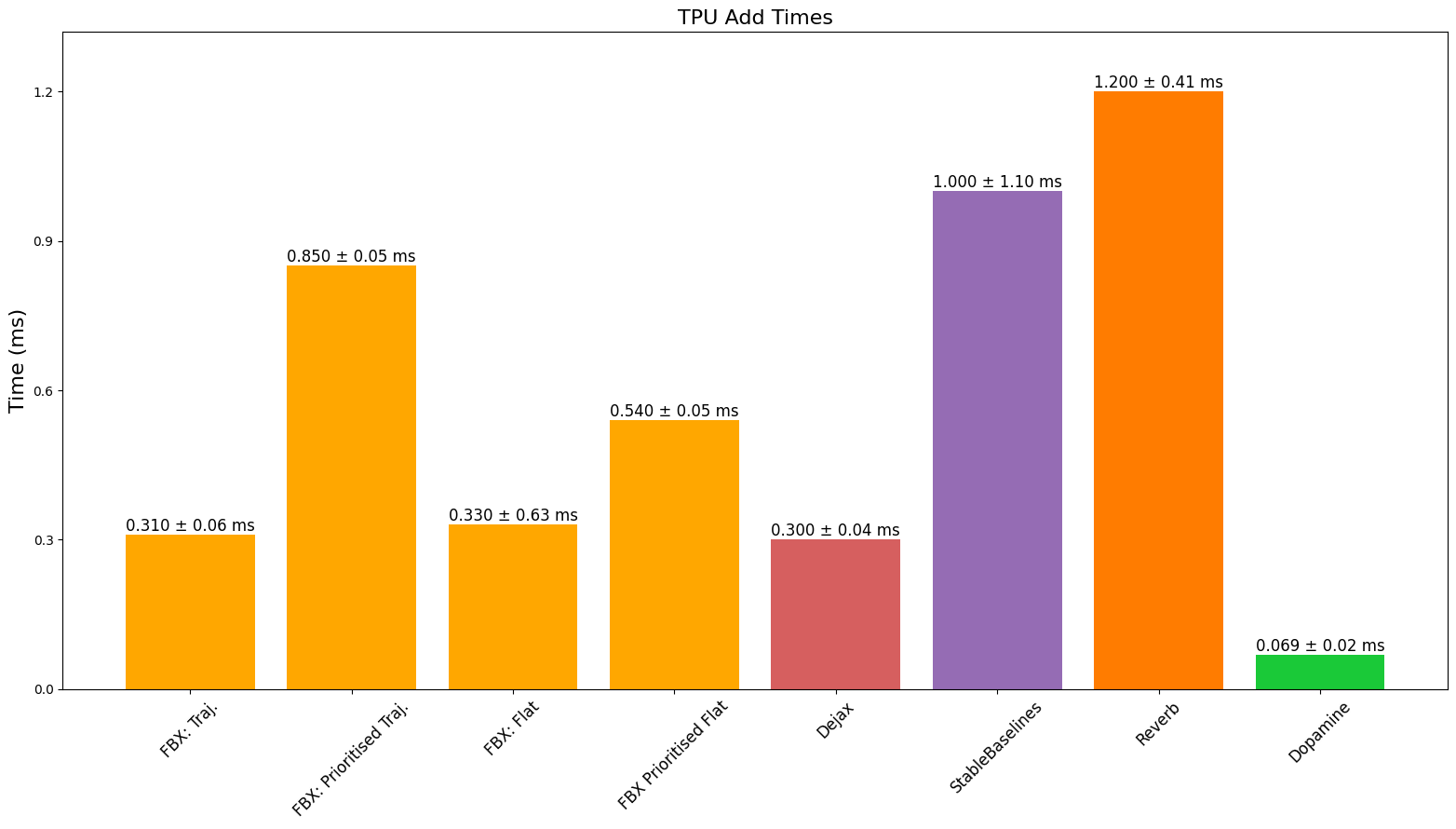
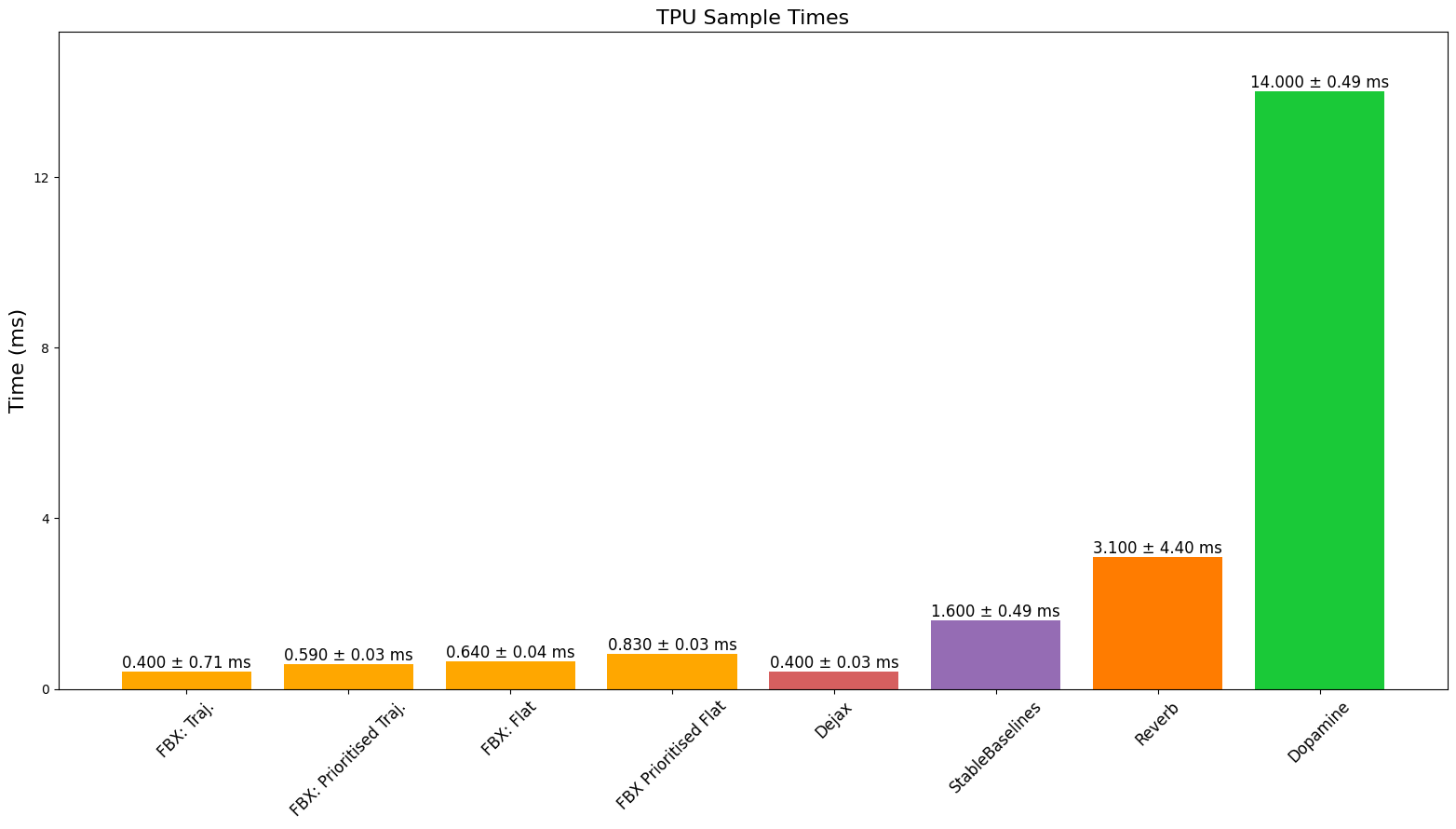
TPU 速度
GPU 速度
我们注意到添加数据时 GPU 速度出现奇怪的行为。我们认为这是因为某些 JAX 操作尚未针对 GPU 使用进行充分优化,我们看到 Dejax 也有相同的性能问题。我们预计这些速度将来会有所改善。
