
 访问官网
访问官网 Github
Github 论文
论文MCUNet: 物联网设备上的微型深度学习
这是MCUNet系列的官方实现。
TinyML项目网站 | MCUNetV1 | MCUNetV2 | MCUNetV3

新闻
如果您对获取更新感兴趣,请在这里注册以接收通知!
- (2024/03) 我们发布了新的演示视频,展示了256KB内存下的设备端训练。
- (2023/10) 微型机器学习:进展与未来[专题]发表在IEEE CAS杂志上。
- (2022/12) 我们简化了模型的
net_id(新版本:mcunet-in0,mcunet-vww1等),为即将发布的综述论文做准备(敬请期待!)。 - (2022/10) 我们的新作256KB内存下的设备端训练在MIT主页上得到了重点报道!
- (2022/09) 我们的新作256KB内存下的设备端训练被NeurIPS 2022接收!它实现了物联网设备上的微型设备端训练。
- (2022/08) 我们在这个仓库中发布了TinyEngine的源代码。请查看!
- (2022/08) 我们关于微型机器学习和高效深度学习的新课程将于2022年9月发布:efficientml.ai。
- (2022/07) 我们还包含了上面视频演示中使用的人员检测模型。我们还将在TinyEngine发布中包含部署代码。
- (2022/06) 我们将MCUNet仓库重构为一个独立仓库(之前的仓库:https://github.com/mit-han-lab/tinyml)
- (2021/10) MCUNetV2被NeurIPS 2021接收:https://arxiv.org/abs/2110.15352 !
- (2020/10) MCUNet被NeurIPS 2020接收为聚焦论文:https://arxiv.org/abs/2007.10319 !
- 我们的项目被以下媒体报道:MIT新闻、MIT新闻(v2)、WIRED、Morning Brew、Stacey on IoT、Analytics Insight、Techable等。
概述
微控制器是低成本、低功耗的硬件。它们被广泛部署并有广泛的应用。

但是有限的内存预算(比GPU小50,000倍)使得深度学习部署变得困难。

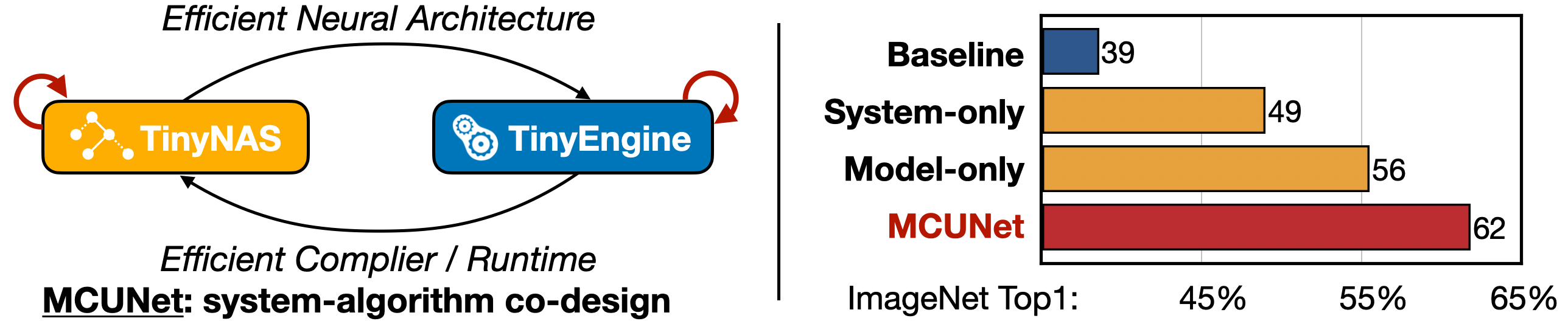
MCUNet是一个用于微控制器上微型深度学习的系统-算法协同设计框架。它由TinyNAS和TinyEngine组成。它们经过协同设计以适应有限的内存预算。
通过系统-算法协同设计,我们可以在相同的微小内存预算下显著提高深度学习性能。
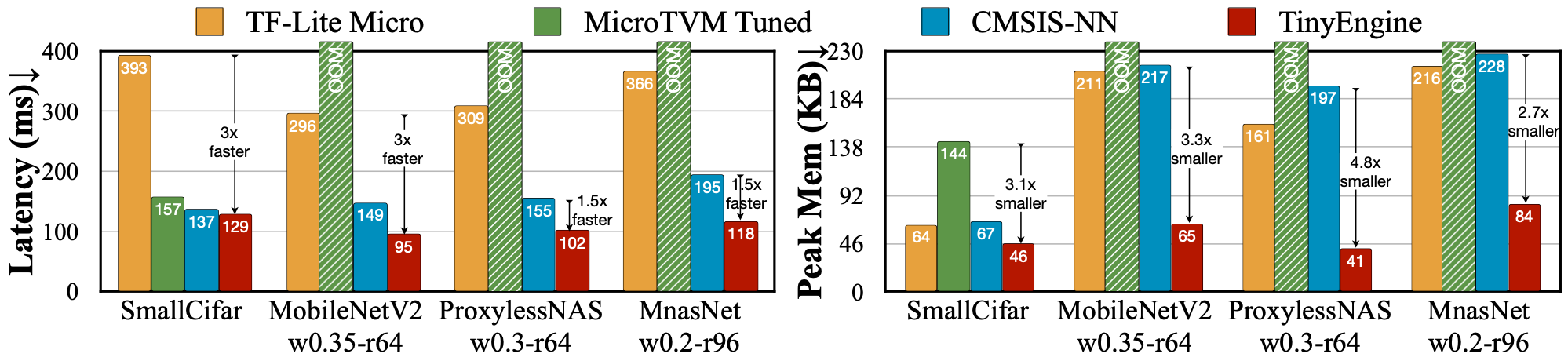
我们的TinyEngine推理引擎可以成为基于MCU的AI应用的有用基础设施。与现有的库如TF-Lite Micro、CMSIS-NN、MicroTVM等相比,它显著提高了推理速度并减少了内存使用。它将推理速度提高了1.5-3倍,并将峰值内存减少了2.7-4.8倍。
模型库
使用方法
您可以构建预训练的PyTorch fp32模型或TF-Lite格式的int8量化模型。
from mcunet.model_zoo import net_id_list, build_model, download_tflite
print(net_id_list) # 模型库中的模型列表
# pytorch fp32模型
model, image_size, description = build_model(net_id="mcunet-in3", pretrained=True) # 您可以用net_id_list中的任何其他选项替换net_id
