
 访问官网
访问官网 Github
Github 文档
文档 论文
论文


![]()




Lhotse
Lhotse 是一个 Python 库,旨在使语音和音频数据准备更加灵活,并让更广泛的社区可以使用。与 k2 一起,它是下一代 Kaldi 语音处理库的一部分。
教程演示和材料
关于
主要目标
- 通过以 Python 为中心的设计吸引更广泛的社区参与语音处理任务。
- 为经验丰富的 Kaldi 用户提供富有表现力的命令行界面。
- 为常用语料库提供标准数据准备方案。
- 为语音和音频相关任务提供 PyTorch 数据集类。
- 通过音频切片的概念实现灵活的模型训练数据准备。
- 高效性,特别是在 I/O 带宽和存储容量方面。
教程
我们目前在 examples 目录中提供了以下教程:
- 基本的完整 Lhotse 工作流程
- 使用切片转换数据
- WebDataset 集成
- 如何组合多个数据集
- Lhotse Shar:为顺序 I/O 和模块化优化的存储格式
使用示例
查看以下链接,了解 Lhotse 的实际应用:
- Icefall 方案:k2 和 Lhotse 的结合。
- 最小 ESPnet+Lhotse 示例:
主要理念
与 Kaldi 类似,Lhotse 提供标准数据准备方案,但通过特定任务的数据集类扩展了与 PyTorch 的无缝集成。数据和元数据以人类可读的文本清单形式表示,并通过方便的 Python 类向用户公开。
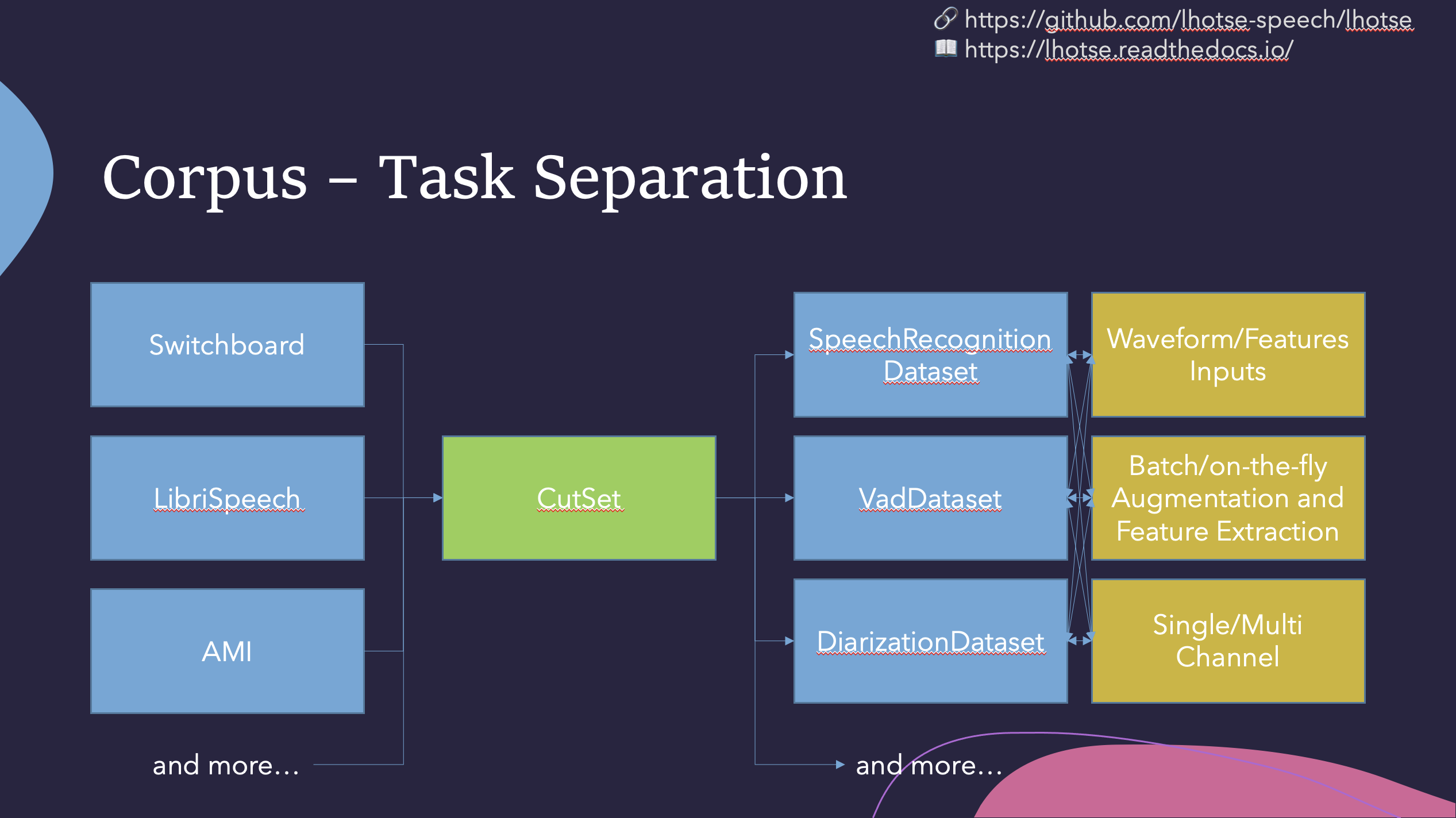
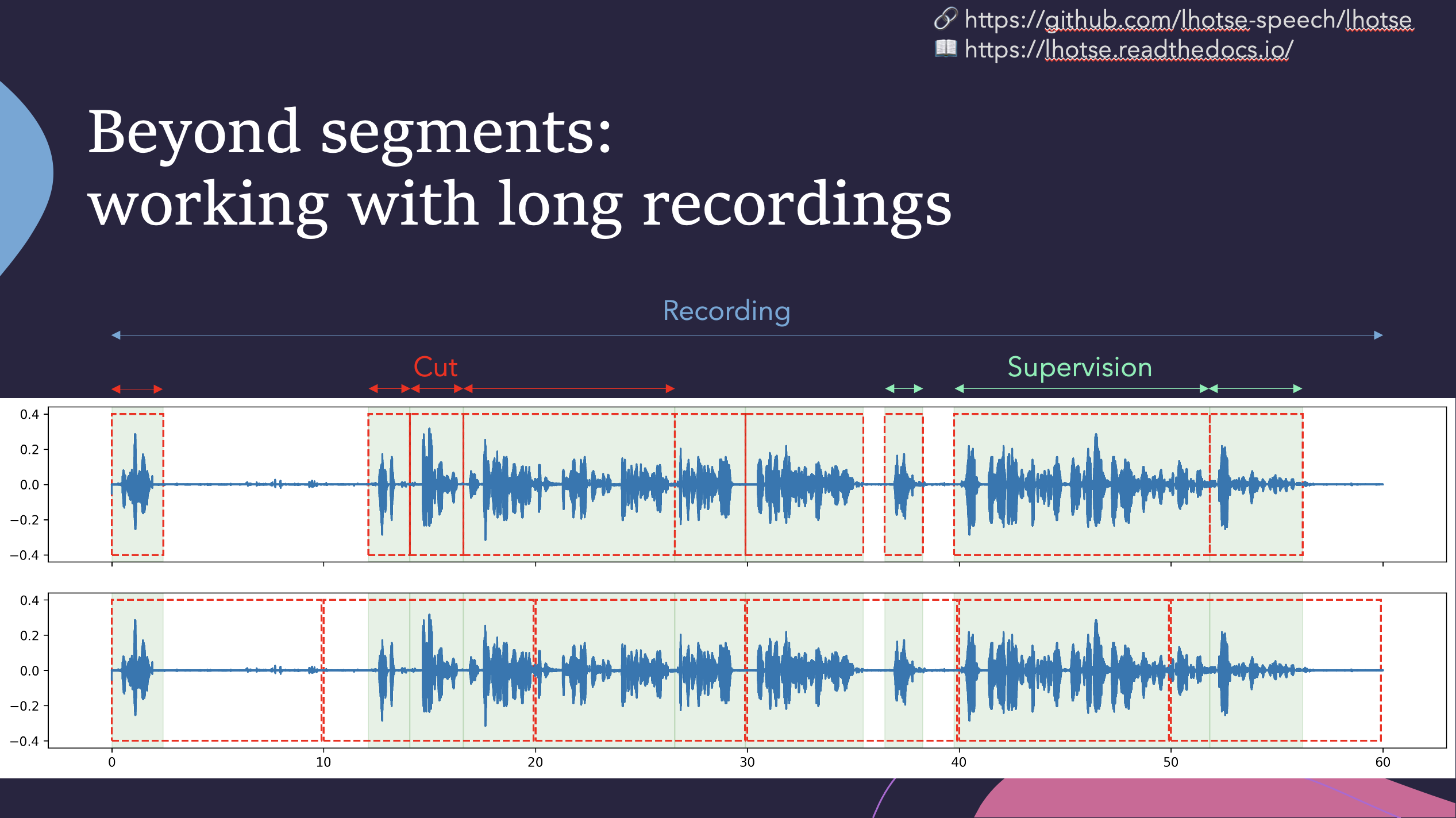
Lhotse 引入了音频切片的概念,旨在简化训练数据构建,支持即时混合、截断和填充等操作,以最大限度地减少所需的存储量。数据增强和特征提取既支持预计算模式(将高度压缩的特征矩阵存储在磁盘上),也支持即时模式(按需计算转换)。此外,Lhotse 还引入了特征空间切片混合,以充分利用两种模式的优势。
安装
Lhotse 支持 Python 3.7 及更高版本。
Pip
Lhotse 可在 PyPI 上获得:
pip install lhotse
要安装最新的未发布版本,请执行:
pip install git+https://github.com/lhotse-speech/lhotse
开发安装
对于开发安装,您可以 fork/clone GitHub 仓库并使用 pip 安装:
git clone https://github.com/lhotse-speech/lhotse
