
 Github
Github 文档
文档 论文
论文

一个用于广义元学习和多层优化的自动微分库
文档 |
教程 |
示例 |
论文 |
引用 |
CASL





pip install betty-ml
更新
[2023年9月22日] "SAMA:使可扩展元学习变得实用"被NeurIPS 2023接收!
[2023年1月21日] Betty 作为*前5%杰出论文(口头报告)*被ICLR 2023接收!
[2023年1月12日] 我们发布了Betty v0.2,新增了对元学习的分布式训练支持!目前可用的功能包括:
现在只需一行代码的更改,您就可以轻松扩展元学习(甚至元元学习)!
- 示例:使用RoBERTa的Meta-Weight-Net
- 教程:链接
简介
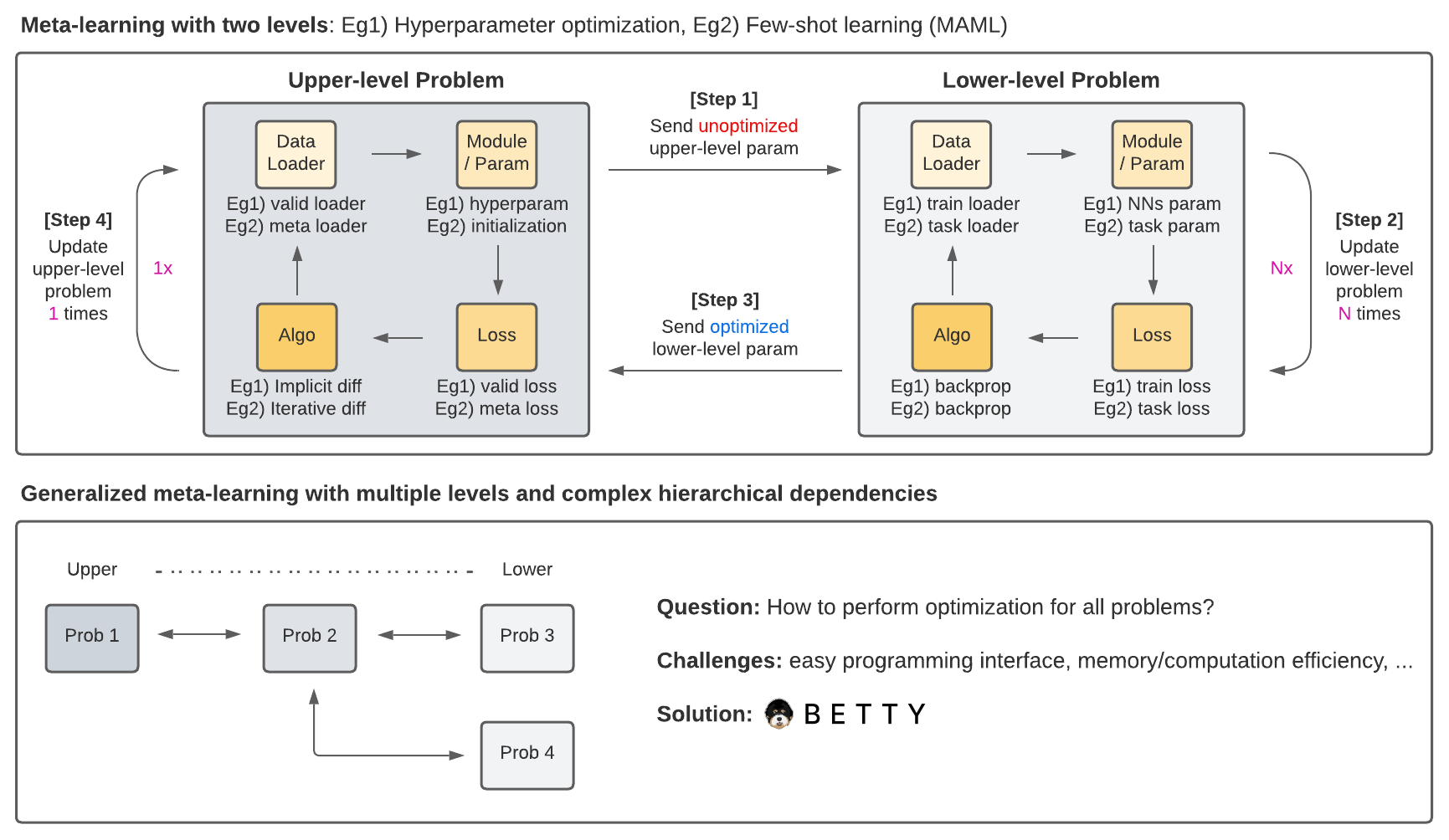
Betty 是一个基于PyTorch的广义元学习(GML)和多层优化(MLO)库,它为多个大规模应用提供了简单且模块化的编程接口,包括元学习、超参数优化、神经架构搜索、数据重加权等等。
使用Betty,用户只需做两件事即可实现任何GML/MLO程序:
快速开始
Problem
基础
每个层级问题可以通过七个组件定义:(1)模块、(2)优化器、(3)数据加载器、(4)损失函数、(5)问题配置、(6)名称,以及(7)其他可选组件(例如学习率调度器)。损失函数(4)可以通过training_step方法定义,而其他所有组件可以通过类构造函数提供。例如,图像分类问题可以定义如下:
from betty.problems import ImplicitProblem
from betty.configs import Config
# 设置模块、优化器、数据加载器(即(1)-(3))
cls_module, cls_optimizer, cls_data_loader = setup_classification()
class Classifier(ImplicitProblem):
# 设置损失函数
def training_step(self, batch):
inputs, labels = batch
outputs = self.module(inputs)
loss = F.cross_entropy(outputs, labels)
return loss
# 设置问题配置
cls_config = Config(type='darts', unroll_steps=1, log_step=100)
# Classifier问题类实例化
cls_prob = Classifier(name='classifier',
module=cls_module,
optimizer=cls_optimizer,
train_data_loader=cls_data_loader,
config=cls_config)
问题之间的交互
在GML/MLO中,每个问题通常需要访问其他问题的模块来定义其损失函数。这可以通过使用name属性来实现,如下所示:
class HPO(ImplicitProblem):
def training_step(self, batch):
# 设置超参数优化损失
...