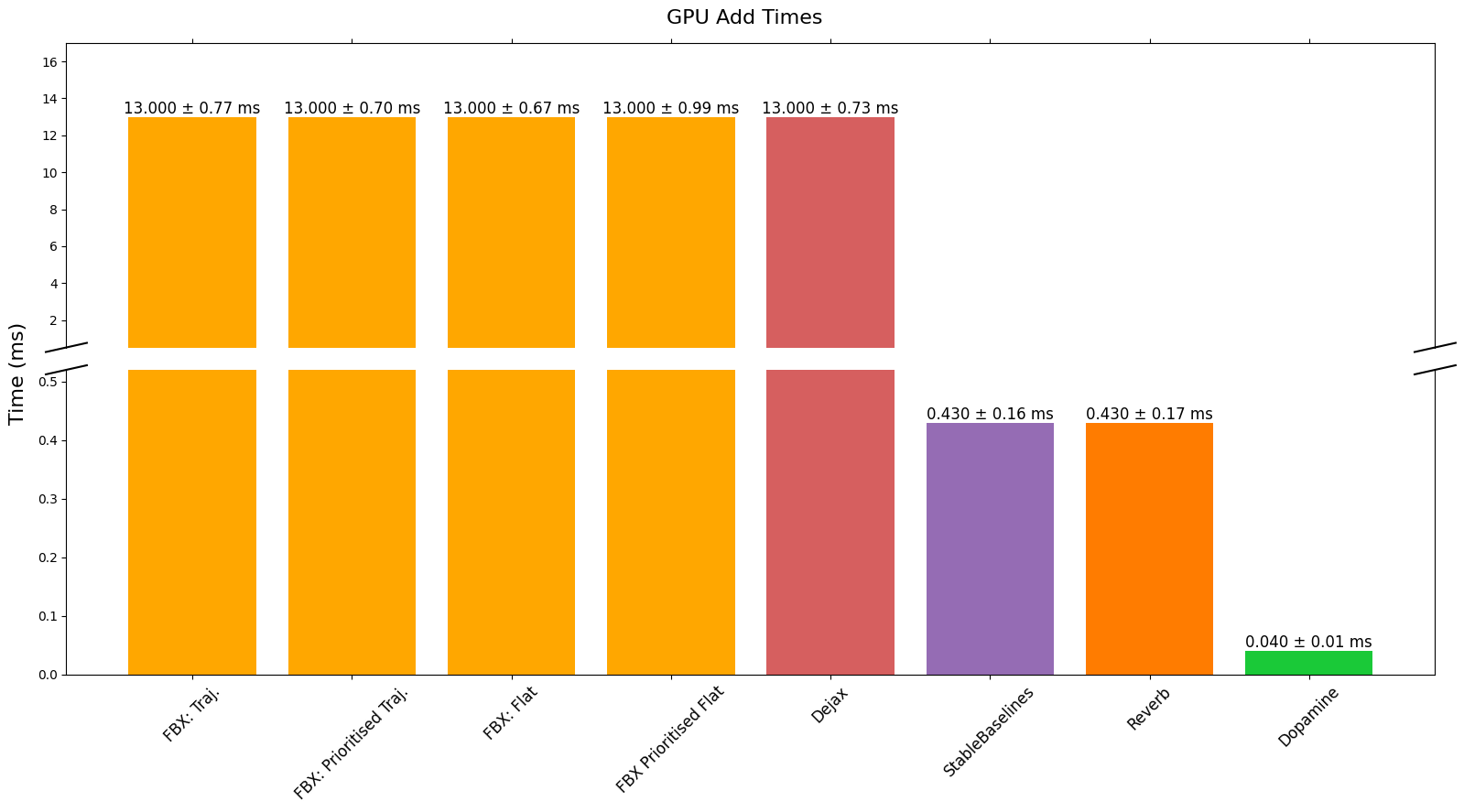
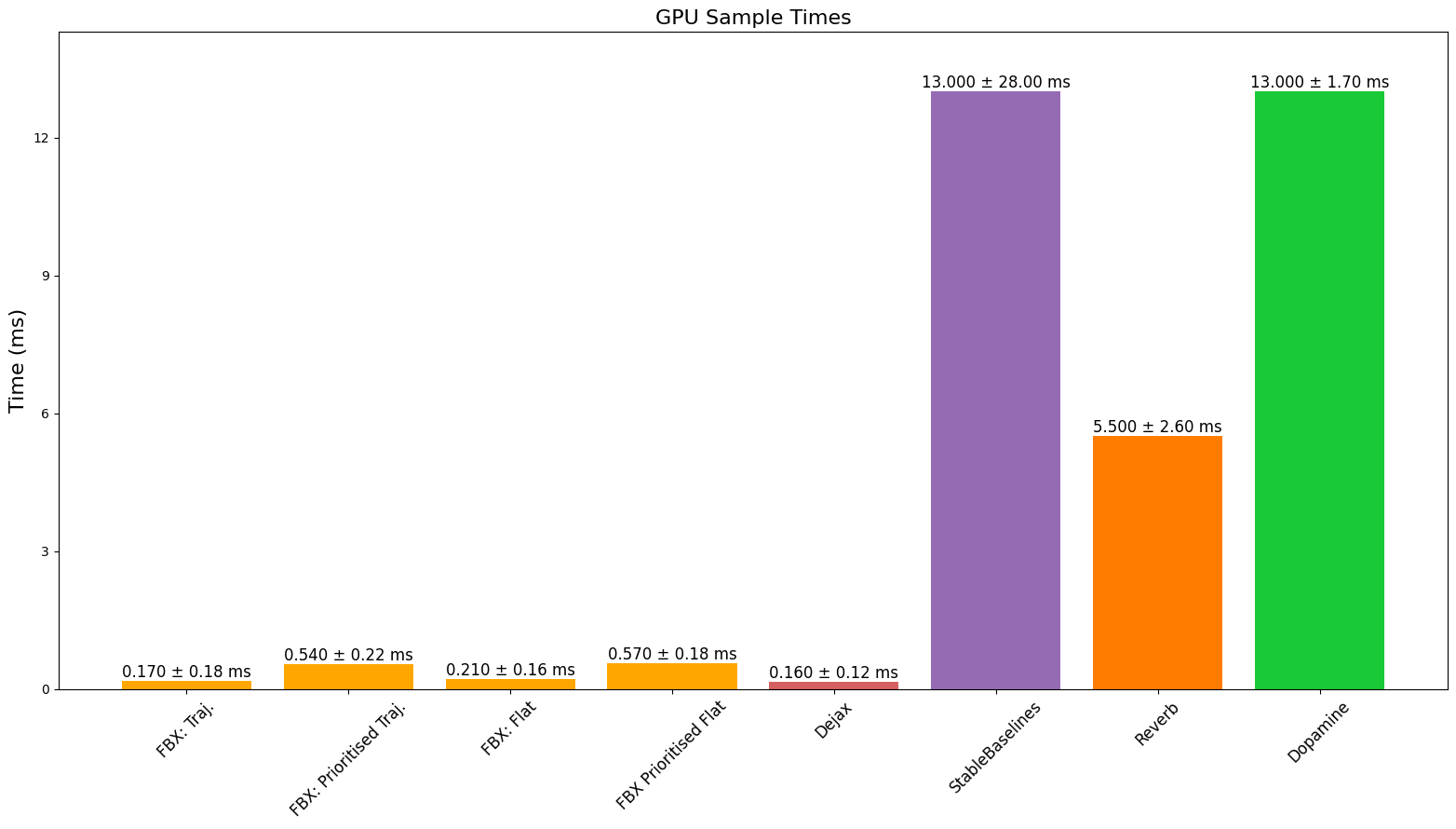
CPU、GPU 和 TPU 添加批次
之前的基准测试每次只添加一个时间步,现在我们评估每次添加 128 个时间步的批次 - 这是大多数人在高吞吐量 RL 中会使用的功能。我们只与具有此功能的缓冲区进行比较。