cd lhotse
pip install -e '.[dev]'
pre-commit install # 安装带有样式检查的预提交钩子
# 运行单元测试
pytest test
# 运行代码风格检查
pre-commit run
这是一个可编辑安装(-e 选项),意味着对源代码的更改在导入 lhotse 时会自动反映(无需重新安装)。[dev] 部分表示您正在安装用于运行测试、构建文档或启动 jupyter 笔记本的额外依赖项。
环境变量
Lhotse使用几个环境变量来自定义其行为。它们如下:
LHOTSE_REQUIRE_TORCHAUDIO- 当设置为非"1|True|true|yes"时,我们不会检查是否安装了torchaudio,并将其从依赖中移除。这会禁用Lhotse的许多功能,但基本能力仍会保留(包括使用soundfile读取音频)。LHOTSE_AUDIO_DURATION_MISMATCH_TOLERANCE- 用于从文件加载音频时收到的样本数与Recording.num_samples中声明的不同的情况。这有时是必要的,因为不同的编解码器(甚至同一编解码器的不同版本)在解码压缩音频时可能使用不同的填充。通常值最高到0.1,甚至0.3(秒)仍然合理,超过这个范围则表示存在严重问题。LHOTSE_AUDIO_BACKEND- 可以设置为CLIlhotse list-audio-backends返回的任何值,以覆盖默认的试错行为,始终使用特定的音频后端。LHOTSE_AUDIO_LOADING_EXCEPTION_VERBOSE- 设置为1时,当每个可用的音频后端都无法加载给定文件时,我们将发出完整的异常堆栈跟踪(它们可能非常大)。LHOTSE_DILL_ENABLED- 当设置为1|True|true|yes时,我们将启用基于dill的CutSet和Sampler跨进程序列化(即使安装了dill,默认也是禁用的)。LHOTSE_LEGACY_OPUS_LOADING- (=1)恢复到旧的OPUS加载机制,该机制为每个OPUS文件触发一个新的ffmpeg子进程。LHOTSE_PREPARING_RELEASE- 开发人员在发布Lhotse新版本时内部使用。TORCHAUDIO_USE_BACKEND_DISPATCHER- 当设置为1且torchaudio版本低于2.1时,我们将启用torchaudio的实验性ffmpeg后端。AIS_ENDPOINT由AIStore客户端读取以确定AIStore端点URL。AIStore数据加载需要此设置。RANK、WORLD_SIZE、WORKER和NUM_WORKERS在内部用于通知Lhotse Shar数据加载子进程。READTHEDOCS在内部用于文档构建。
