
 访问官网
访问官网 Github
Github 论文
论文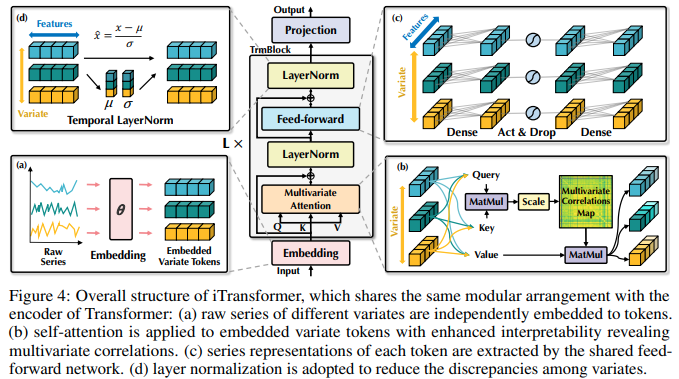
iTransformer
实现iTransformer - 来自清华/蚂蚁集团的使用注意力网络的最先进时间序列预测
现在只剩下表格数据(xgboost仍是冠军)了,然后就可以真正宣称"注意力是你所需要的全部"
在苹果公司让作者更改名称之前。
官方实现已在这里发布!
致谢
-
感谢StabilityAI和🤗 Huggingface的慷慨赞助,以及我的其他赞助商,让我能够独立地开源当前的人工智能技术。
-
感谢Greg DeVos分享他在
iTransformer上运行的实验以及一些即兴变体
安装
$ pip install iTransformer
使用方法
import torch
from iTransformer import iTransformer
# 使用太阳能设置
model = iTransformer(
num_variates = 137,
lookback_len = 96, # 或论文中的回溯长度
dim = 256, # 模型维度
depth = 6, # 深度
heads = 8, # 注意力头
dim_head = 64, # 头部维度
pred_length = (12, 24, 36, 48), # 可以是一个预测,或多个
num_tokens_per_variate = 1, # 实验性设置,将每个变量映射到多个token。这个想法是网络可以学会将时间划分为更精细的时间token,以便对时间进行更精细的注意力。多亏了快速注意力,你应该能够很好地适应长序列长度
use_reversible_instance_norm = True # 使用可逆实例归一化,在这里提出 https://openreview.net/forum?id=cGDAkQo1C0p 。考虑到iTransformer内部的层归一化(以及在第一个层归一化之前的第一层上注意力可能学到的任何其他东西),这可能是多余的。如果我有时间,我会收集所有变量的统计数据,投影它们,并进一步调节transformer。这样更有意义
)
time_series = torch.randn(2, 96, 137) # (批次, 回溯长度, 变量)
preds = model(time_series)
# preds -> Dict[int, Tensor[batch, pred_length, variate]]
# -> (12: (2, 12, 137), 24: (2, 24, 137), 36: (2, 36, 137), 48: (2, 48, 137))
对于一个即兴版本,可以对时间token进行精细的注意力(以及原始的每个变量token),只需导入iTransformer2D并设置额外的num_time_tokens
更新:它成功了!感谢Greg DeVos在这里运行实验!
更新2:收到了一封邮件。是的,如果这个架构适合你的问题,你可以自由地写一篇关于它的论文。我对此没有任何利害关系
import torch
from iTransformer import iTransformer2D
# 使用太阳能设置
model = iTransformer2D(
num_variates = 137,
num_time_tokens = 16, # 时间token的数量(补丁大小将是(回溯长度 // num_time_tokens))
lookback_len = 96, # 论文中的回溯长度
dim = 256, # 模型维度
depth = 6, # 深度
heads = 8, # 注意力头
dim_head = 64, # 头部维度
pred_length = (12, 24, 36, 48), # 可以是一个预测,或多个
use_reversible_instance_norm = True # 使用可逆实例归一化
)
time_series = torch.randn(2, 96, 137) # (批次, 回溯长度, 变量)
preds = model(time_series)
# preds -> Dict[int, Tensor[batch, pred_length, variate]]
# -> (12: (2, 12, 137), 24: (2, 24, 137), 36: (2, 36, 137), 48: (2, 48, 137))
实验性
带有傅里叶token的iTransformer
一个iTransformer,但也带有傅里叶token(时间序列的FFT被投影到它们自己的token中,并与变量token一起被关注,最后被拼接出来)
import torch
from iTransformer import iTransformerFFT
# 使用太阳能设置
model = iTransformerFFT(
num_variates = 137,
lookback_len = 96, # 或论文中的回溯长度
dim = 256, # 模型维度
depth = 6, # 深度
heads = 8, # 注意力头
dim_head = 64, # 头部维度
pred_length = (12, 24, 36, 48), # 可以是一个预测,或多个
num_tokens_per_variate = 1, # 实验性设置,将每个变量映射到多个token。这个想法是网络可以学会将时间划分为更精细的时间token,以便对时间进行更精细的注意力。多亏了快速注意力,你应该能够很好地适应长序列长度
use_reversible_instance_norm = True # 使用可逆实例归一化,在这里提出 https://openreview.net/forum?id=cGDAkQo1C0p 。考虑到iTransformer内部的层归一化(以及在第一个层归一化之前的第一层上注意力可能学到的任何其他东西),这可能是多余的。如果我有时间,我会收集所有变量的统计数据,投影它们,并进一步调节transformer。这样更有意义
