![]()
![]()
![]()
![]()
![]()
![]()
V2V-PoseNet: 基于体素到体素预测网络的单深度图精确3D手部和人体姿态估计
V2V-PoseNet的PyTorch重新实现可在dragonbook的仓库中获得。
感谢dragonbook的重新实现。欢迎其他版本的V2V-PoseNet实现!
简介
这是我们论文《V2V-PoseNet: 基于体素到体素预测网络的单深度图精确3D手部和人体姿态估计》(CVPR 2018)的项目仓库。
我们SNU CVLAB团队(首尔国立大学计算机视觉实验室的Gyeongsik Moon、Juyong Chang和Kyoung Mu Lee)是HANDS2017挑战赛基于帧的3D手部姿态估计的获胜者。
详情请参阅我们的论文。
如果您在研究或出版物中使用了我们的工作,请引用我们的论文:
[1] Moon, Gyeongsik, Ju Yong Chang, and Kyoung Mu Lee. "V2V-PoseNet: 基于体素到体素预测网络的单深度图精确3D手部和人体姿态估计." CVPR 2018. [arXiv]
@InProceedings{Moon_2018_CVPR_V2V-PoseNet,
author = {Moon, Gyeongsik and Chang, Juyong and Lee, Kyoung Mu},
title = {V2V-PoseNet: Voxel-to-Voxel Prediction Network for Accurate 