# HPO问题类实例化
hpo_prob = HPO(name='hpo', module=...)
class Classifier(ImplicitProblem):
def training_step(self, batch):
inputs, labels = batch
outputs = self.module(inputs)
loss = F.cross_entropy(outputs, labels)
"""
通过名称'hpo'访问来自另一个问题HPO的权重衰减超参数
"""
weight_decay = self.hpo()
reg_loss = weight_decay * sum(
[p.norm().pow(2) for p in self.module.parameters()]
)
return loss + reg_loss
cls_prob = Classifier(name='classifier', module=...)
Engine
基础
Engine类处理问题之间的层级依赖关系。在GML/MLO中,有两种类型的依赖关系:上到下(u2l)和下到上(l2u)。这两种类型的依赖关系都可以用Python字典定义,其中键是起始节点,值是目标节点列表。
from betty import Engine
from betty.configs import EngineConfig
# 设置所有涉及的问题
problems = [cls_prob, hpo_prob]
# 设置上到下和下到上的依赖关系
u2l = {hpo_prob: [cls_prob]}
l2u = {cls_prob: [hpo_prob]}
dependencies = {'u2l': u2l, 'l2u': l2u}
# 设置Engine配置
engine_config = EngineConfig(train_iters=10000, valid_step=100)
# 实例化Engine类
engine = Engine(problems=problems,
dependencies=dependencies,
config=engine_config)
# 执行多层优化
engine.run()
由于Engine管理整个GML/MLO程序,您还可以在其中执行全局验证阶段。构成GML/MLO程序的所有问题都可以通过它们的名称再次访问。
class HPOEngine(Engine):
# 设置全局验证
@torch.no_grad()
def validation(self):
loss = 0
for inputs, labels in test_loader:
outputs = self.classifer(inputs)
loss += F.cross_entropy(outputs, targets)
# 返回的字典将在每次验证后自动记录
return {'loss': loss}
...
engine = HPOEngine(problems=problems,
dependencies=dependencies,
config=engine_config)
engine.run()
一旦我们分别使用Problem类和Engine类定义了所有优化问题及其之间的层次依赖关系,Betty将处理GML/MLO的所有复杂内部机制,如梯度计算和优化执行顺序。有关更多详细信息和高级功能,用户可以查看我们的文档和教程。
祝您多层次优化编程愉快!
应用
我们提供了几个GML/MLO应用的参考实现,包括:
- [超参数优化](https://github.com/leopard-ai/betty/blob/main/examples/logistic_regression_hpo/
- [神经架构搜索](https://github.com/leopard-ai/betty/blob/main/examples/neural_architecture_search/
- [数据重新加权](https://github.com/leopard-ai/betty/blob/main/examples/learning_to_reweight/
- [预训练和微调的域适应](https://github.com/leopard-ai/betty/blob/main/examples/learning_by_ignoring/
- [(隐式)模型无关的元学习](https://github.com/leopard-ai/betty/blob/main/examples/implicit_maml
虽然上述每个示例传统上都有不同的实现风格,但请注意,由于Betty的存在,我们的实现共享相同的代码结构。更多示例正在开发中!
特性
梯度近似方法
- 隐式微分
- 有限差分(或T1-T2)(DARTS:可微分架构搜索)
- 诺伊曼级数(通过隐式微分优化数百万个超参数)
- 共轭梯度(使用隐式梯度进行元学习)
- 迭代微分
- 反向模式自动微分(模型无关的元学习(MAML))
训练
- 梯度累积
- FP16/BF16训练
- 分布式数据并行训练
- 梯度裁剪
日志记录
贡献
我们欢迎社区的贡献!请查看我们的贡献指南,了解如何为Betty做出贡献的详细信息。
引用
如果您在研究中使用Betty,请引用我们的论文,使用以下Bibtex条目。
@inproceedings{
choe2023betty,
title={Betty: An Automatic Differentiation Library for Multilevel Optimization},
author={Sang Keun Choe and Willie Neiswanger and Pengtao Xie and Eric Xing},
booktitle={The Eleventh International Conference on Learning Representations },
year={2023},
url={https://openreview.net/forum?id=LV_MeMS38Q9}
}
许可证
Betty 使用 Apache 2.0 许可证。