)
time_series = torch.randn(2, 96, 137) # (批次, 回溯长度, 变量)
preds = model(time_series)
# preds -> Dict[int, Tensor[batch, pred_length, variate]]
# -> (12: (2, 12, 137), 24: (2, 24, 137), 36: (2, 36, 137), 48: (2, 48, 137))
待办事项
- 用最新发现加强transformer
- 在变量和时间上即兴创作2D版本
- 即兴创作包含fft token的版本
- 即兴创作使用基于所有变量统计数据的自适应归一化的变体
引用
@misc{liu2023itransformer,
title = {iTransformer: Inverted Transformers Are Effective for Time Series Forecasting},
author = {Yong Liu and Tengge Hu and Haoran Zhang and Haixu Wu and Shiyu Wang and Lintao Ma and Mingsheng Long},
year = {2023},
eprint = {2310.06625},
archivePrefix = {arXiv},
primaryClass = {cs.LG}
}
@misc{shazeer2020glu,
标题 = {GLU变体改进Transformer},
作者 = {Noam Shazeer},
年份 = {2020},
网址 = {https://arxiv.org/abs/2002.05202}
}
@misc{burtsev2020memory,
标题 = {记忆Transformer},
作者 = {Mikhail S. Burtsev 和 Grigory V. Sapunov},
年份 = {2020},
预印本 = {2006.11527},
预印本库 = {arXiv},
主要类别 = {cs.CL}
}
@inproceedings{Darcet2023VisionTN,
标题 = {视觉Transformer需要寄存器},
作者 = {Timoth'ee Darcet 和 Maxime Oquab 和 Julien Mairal 和 Piotr Bojanowski},
年份 = {2023},
网址 = {https://api.semanticscholar.org/CorpusID:263134283}
}
@inproceedings{dao2022flashattention,
标题 = {Flash{A}ttention:具有{IO}感知的快速高效精确注意力机制},
作者 = {Dao, Tri 和 Fu, Daniel Y. 和 Ermon, Stefano 和 Rudra, Atri 和 R{\'e}, Christopher},
会议名称 = {神经信息处理系统进展},
年份 = {2022}
}
@Article{AlphaFold2021,
作者 = {Jumper, John 和 Evans, Richard 和 Pritzel, Alexander 和 Green, Tim 和 Figurnov, Michael 和 Ronneberger, Olaf 和 Tunyasuvunakool, Kathryn 和 Bates, Russ 和 {\v{Z}}{\'\i}dek, Augustin 和 Potapenko, Anna 和 Bridgland, Alex 和 Meyer, Clemens 和 Kohl, Simon A A 和 Ballard, Andrew J 和 Cowie, Andrew 和 Romera-Paredes, Bernardino 和 Nikolov, Stanislav 和 Jain, Rishub 和 Adler, Jonas 和 Back, Trevor 和 Petersen, Stig 和 Reiman, David 和 Clancy, Ellen 和 Zielinski, Michal 和 Steinegger, Martin 和 Pacholska, Michalina 和 Berghammer, Tamas 和 Bodenstein, Sebastian 和 Silver, David 和 Vinyals, Oriol 和 Senior, Andrew W 和 Kavukcuoglu, Koray 和 Kohli, Pushmeet 和 Hassabis, Demis},
期刊 = {Nature},
标题 = {高度精确的蛋白质结构预测{AlphaFold}},
年份 = {2021},
doi = {10.1038/s41586-021-03819-2},
注释 = {(加速文章预览)},
}
@inproceedings{kim2022reversible,
标题 = {可逆实例归一化:用于应对分布偏移的准确时间序列预测},
作者 = {Taesung Kim 和 Jinhee Kim 和 Yunwon Tae 和 Cheonbok Park 和 Jang-Ho Choi 和 Jaegul Choo},
会议名称 = {国际学习表示会议},
年份 = {2022},
网址 = {https://openreview.net/forum?id=cGDAkQo1C0p}
}
@inproceedings{Katsch2023GateLoopFD,
标题 = {GateLoop:用于序列建模的完全数据控制线性递归},
作者 = {Tobias Katsch},
年份 = {2023},
网址 = {https://api.semanticscholar.org/CorpusID:265018962}
}