3D Hand and Human Pose Estimation from a Single Depth Map},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2018}
}
在本仓库中,我们提供
- 我们的模型架构描述(V2V-PoseNet)
- HANDS2017基于帧的3D手部姿态估计挑战赛结果
- 与之前最先进方法的比较
- 训练代码
- 我们使用的数据集(ICVL、NYU、MSRA、ITOP)
- 训练好的模型和估计结果
- 3D手部和人体姿态估计示例
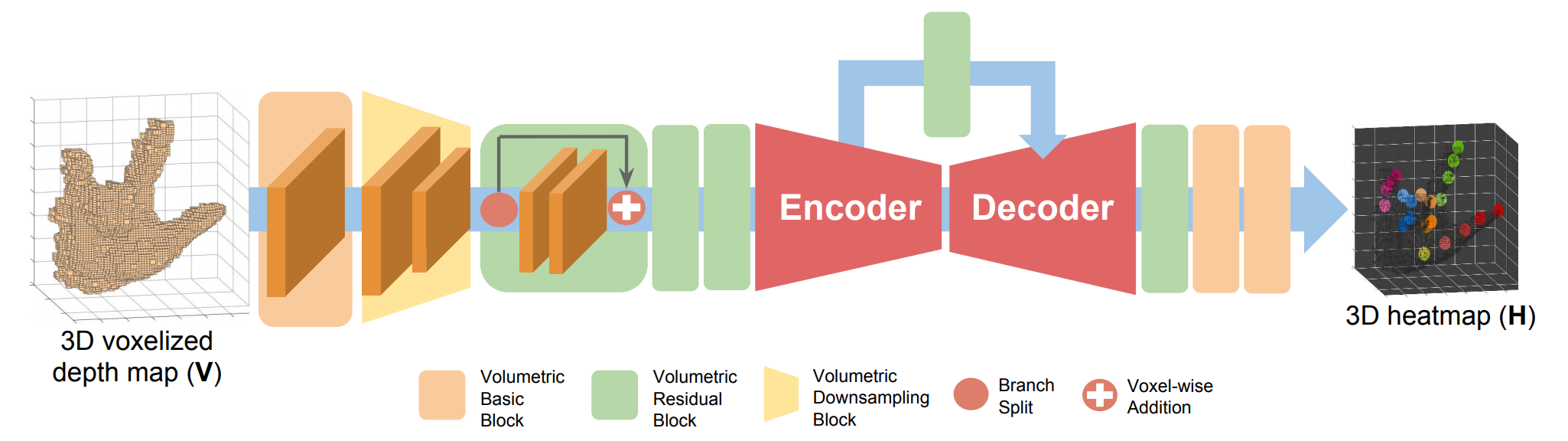
模型架构