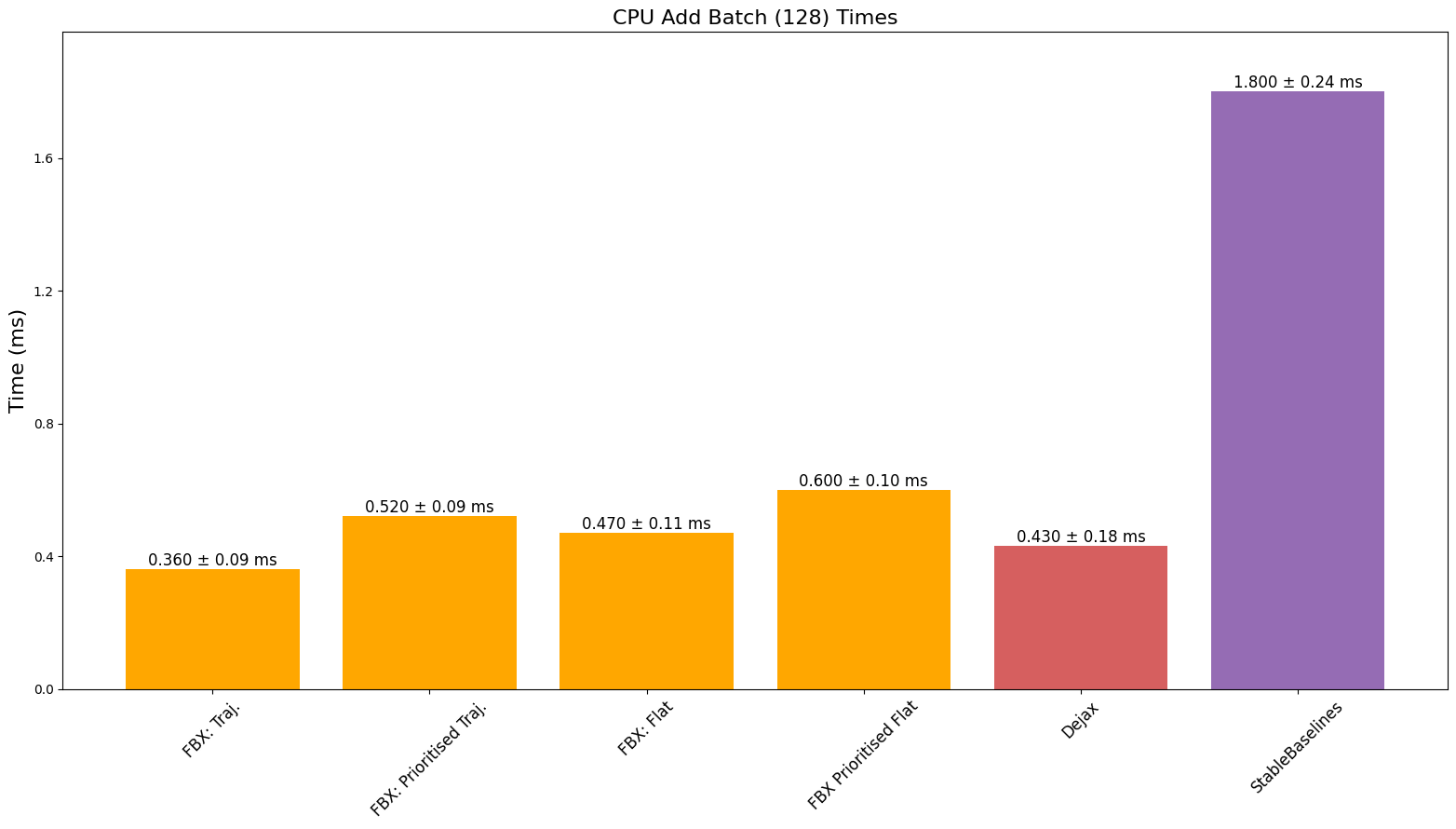
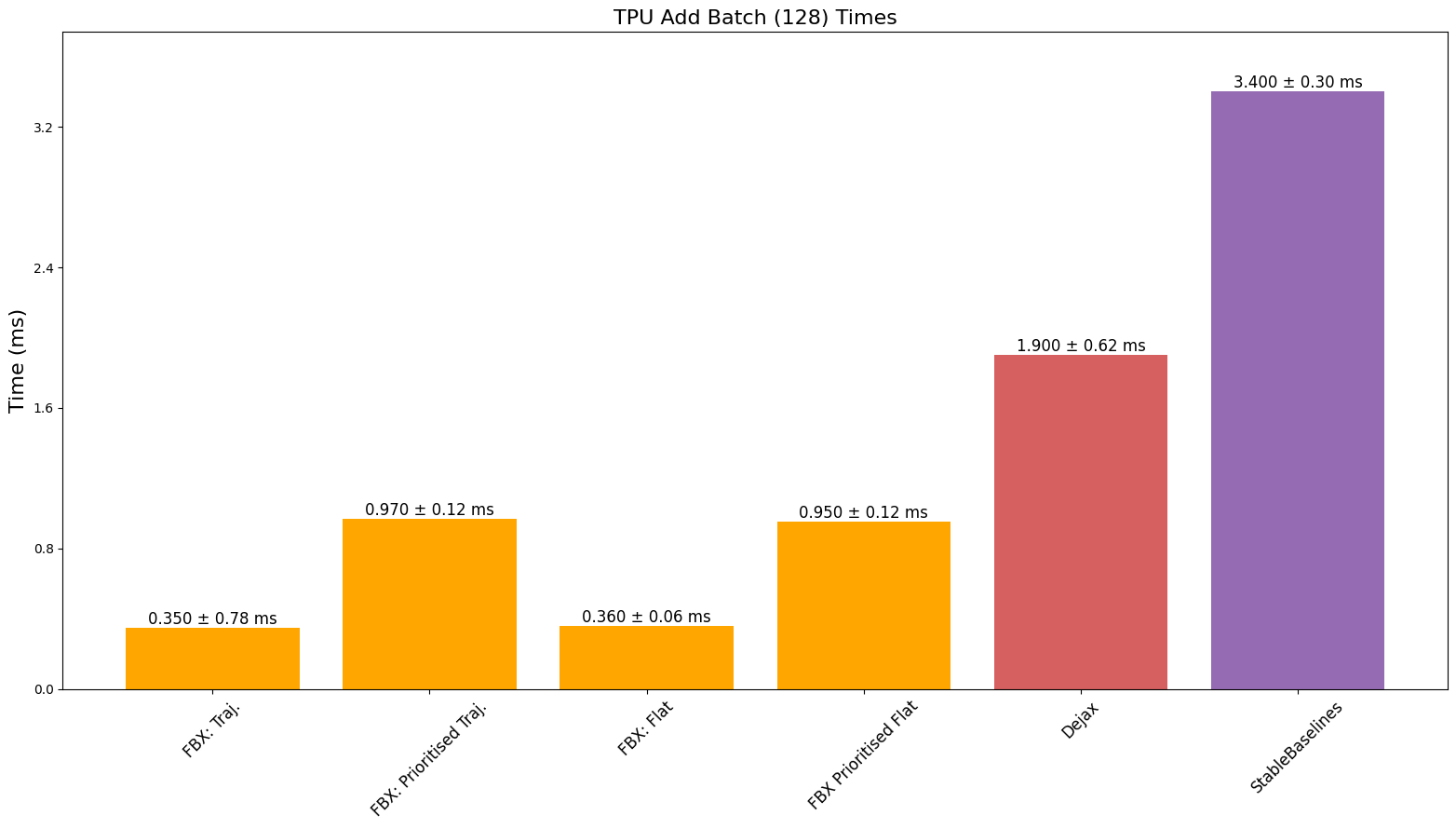
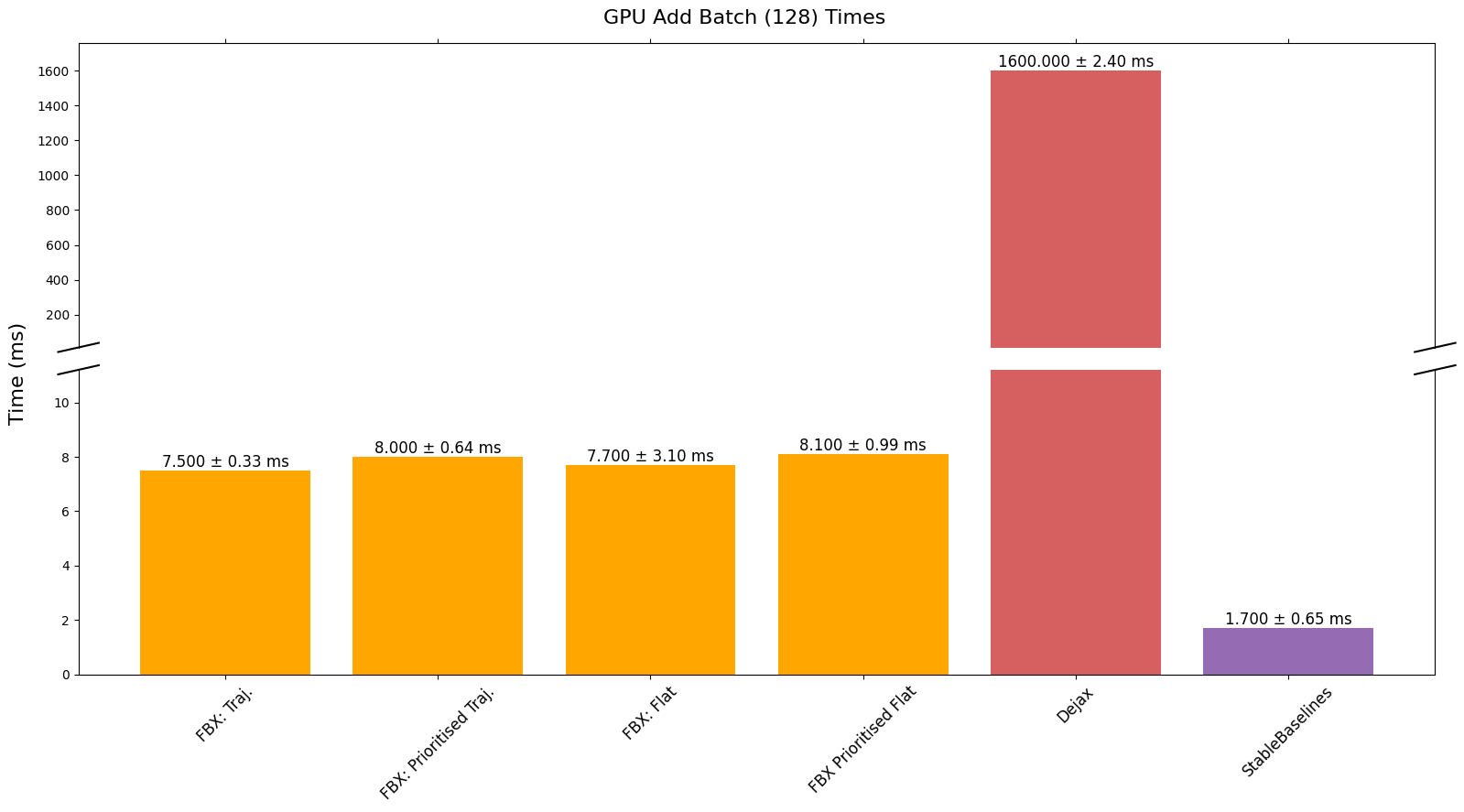
最终,我们看到性能优于或可与基准测试的缓冲区相媲美,同时提供完全兼容 JAX 的缓冲区,此外还提供批量添加以及能够添加不同长度的序列等功能。