
 访问官网
访问官网 Github
Github Huggingface
Huggingface 文档
文档

Pandrator:一个具有语音克隆和AI文本优化功能的GUI有声读物和配音生成器
Pandrator是一款工具,旨在将文本、PDF、EPUB和SRT文件转换成多种语言的语音,基于开源软件,包括语音克隆、基于LLM的文本预处理,以及通过将同步输出与视频原始音轨混合,直接将生成的字幕音频保存到视频文件的功能。它力求易于使用和安装 - 具有一键安装程序和图形用户界面。
它利用XTTS、Silero和VoiceCraft模型进行文本到语音转换和语音克隆,通过RVC_CLI提高质量和改善语音克隆结果,并使用NISQA进行音频质量评估。此外,它还整合了Text Generation Webui的API用于本地LLM文本预处理,实现音频生成前的广泛文本处理。
该项目仍处于alpha阶段,而且我并不是一个经验丰富的开发者(事实上,我是个新手),所以在优化、功能和可靠性方面,代码还远远不够完善。请记住这一点,如果您想帮助我改进它,欢迎贡献。
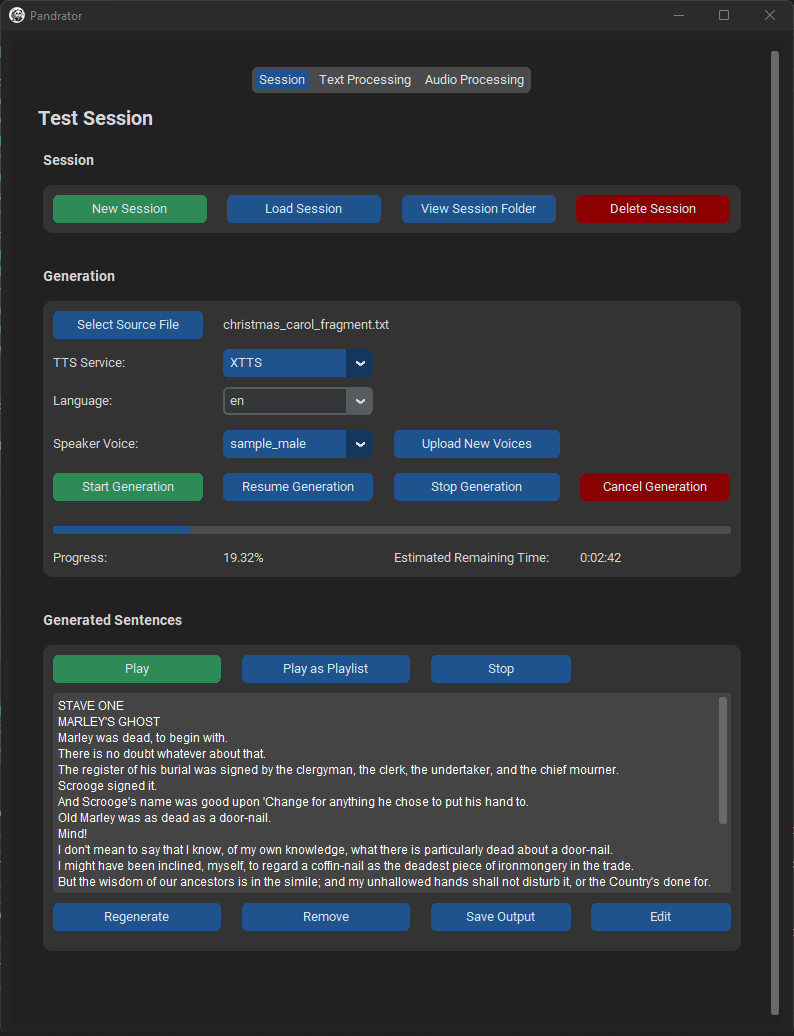
样本
这些样本是使用最小设置生成的 - 没有LLM文本处理、RVC或TTS评估,也没有重新生成句子。XTTS和Silero的生成速度都快于播放速度。
https://github.com/lukaszliniewicz/Pandrator/assets/75737665/76a97cf0-275d-4ea2-868e-95eecdc6f6ce
https://github.com/lukaszliniewicz/Pandrator/assets/75737665/bbb10512-79ed-43ea-bee3-e271b605580e
https://github.com/lukaszliniewicz/Pandrator/assets/75737665/118f5b9c-641b-4edd-8ef6-178dd924a883
要求
硬件
XTTS
我能够在配备Ryzen 5600h和3050笔记本GPU(4GB显存)的笔记本电脑上运行所有功能。您可能需要至少16GB的RAM、一个相当现代的CPU,以及理想情况下4GB+显存的NVIDIA GPU才能获得可用的性能。请参考下列服务的要求。