可选依赖
其他pip包。 你可以通过安装相关支持包来利用Lhotse的可选功能,如下所示:pip install lhotse[package_name]。支持的可选包包括:
pip install lhotse[kaldi]以获得与Kaldi兼容性相关的最大功能集。它包括kaldi_native_io(kaldi_io的更高效变体)和kaldifeat等库,这些库将部分Kaldi功能移植到Python中。pip install lhotse[orjson]以获得最高50%更快的JSONL清单读取速度。pip install lhotse[webdataset]。我们支持将数据"编译"成WebDataset tarball格式以实现更高效的IO。你仍然可以像操作常规懒加载CutSet一样与数据交互。要了解更多信息,请查看以下教程:pip install h5py如果你想提取语音特征并将它们存储为HDF5数组。pip install dill。安装dill后,我们将使用它来pickle在.map或.filter等调用中使用lambda函数的CutSet。这在使用num_jobs>0的PyTorch DataLoader中很有帮助。没有dill,根据你的环境,你将看到异常或脚本挂起。pip install aistore以使用AIStore支持的URL从AIStore读取清单、tar文件和其他数据(设置AIS_ENDPOINT环境变量以激活它)。有关更多详细信息,请参阅AIStore文档。pip install smart_open以在任何smart_open支持的位置(例如云、http)读写清单和数据。pip install opensmile用于使用OpenSmile工具包的Python包装器进行特征提取。
sph2pipe。 要读取使用ffmpeg和sox不支持的编解码器压缩的旧LDC SPHERE (.sph)音频文件,请运行:
# CLI
lhotse install-sph2pipe
# Python
from lhotse.tools import install_sph2pipe
install_sph2pipe()
它会将其下载到~/.lhotse/tools,编译它,并自动在PATH中注册。Lhotse应该能自动检测并使用该程序。
示例
我们有示例配方,展示如何准备数据并在Python中将其作为PyTorch Dataset加载。