我们确实注意到,由于 JAX 对 CPU、GPU 和 TPU 有不同的 XLA 后端,缓冲区的性能可能会因设备和所调用的特定操作而异。
贡献 🤝
欢迎贡献!请查看我们的问题跟踪器以了解适合新手的问题。请阅读我们的贡献指南,了解如何提交拉取请求、我们的贡献者许可协议和社区指南的详细信息。
另请参阅 📚
其他缓冲区
查看我们在基准测试中强调的社区中的其他缓冲区库。
- 📀 Dejax: 第一个提供兼容 JAX 的回放缓冲区的库。
- 🎶 Reverb: 用于本地和大规模分布式 RL 的高效回放缓冲区。
- 🍰 Dopamine: 用于快速原型设计的研究框架,提供了几个核心回放缓冲区。
- 🤖 StableBaselines3: 可靠的 RL 基线套件,具有自己易于使用的回放缓冲区。
使用示例
查看社区中使用 flashbax 的一些库:
引用 Flashbax ✏️
如果您在工作中使用了 Flashbax,请使用以下方式引用该库:
@misc{flashbax,
title={Flashbax: Streamlining Experience Replay Buffers for Reinforcement Learning with JAX},
author={Edan Toledo and Laurence Midgley and Donal Byrne and Callum Rhys Tilbury and
Matthew Macfarlane and Cyprien Courtot and Alexandre Laterre},
year={2023},
url={https://github.com/instadeepai/flashbax/},
}
致谢 🙏
该库的开发得到了来自 Google 的 TPU Research Cloud (TRC) 🌤 的 Cloud TPU 支持。