Silero
Silero在CPU上运行。它应该能在几乎所有相对现代的系统上表现良好。
VoiceCraft
您可以在CPU上运行VoiceCraft,但生成速度会非常慢。要通过GPU(Nvidia)实现有意义的加速,您需要至少8GB显存的GPU。
依赖项
这个项目依赖于几个API和服务(本地运行)以及库,特别是:
必需
- XTTS API Server by daswer123用于使用Coqui XTTSv2进行文本到语音(TTS)生成,或Silero API Server by ouoertheo用于使用Silero模型进行TTS生成,或VoiceCraft by jasonppy。XTTS和VoiceCraft使用GPU(Nvidia),而Silero使用CPU。Silero可以在低端系统上运行。
- FFmpeg用于音频编码。
- Sentence Splitter by mediacloud用于将
.txt文件分割成句子,customtkinter by TomSchimansky,num2words by savoirfairelinux用于将数字转换为单词(Silero需要这个),pysrt,pydub和其他(参见requirements.txt)。
可选
- Text Generation Webui API by oobabooga用于基于LLM的文本预处理。
- RVC_CLI by blaise-tk用于通过基于检索的语音转换提高语音质量和克隆结果。
- NISQA by gabrielmittag用于评估TTS生成(使用FastAPI实现)。
安装
最小化一键安装可执行文件(仅限Windows):
以管理员权限运行pandrator_start_minimal_xtts.exe、pandrator_start_minimal_silero.exe或pandrator_start_minimal_voicecraft.exe。您可以在Releases中找到它们。这些可执行文件是使用pyinstaller从存储库中的pandrator_start_minimal_xtts.py、pandrator_start_minimal_silero.py和pandrator_start_minimal_voicecraft.py创建的。