# 下载tflite文件到tflite_path
tflite_path = download_tflite(net_id="mcunet-in3")
评估
要评估PyTorch fp32模型的准确性,请运行:
python eval_torch.py --net_id mcunet-in2 --dataset {imagenet/vww} --data-dir PATH/TO/DATA/val
要评估TF-Lite int8模型的准确性,请运行:
python eval_tflite.py --net_id mcunet-in2 --dataset {imagenet/vww} --data-dir PATH/TO/DATA/val
模型列表
- 注意,所有的延迟、SRAM和Flash使用量都是在STM32F746上使用TinyEngine进行分析的。
- 这里我们只提供
int8量化模型。int4量化模型(如论文中所示)可以进一步推动准确性-内存权衡,但缺乏通用格式支持。 - 对于准确性(top1, top-5),我们分别报告
fp32/int8模型的准确性
ImageNet模型列表:
| 网络ID | MAC操作数 | 参数数量 | SRAM | Flash | 分辨率 | Top-1准确率 (fp32/int8) | Top-5准确率 (fp32/int8) |
|---|---|---|---|---|---|---|---|
| # 基准模型 | |||||||
| mbv2-w0.35 | 23.5M | 0.75M | 308kB | 862kB | 144 | 49.7%/49.0% | 74.6%/73.8% |
| proxyless-w0.3 | 38.3M | 0.75M | 292kB | 892kB | 176 | 57.0%/56.2% | 80.2%/79.7% |
| # mcunet模型 | |||||||
| mcunet-in0 | 6.4M | 0.75M | 266kB | 889kB | 48 | 41.5%/40.4% | 66.3%/65.2% |
| mcunet-in1 | 12.8M | 0.64M | 307kB | 992kB | 96 | 51.5%/49.9% | 75.5%/74.1% |
| mcunet-in2 | 67.3M | 0.73M | 242kB | 878kB | 160 | 60.9%/60.3% | 83.3%/82.6% |
| mcunet-in3 | 81.8M | 0.74M | 293kB | 897kB | 176 | 62.2%/61.8% | 84.5%/84.2% |
| mcunet-in4 | 125.9M | 1.73M | 456kB | 1876kB | 160 | 68.4%/68.0% | 88.4%/88.1% |
VWW模型列表:
注意VWW数据集可能难以准备。您可以从这里下载我们预构建的minival集,大约380MB。
| 网络ID | MAC操作数 | 参数数量 | SRAM | Flash | 分辨率 | Top-1准确率 (fp32/int8) |
|---|---|---|---|---|---|---|
| mcunet-vww0 | 6.0M | 0.37M | 146kB | 617kB | 64 | 87.4%/87.3% |
| mcunet-vww1 | 11.6M | 0.43M | 162kB | 689kB | 80 | 88.9%/88.9% |