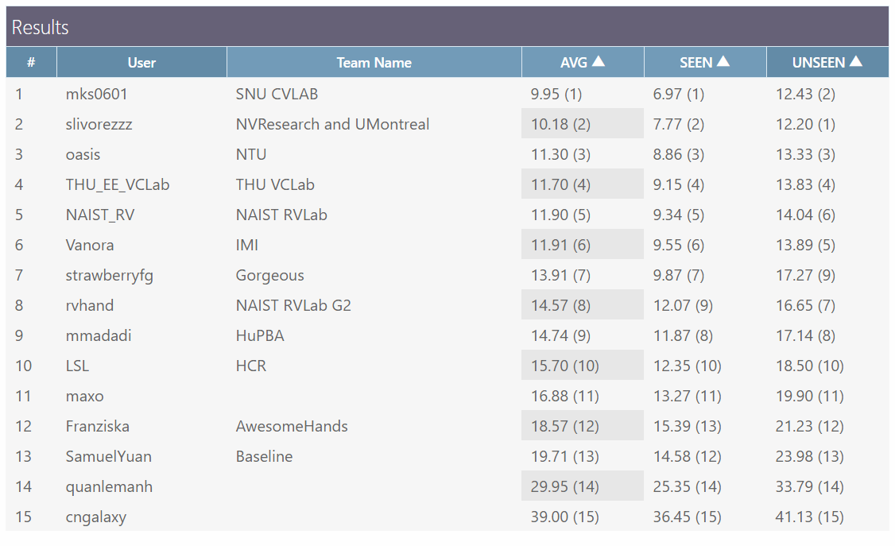
HANDS2017基于帧的3D手部姿态估计挑战赛结果
与之前最先进方法的比较
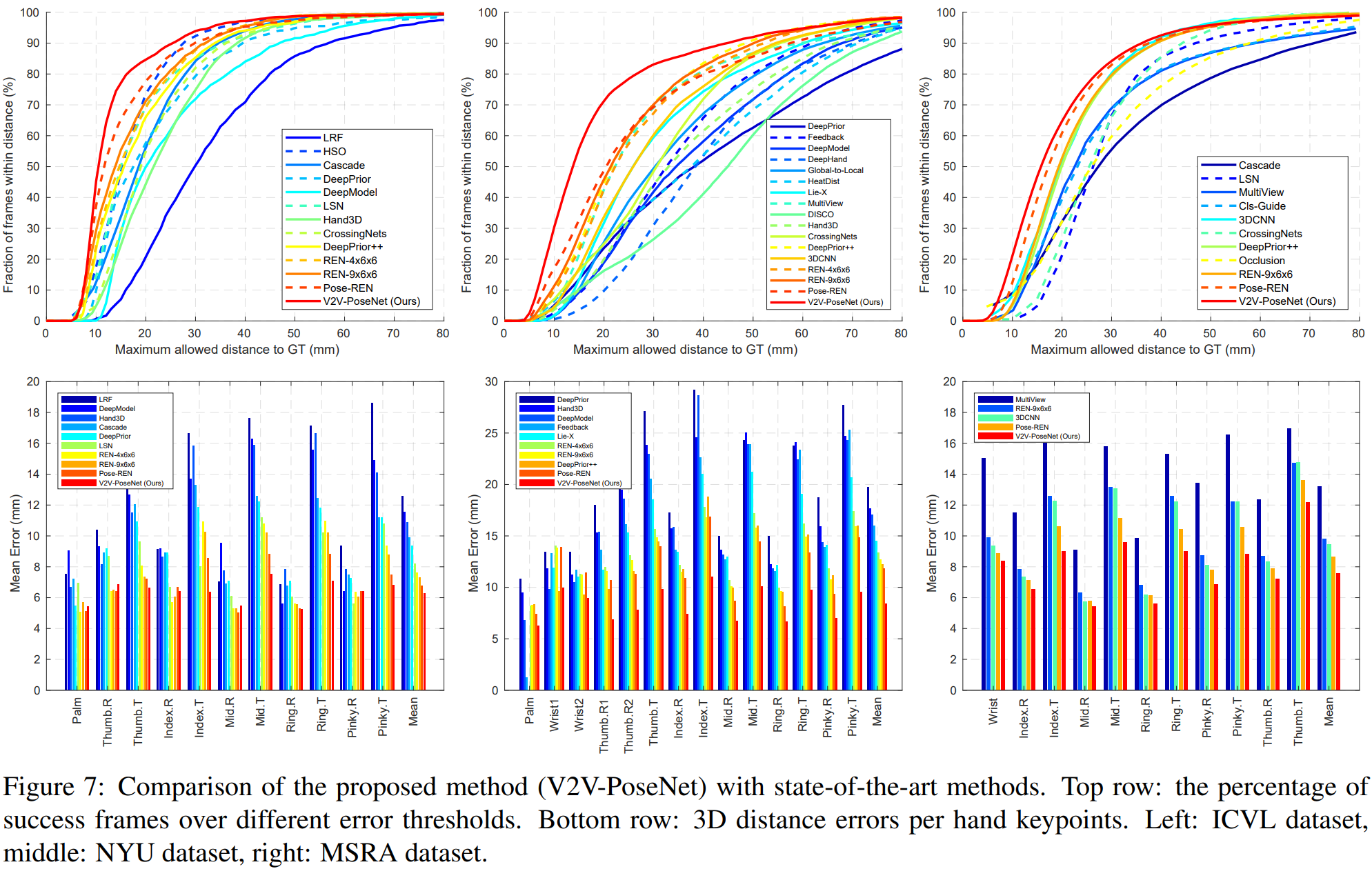
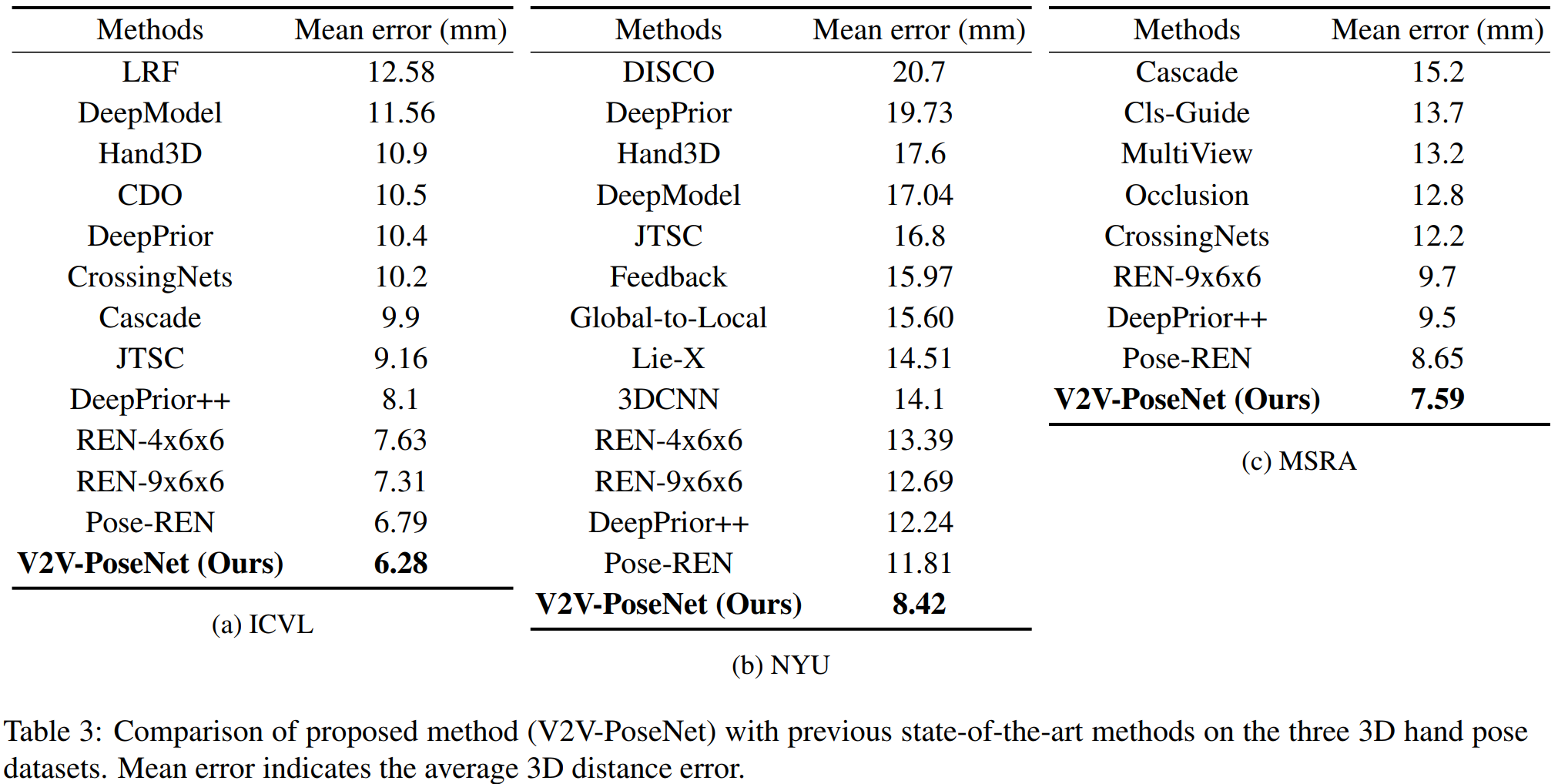
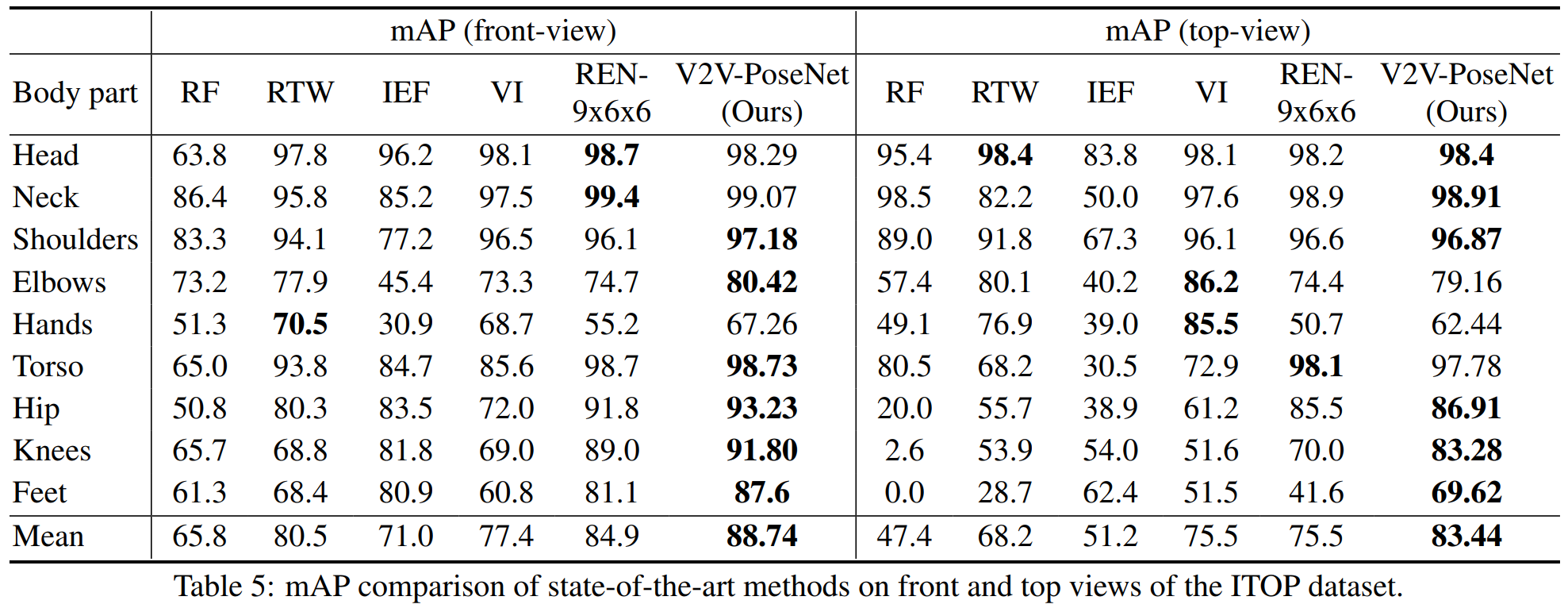
关于我们的代码
依赖
我们的代码在Ubuntu 14.04和16.04环境下使用Titan X GPU(12GB VRAM)进行测试。
代码
将此仓库克隆到您想要的任何位置。您可以参考以下示例。
makeReposit = [/the/directory/as/you/wish]
mkdir -p $makeReposit/; cd $makeReposit/
git clone https://github.com/mks0601/V2V-PoseNet_RELEASE.git
src文件夹包含用于数据加载器、训练器、测试器和其他实用程序的lua脚本文件。data文件夹包含将图像文件转换为二进制文件的数据转换器。
要训练我们的模型,请在src目录中运行以下命令:
th rum_me.lua
- 在config.lua中有一些可选的配置,您可以进行调整。
- 您必须通过运行
data文件夹中的代码将ICVL、NYU和HANDS 2017数据集的.png图像转换为.bin文件。 - 您必须放置数据集文件和每帧计算中心的目录在
src/data/dataset_name/data.lua中定义。 - 可视化代码终于上传了!您必须为每个数据集准备'result_pixel.txt'。结果文件的每一行必须包含所有关节的像素坐标x、y和深度(即x1 y1 z1 x2 y2 z2 ...)。然后运行pixel2world脚本并运行draw_DB.m
数据集
我们在四个3D手部姿态估计数据集和一个3D人体姿态估计数据集上训练和测试了我们的模型。
- ICVL手部姿势数据集 [链接] [论文]
- NYU手部姿势数据集 [链接] [论文]
- MSRA手部姿势数据集 [链接] [论文]
- HANDS2017挑战赛数据集 [链接] [论文] [挑战基准论文]
- ITOP人体姿势数据集 [链接] [论文]
结果
在这里,我们提供ICVL、NYU、MSRA、HANDS2017和ITOP数据集的预计算中心、估计的3D坐标和预训练模型。您可以在这里下载预计算中心和3D手部姿势结果,在这里下载预训练模型。
预计算中心是通过训练DeepPrior++的手部中心估计网络获得的。每行代表每帧的3D世界坐标。 对于ICVL、NYU、MSRA和HANDS2017数据集,如果深度图不存在或不包含手,则该帧被视为无效。 对于ITOP数据集,如果某一帧的'valid'变量为false,则该帧被视为无效。 所有测试图像都被视为有效。
在ICVL、NYU和MSRA数据集上估计的3D坐标是像素坐标,在HANDS2017和ITOP数据集上估计的3D坐标是世界坐标。估计结果来自集成模型。您可以通过下载预训练模型并对其进行测试来获得单个模型的结果。
我们使用awesome-hand-pose-estimation来评估V2V-PoseNet在ICVL、NYU和MSRA数据集上的准确性。
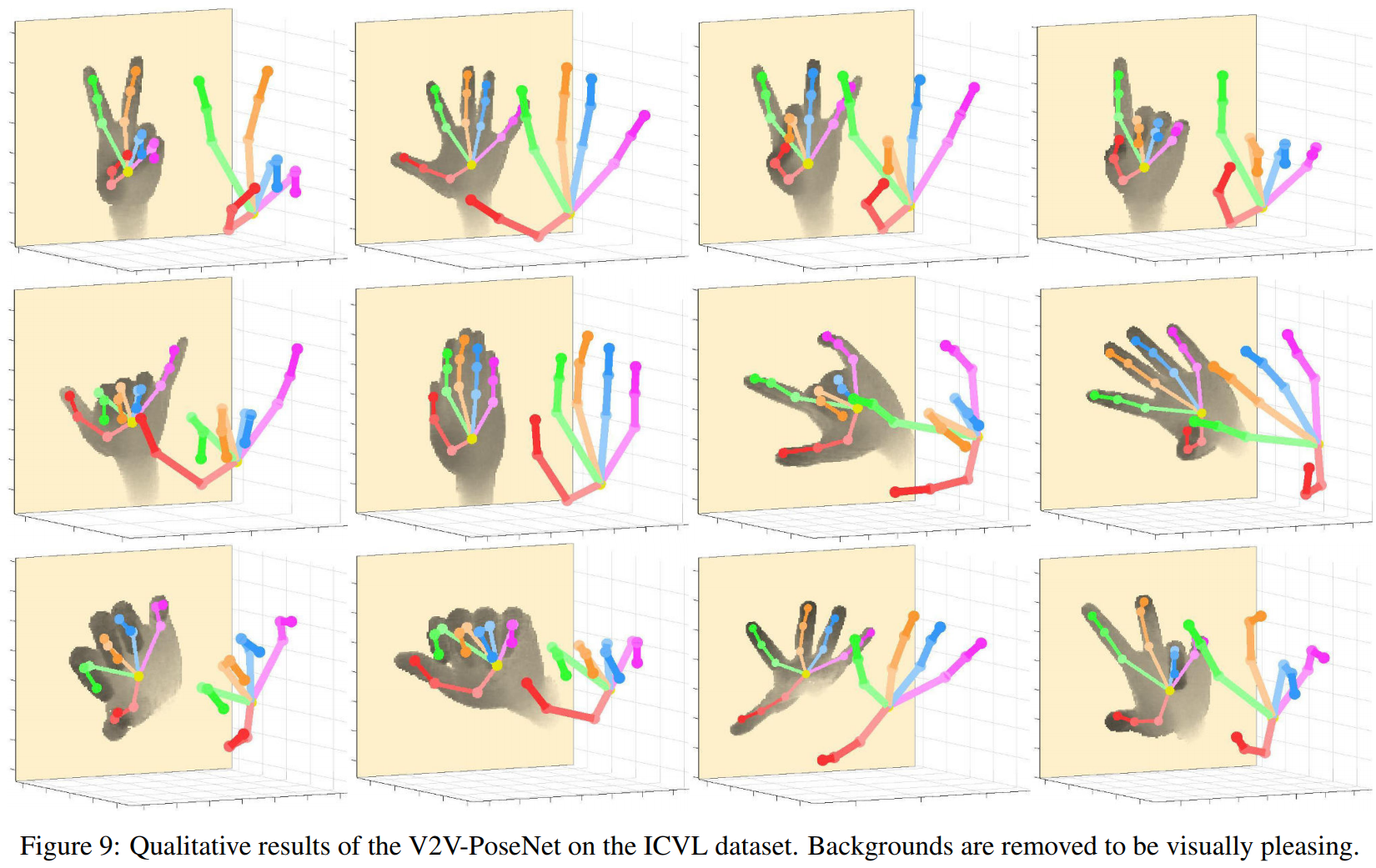
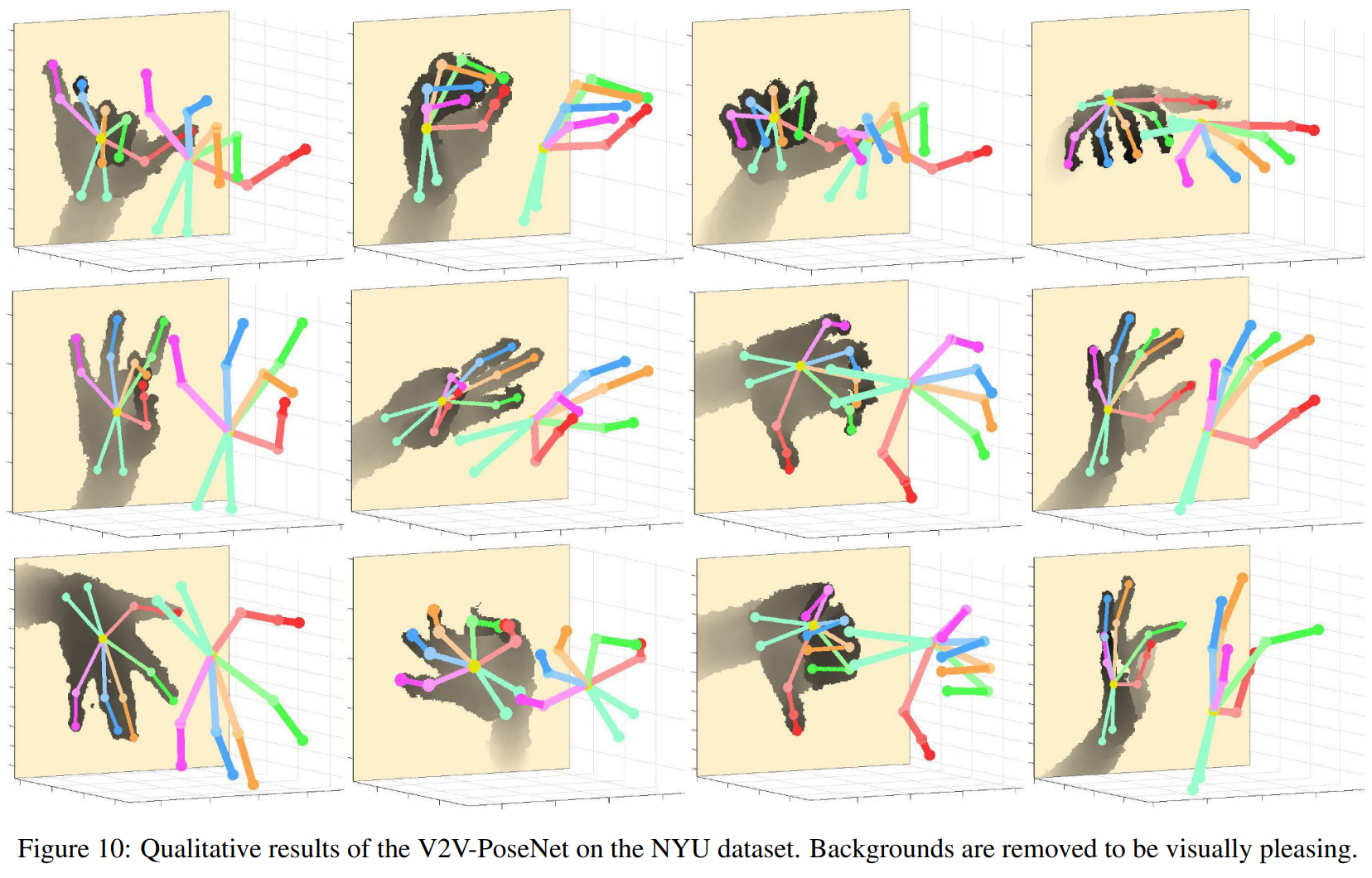
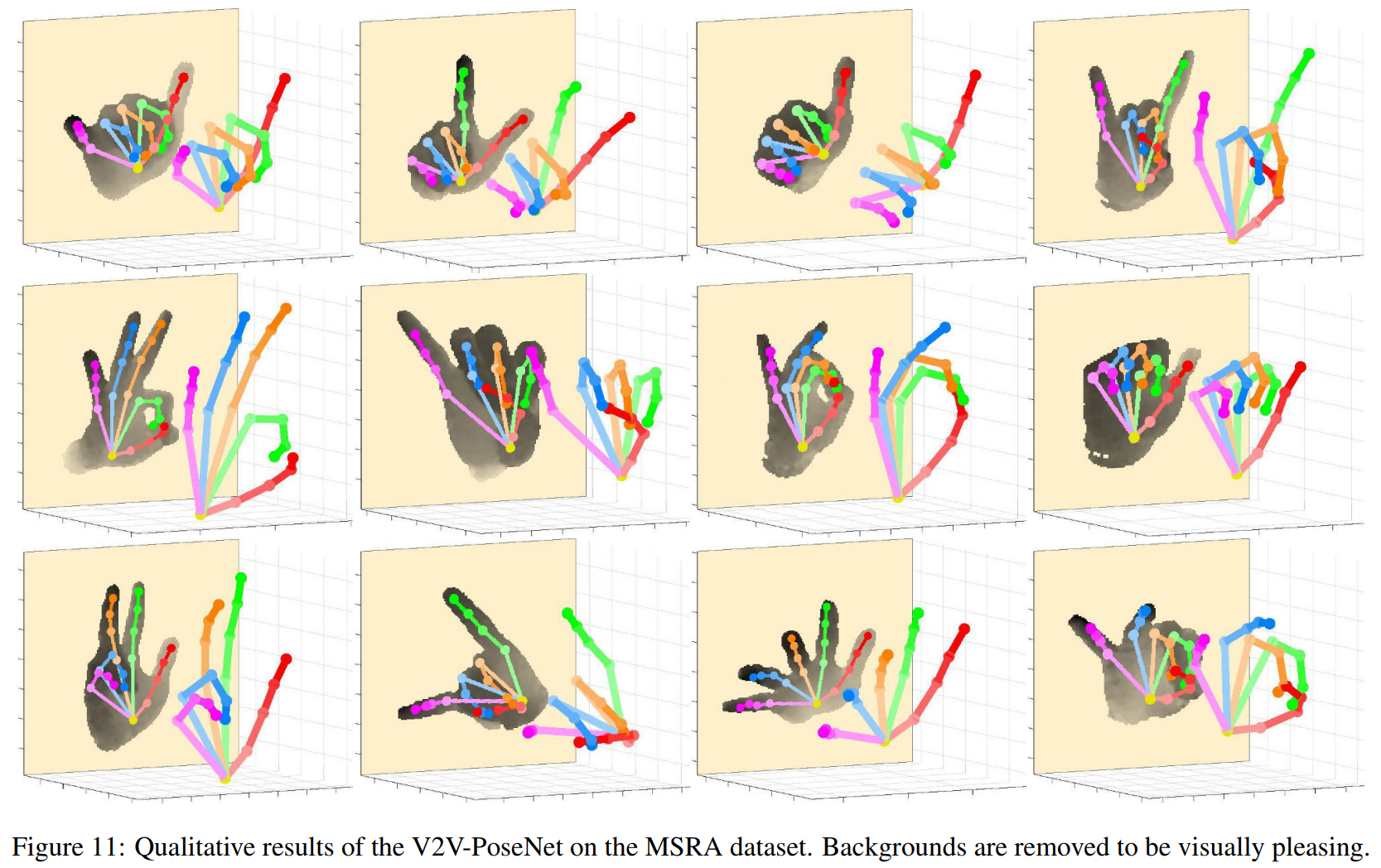
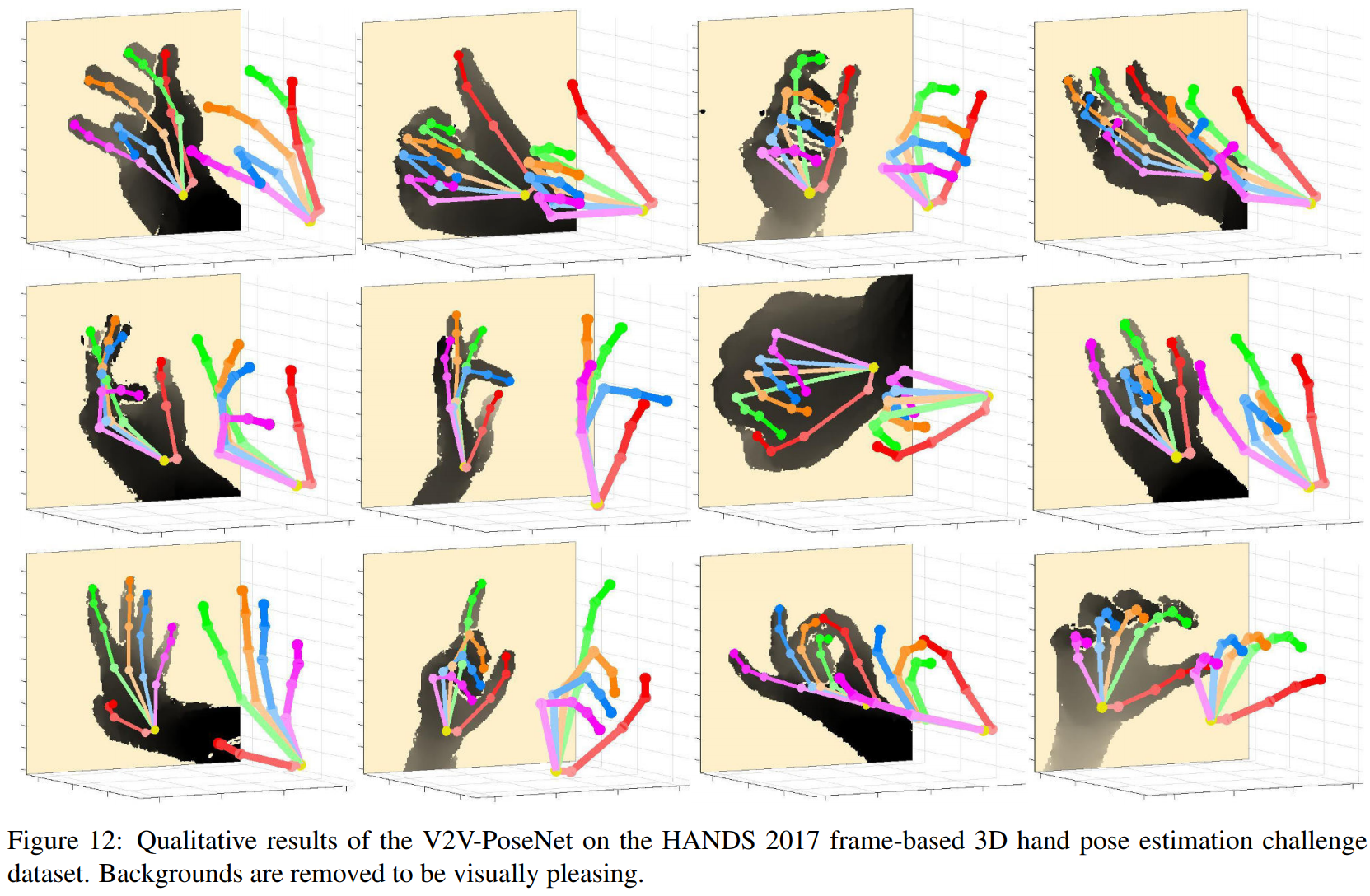
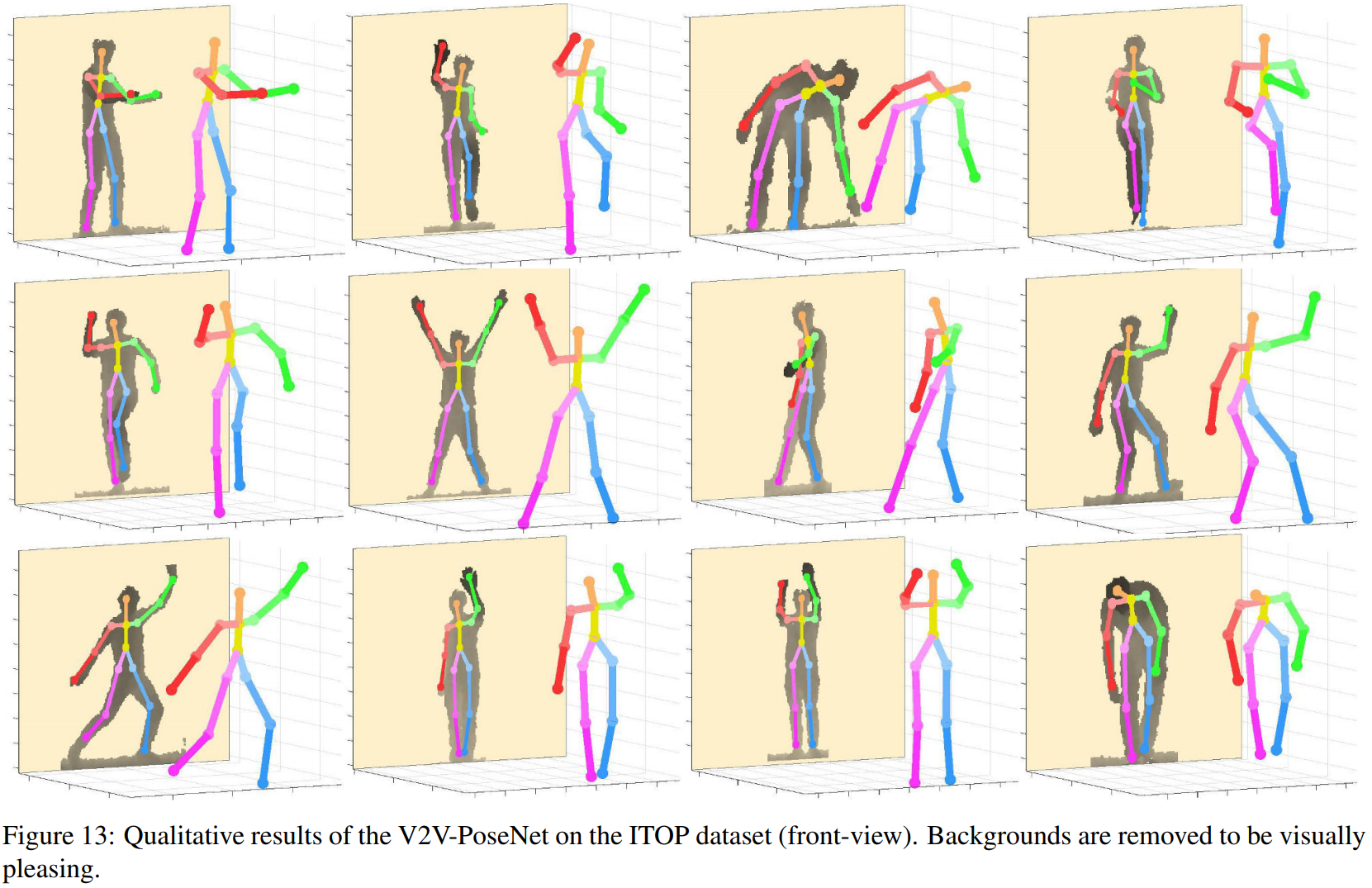
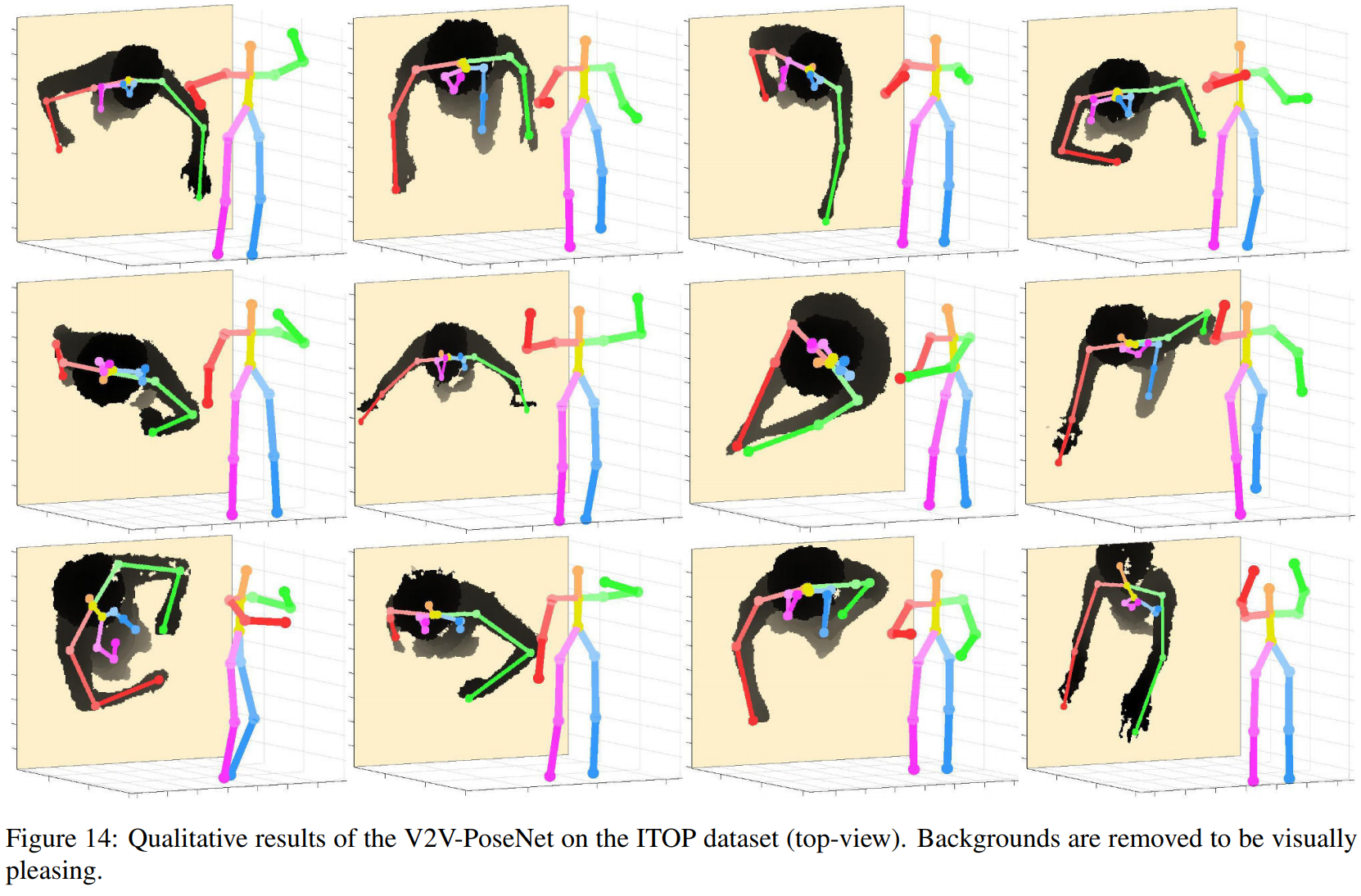
以下是定性结果。