该文件可能会被防病毒软件标记为威胁,因此您可能需要将其添加为例外。
首次使用时,EXE会创建Pandrator文件夹,安装curl、git、ffmpeg(如果尚未安装,则使用Chocolatey)和Miniconda,克隆XTTS Api Server仓库、Silero Api Server仓库或VoiceCraft API仓库以及Pandrator仓库,创建conda环境,安装依赖项,并启动Pandrator和您选择的服务器。您可以稍后使用EXE来启动Pandrator。
如果您想再次执行设置,请删除它创建的Pandrator文件夹。请至少给予几分钟时间让初始设置过程下载模型并安装依赖项(对我来说大约需要7-10分钟)。
对于额外功能:
- 安装Text Generation Webui,并记得启用API(在启动之前,在Webui主目录的
CMD_FLAGS.txt中添加--api)。 - 设置RVC_CLI以增强生成效果。
- 设置NISQA API以自动评估生成结果。
请参考Dependencies下链接的仓库获取详细安装说明。请记住,必须运行这些API才能使用它们提供的功能。
手动安装:
- 确保Python 3、git、calibre和ffmpeg已安装并添加到PATH中。
- 至少安装并运行XTTS API Server、Silero API Server或VoiceCraft API Server中的一个。
- 克隆此仓库(
git clone https://github.com/lukaszliniewicz/Pandrator.git)。 cd进入仓库目录。- 使用
pip install -r requirements.txt安装依赖项。 - 运行
python pandrator.py。
功能
- 文本预处理: 将文本分割成句子并(尝试)保留段落。支持多种语言的配置文件。
- LLM文本预处理: 利用本地LLM进行文本校正和增强,最多可连续运行三个不同提示,并有一个评估机制,要求模型执行两次任务并选择更好的回应。我一直在使用
openchat-3.5-0106.Q5_K_M.gguf并取得良好效果,也使用过如Mistral 7B Instruct 0.2等模型。不同模型可能在不同任务上表现良好,因此可以为特定提示选择特定模型。 - 音频生成: 将处理后的文本转换为语音,支持声音克隆和质量增强选项。目前支持
.txt、.srt和.pdf文件。 - 音频评估: 一项实验性功能,预测生成句子的平均意见得分(MOS),并设置得分阈值或从一组生成结果中选择最佳得分。
- 生成并添加配音到视频文件: 从字幕文件生成的语音与SRT时间戳同步,可以保存为文件或与视频文件的音轨混合,有效地制作配音。它可以处理生成的语音超出字幕分配时间的情况,并自动纠正同步。可以加快或减慢生成的音频。
- 会话管理: 支持创建、删除和加载会话,以组织工作流程。
- GUI: 使用customtkinker构建,提供用户友好的体验。
快速入门指南
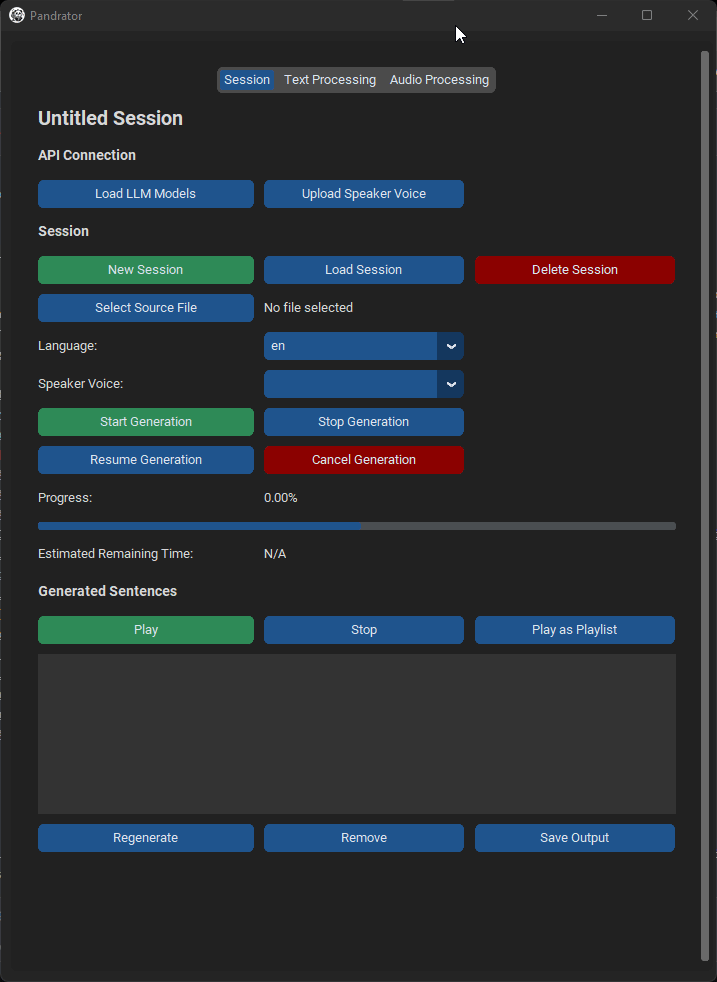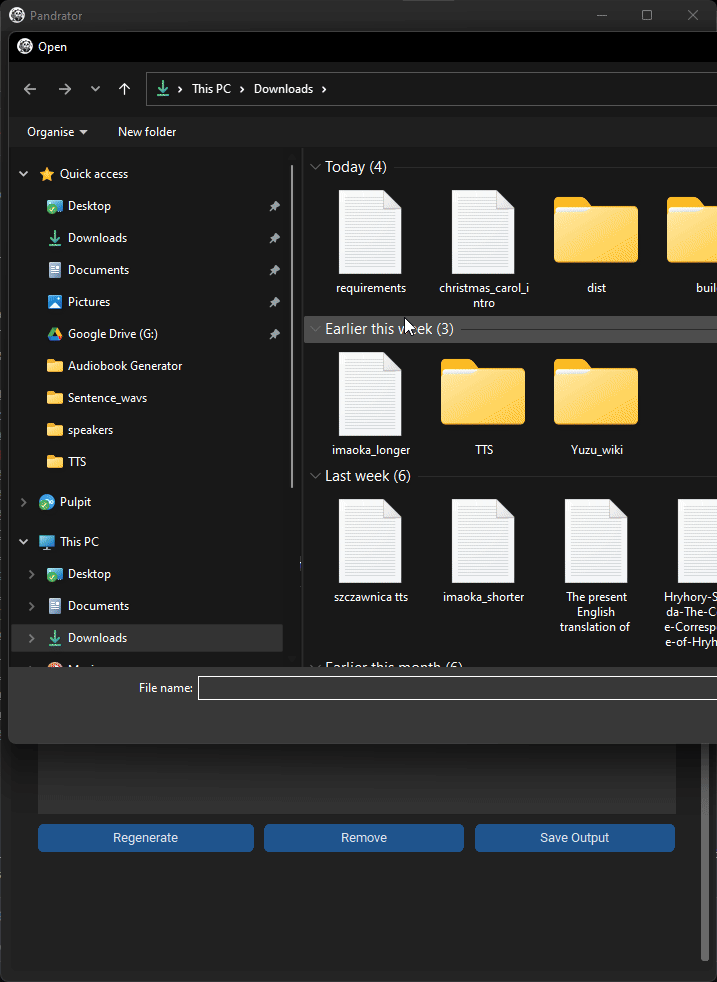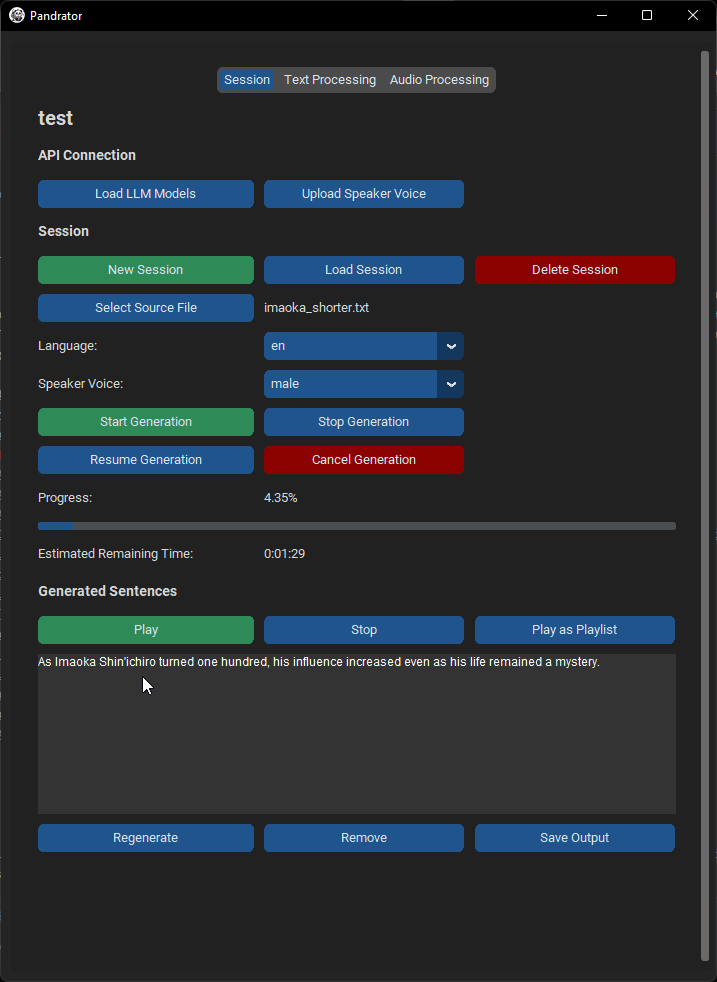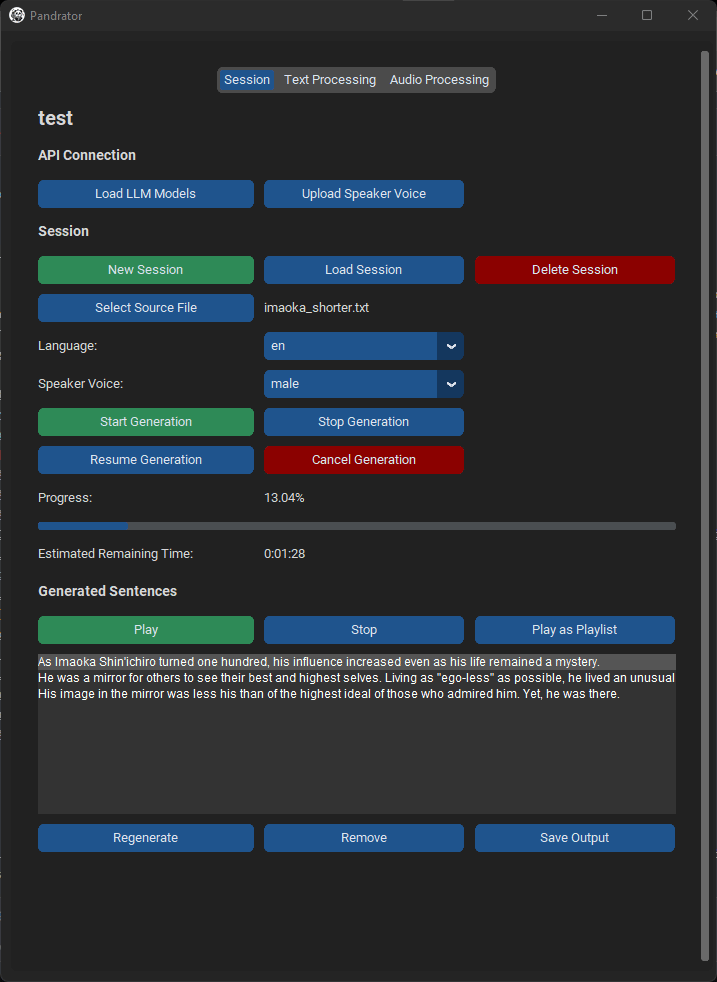
基本使用
如果您不想使用额外功能,在会话标签中就有您需要的所有内容。
- 创建新会话或加载现有会话(选择
Outputs中的文件夹即可)。 - 选择您的
.txt、.srt、.pdf或epub文件。如果您选择PDF或EPUB文件,将打开一个预览窗口显示提取的文本。您可以编辑它(OCR处理的书籍通常会有识别不佳的标题页文本)。非常大的PDF文件可能需要几分钟才能加载。 - 从下拉菜单中选择您想使用的TTS服务器 - XTTS、Silero或VoiceCraft - 以及语言(VoiceCraft目前只支持英语)。
- 选择您想使用的声音。
- XTTS,声音是存储在
tts_voices目录中的短6-12秒.wav文件(22050Hz采样率,单声道)。XTTS模型使用音频来克隆声音。样本使用什么语言并不重要,您将能够生成所有支持语言的语音,但如果您提供目标语言的样本,质量会最好。您可以使用仓库中的样本或上传自己的样本。请确保音频在6到12秒之间,单声道,采样率为22050Hz。您可以使用Audacity等工具准备文件。噪音越少越好。您可以使用Resemble AI等工具在Hugging Face上对样本进行降噪和/或增强。 - Silero为其支持的每种语言提供多个声音。它不支持声音克隆。选择语言后,只需从下拉菜单中选择一个声音即可。
- VoiceCraft的工作方式类似于XTTS,它从
.wav样本中克隆声音。但是,它需要一个格式正确的.wav文件(单声道,16000Hz)和一个包含样本转录内容的.txt文件。这些文件必须具有相同的名称(当然,除了扩展名)。您需要将它们上传到tts_voices/VoiceCraft,然后就可以在GUI中选择它们。目前仅支持英语。如果您第一次使用新声音生成,服务器将执行对齐程序,因此第一个句子的生成会有延迟。再次使用该声音时就不会发生这种情况。
- XTTS,声音是存储在
- 如果需要,您可以减慢或加快生成的音频(输入或选择比率,例如1.1,比生成的快10%;这对配音特别有用)。
- 如果您选择了
.srt文件,您将有选项选择一个视频文件及其中一个音轨与同步输出混合,以及是否在播放字幕音频时降低原始音频的音量。 - 开始生成。您可以停止并稍后恢复,或关闭程序并稍后加载会话。
- 您可以回放生成的句子,也可以作为播放列表播放,编辑它们(用于重新生成的文本),重新生成或删除个别句子。
- "保存输出"将到目前为止生成的句子连接起来,并将它们编码为一个文件(默认为64k比特率的
.opus;您可以在"音频"标签中更改为.wav或.mp3)。
常规音频设置
- 您可以更改添加到句子和段落末尾的静音长度。
- 您可以启用淡入和淡出效果并设置持续时间。
- 您可以选择输出格式和比特率。
通用文本预处理设置
- 你可以禁用/启用长句分割,并设置发送给TTS生成的文本片段的最大长度(默认启用;它会尝试分割超过最大长度值的句子;它会寻找标点符号(, ; : -)并选择最接近句子中点的标点;如果没有标点符号,它会寻找像"and"这样的连词);它会执行两次此操作,因为一些句子片段在仅分割一次后可能仍然太长。
- 你可以禁用/启用短句附加(附加到前面或后面的句子;默认禁用,可能会改善流畅度,因为发送给模型的文本片段长度更加统一)。
- 移除变音符号(当生成包含许多外来词或外国字母音译的文本时很有用,例如日语)。如果你要生成需要变音符号的语言,如德语或波兰语,请不要启用此功能!否则发音会出错。
LLM预处理
- 启用LLM处理,在将文本发送到TTS API之前使用语言模型进行预处理。例如,你可以要求LLM删除OCR痕迹,拼写出缩写,纠正标点等。
- 你可以为文本优化定义最多三个提示。每个提示都会单独发送到LLM API,最后一个提示的输出将用于TTS生成。
- 对于每个提示,你可以启用/禁用它,设置提示文本,选择要使用的LLM模型,以及启用/禁用评估(如果启用,LLM API将为每个提示调用两次,然后再次调用模型以选择更好的结果)。
- 使用会话选项卡中的"加载LLM模型"按钮加载可用的LLM模型。
RVC质量增强和语音克隆
- 启用RVC以增强生成的音频质量并应用语音克隆。
- 使用音频处理选项卡中的"选择RVC模型"和"选择RVC索引"按钮选择RVC模型文件(.pth)和相应的索引文件。
- 启用RVC后,生成的音频将在保存前使用所选的RVC模型和索引进行处理。
NISQA TTS评估
- 启用TTS评估以使用NISQA(非侵入式语音质量评估)模型评估生成音频的质量。
- 设置目标MOS(平均意见得分)值和每个句子的最大尝试次数。
- 启用TTS评估后,将使用NISQA模型评估生成的音频,并为每个句子选择最佳音频(基于MOS得分)。
- 如果在最大尝试次数内未达到目标MOS值,将使用迄今为止生成的最佳音频。
贡献
欢迎提出改进建议和报告错误!
提示
- 你可以在这里找到语音样本集合。它们旨在与ElevenLabs一起使用,因此你需要选取8-12秒的片段,并使用Audacity等工具将其保存为22050khz单声道的
.wav文件。 - 你可以在这里找到RVC模型集合。
待办事项
- 将所有API服务器添加到安装脚本中。
- 添加设置导入/导出功能。
- 添加对文本预处理和TTS生成的专有API支持。
- 包含PDF的OCR功能。
- 添加对更高质量本地TTS模型Tortoise的支持。
- 在GUI中添加录制语音样本并用于TTS的选项。
- 添加从
.srt字幕文件创建配音的工作流程。 - 包含对PDF文件的支持。
- 在UI中集成编辑已处理句子的功能。
- 添加对质量较低但速度更快的本地TTS模型的支持,该模型可以轻松在CPU上运行,如Silero或Piper。
- 添加对EPUB的支持。