| mcunet-vww2 | 55.8M | 0.64M | 311kB | 897kB | 144 | 91.7%/91.8% |
对于TF-Lite int8模型,我们没有使用量化感知训练(QAT),所以一些结果略低于论文中的数字。
检测模型
我们还分享了在演示中使用的人员检测模型。要在样本图像上可视化模型的预测,请运行以下命令:
python eval_det.py
它将在这里可视化预测结果:assets/sample_images/person_det_vis.jpg。
该模型采用128x160的小输入分辨率以减少内存使用。由于图像和模型大小有限,它无法达到最先进的性能,但应该为tinyML应用提供不错的性能(请查看演示视频记录)。我们还将在即将发布的TinyEngine版本中发布部署代码。
要求
-
Python 3.6+
-
PyTorch 1.4.0+
-
Tensorflow 1.15(如果您想测试TF-Lite模型;仅支持CPU)
致谢
我们感谢麻省理工学院-IBM Watson人工智能实验室、英特尔、亚马逊、索尼、高通、美国国家科学基金会对这项研究的支持。
引用
如果您认为该项目有帮助,请考虑引用我们的论文:
@article{lin2020mcunet,
title={Mcunet: Tiny deep learning on iot devices},
author={Lin, Ji and Chen, Wei-Ming and Lin, Yujun and Gan, Chuang and Han, Song},
journal={Advances in Neural Information Processing Systems},
volume={33},
year={2020}
}
@inproceedings{
lin2021mcunetv2,
title={MCUNetV2: Memory-Efficient Patch-based Inference for Tiny Deep Learning},
author={Lin, Ji and Chen, Wei-Ming and Cai, Han and Gan, Chuang and Han, Song},
booktitle={Annual Conference on Neural Information Processing Systems (NeurIPS)},
year={2021}
}
@article{
lin2022ondevice,
title = {On-Device Training Under 256KB Memory},
author = {Lin, Ji and Zhu, Ligeng and Chen, Wei-Ming and Wang, Wei-Chen and Gan, Chuang and Han, Song},
journal = {arXiv:2206.15472 [cs]},
url = {https://arxiv.org/abs/2206.15472},
year = {2022}
}
相关项目
使用不到256KB内存的设备上训练 (NeurIPS'22)
TinyTL:减少内存而非参数以实现高效的设备上学习 (NeurIPS'20)
Once for All:训练一个网络并针对高效部署进行专门化 (ICLR'20)
ProxylessNAS:在目标任务和硬件上直接进行神经架构搜索 (ICLR'19)
AutoML用于架构高效和专门化的神经网络 (IEEE Micro)
AMC:移动设备上模型压缩和加速的AutoML (ECCV'18)
HAQ:硬件感知自动化量化 (CVPR'19, 口头报告)