它们位于examples目录中。
以下是一个简短的代码片段,展示Lhotse如何使音频数据准备变得快速而简单:
from torch.utils.data import DataLoader
from lhotse import CutSet, Fbank
from lhotse.dataset import VadDataset, SimpleCutSampler
from lhotse.recipes import prepare_switchboard
# 从原始语料库分发准备数据清单。
# RecordingSet描述了有关音频录音的元数据;
# 采样率、通道数、持续时间等。
# SupervisionSet描述了有关监督片段的元数据:
# 转录文本、说话人、语言等。
swbd = prepare_switchboard('/export/corpora3/LDC/LDC97S62')
# CutSet是Lhotse的主力,允许灵活的数据操作。
# 我们通过以窗口方式遍历SWBD录音来创建5秒的切片。
# 此时实际上没有将任何音频数据加载到内存或存储到磁盘。
cuts = CutSet.from_manifests(
recordings=swbd['recordings'],
supervisions=swbd['supervisions']
).cut_into_windows(duration=5)
# 我们计算对数梅尔滤波器能量并将其存储在磁盘上;
# 然后,我们将切片填充到5秒,以确保所有切片长度相等,
# 因为每个录音的最后一个窗口可能持续时间较短。
# 填充将在特征加载到内存后执行。
cuts = cuts.compute_and_store_features(
extractor=Fbank(),
storage_path='feats',
num_jobs=8
).pad(duration=5.0)
# 构造一个用于语音活动检测任务的Pytorch Dataset类:
dataset = VadDataset()
sampler = SimpleCutSampler(cuts, max_duration=300)
dataloader = DataLoader(dataset, sampler=sampler, batch_size=None)
batch = next(iter(dataloader))
VadDataset将产生一批特征和监督张量对,如下所示 - 语音大约在第一秒(100帧)开始:












