
 访问官网
访问官网 Github
Github 论文
论文GET3D:从图像学习高质量三维纹理形状的生成模型 (NeurIPS 2022)
官方 PyTorch 实现
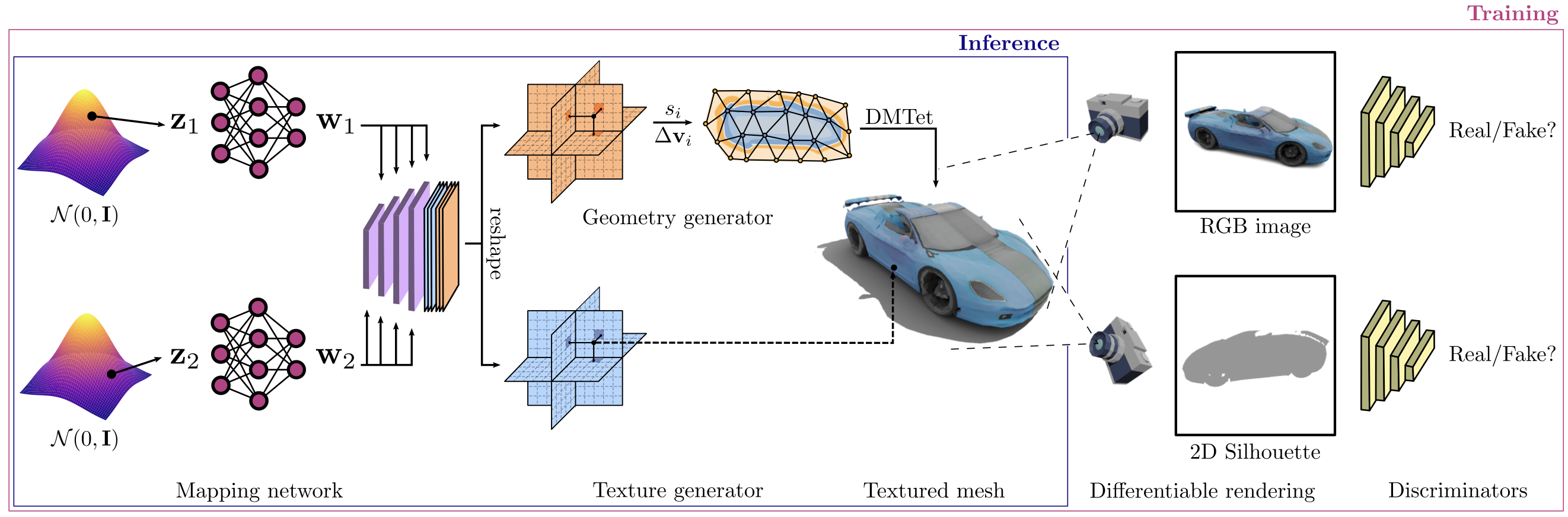
GET3D:从图像学习高质量三维纹理形状的生成模型
Jun Gao
, Tianchang Shen
, Zian Wang,
Wenzheng Chen, Kangxue Yin
, Daiqing Li,
Or Litany, Zan Gojcic,
Sanja Fidler
论文
, 项目页面
摘要:随着多个行业向大规模三维虚拟世界建模发展,对能够在三维内容的数量、质量和多样性方面扩展的内容创作工具的需求变得越来越明显。在我们的工作中,我们旨在训练高性能的三维生成模型,合成可直接被三维渲染引擎使用的纹理网格,从而可立即用于下游应用。先前的三维生成建模工作要么缺乏几何细节,要么在可产生的网格拓扑结构上受限,通常不支持纹理,或者在合成过程中使用神经渲染器,这使得它们在常见的三维软件中的使用变得复杂。在本工作中,我们引入了GET3D,这是一个直接生成具有复杂拓扑结构、丰富几何细节和高保真纹理的显式纹理三维网格的生成模型。我们结合了可微表面建模、可微渲染以及二维生成对抗网络的最新成果,从二维图像集合中训练我们的模型。GET3D能够生成高质量的三维纹理网格,范围涵盖汽车、椅子、动物、摩托车和人物角色到建筑物,相比先前的方法取得了显著的改进。

如需商业咨询,请访问我们的网站并提交表单:NVIDIA 研究许可
新闻
- 2023-09-15:我们增加了对FlexiCubes的支持,可作为DMTet的替代方案。更多详情请参阅此章节。
- 2022-10-13:Shapenet预训练模型发布!查看更多详情此处
- 2022-09-29:代码发布!
- 2022-09-22:代码将于下周上传!
要求
- 出于性能和兼容性考虑,我们推荐使用Linux。
- 1-8块高端NVIDIA GPU。我们使用V100或A100 GPU进行所有测试和开发。
- 64位Python 3.8和PyTorch 1.9.0。PyTorch安装说明请参见 https://pytorch.org。
- CUDA工具包11.1或更高版本。(为什么需要单独安装CUDA工具包?我们使用了StyleGAN3仓库中的自定义CUDA扩展。请参阅故障排除)。
- 我们还建议按照官方仓库的说明安装Nvdiffrast,并安装Kaolin。
- 我们提供了一个脚本来安装软件包。
通过Docker使用服务器
- 构建Docker镜像
cd docker
chmod +x make_image.sh
./make_image.sh get3d:v1
- 启动交互式Docker容器:
docker run --gpus device=all -it --rm -v 你的本地文件夹:挂载文件夹 -it get3d:v1 bash
准备数据集
GET3D在合成数据集上进行训练。我们为Shapenet提供了渲染脚本。请参阅readme下载shapenet数据集并渲染它。
使用FlexiCubes
我们集成了FlexiCubes,这是我们最新的高质量等值面表示。要将FlexiCubes作为DMTet的替代方案用于等值面提取,只需在以下训练和推理命令中添加--iso_surface flexicubes。
训练模型
克隆gitlab代码和必要文件:
cd 你的代码路径
git clone git@github.com:nv-tlabs/GET3D.git
cd GET3D; mkdir cache; cd cache
wget https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/metrics/inception-2015-12-05.pkl
训练模型
cd 你的代码路径
export PYTHONPATH=$PWD:$PYTHONPATH
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
- 在汽车、摩托车或椅子上训练统一生成器(附录中的改进生成器):
python train_3d.py --outdir=日志路径 --data=渲染图像路径 --camera_path 渲染相机路径 --gpus=8 --batch=32 --gamma=40 --data_camera_mode shapenet_car --dmtet_scale 1.0 --use_shapenet_split 1 --one_3d_generator 1 --fp32 0
python train_3d.py --outdir=日志路径 --data=渲染图像路径 --camera_path 渲染相机路径 --gpus=8 --batch=32 --gamma=80 --data_camera_mode shapenet_motorbike --dmtet_scale 1.0 --use_shapenet_split 1 --one_3d_generator 1 --fp32 0
python train_3d.py --outdir=日志路径 --data=渲染图像路径 --camera_path 渲染相机路径 --gpus=8 --batch=32 --gamma=400 --data_camera_mode shapenet_chair --dmtet_scale 0.8 --use_shapenet_split 1 --one_3d_generator 1 --fp32 0
- 如果想要训练单独的生成器(论文中的主要图表):
python train_3d.py --outdir=日志路径 --data=渲染图像路径 --camera_path 渲染相机路径 --gpus=8 --batch=32 --gamma=40 --data_camera_mode shapenet_car --dmtet_scale 1.0 --use_shapenet_split 1 --one_3d_generator 0
python train_3d.py --outdir=日志路径 --data=渲染图像路径 --camera_path 渲染相机路径 --gpus=8 --batch=32 --gamma=80 --data_camera_mode shapenet_motorbike --dmtet_scale 1.0 --use_shapenet_split 1 --one_3d_generator 0
python train_3d.py --outdir=日志路径 --data=渲染图像路径 --camera_path 渲染相机路径 --gpus=8 --batch=32 --gamma=3200 --data_camera_mode shapenet_chair --dmtet_scale 0.8 --use_shapenet_split 1 --one_3d_generator 0
如果想先调试模型,可以通过以下方式将GPU数量减少到1,批量大小减少到4:
--gpus=1 --batch=4
推理
对预训练模型进行推理以进行可视化
- 从此处下载预训练模型。
- 推理可以在具有16 GB内存的单个GPU上运行。
python train_3d.py --outdir=save_inference_results/shapenet_car --gpus=1 --batch=4 --gamma=40 --data_camera_mode shapenet_car --dmtet_scale 1.0 --use_shapenet_split 1 --one_3d_generator 1 --fp32 0 --inference_vis 1 --resume_pretrain 模型路径
python train_3d.py --outdir=save_inference_results/shapenet_chair --gpus=1 --batch=4 --gamma=40 --data_camera_mode shapenet_chair --dmtet_scale 0.8 --use_shapenet_split 1 --one_3d_generator 1 --fp32 0 --inference_vis 1 --resume_pretrain 模型路径
python train_3d.py --outdir=save_inference_results/shapenet_motorbike --gpus=1 --batch=4 --gamma=40 --data_camera_mode shapenet_motorbike --dmtet_scale 1.0 --use_shapenet_split 1 --one_3d_generator 1 --fp32 0 --inference_vis 1 --resume_pretrain 模型路径
-
要生成带纹理的网格,请在推理命令中添加一个选项:
--inference_to_generate_textured_mesh 1 -
要生成具有潜在代码插值的结果,请在推理命令中添加一个选项:
--inference_save_interpolation 1
评估指标
计算FID
- 要使用FID指标评估模型,请在推理命令中添加一个选项:
--inference_compute_fid 1
计算LFD和CD的COV和MMD分数
- 首先生成用于评估的3D对象,在推理命令中添加一个选项:
--inference_generate_geo 1 - 按照README计算指标。
许可证
版权所有 © 2022,NVIDIA Corporation及其附属公司。保留所有权利。
本作品根据Nvidia源代码许可证提供。
更广泛的信息
GET3D基于几项先前的工作:
- Learning Deformable Tetrahedral Meshes for 3D Reconstruction (NeurIPS 2020)
- Deep Marching Tetrahedra: a Hybrid Representation for High-Resolution 3D Shape Synthesis (NeurIPS 2021)
- Extracting Triangular 3D Models, Materials, and Lighting From Images (CVPR 2022)
- EG3D: Efficient Geometry-aware 3D Generative Adversarial Networks (CVPR 2022)
- DIB-R++: Learning to Predict Lighting and Material with a Hybrid Differentiable Renderer (NeurIPS 2021)
- Nvdiffrast – Modular Primitives for High-Performance Differentiable Rendering (SIGRAPH Asia 2020)
引用
@inproceedings{gao2022get3d,
title={GET3D: A Generative Model of High Quality 3D Textured Shapes Learned from Images},
author={Jun Gao and Tianchang Shen and Zian Wang and Wenzheng Chen and Kangxue Yin
and Daiqing Li and Or Litany and Zan Gojcic and Sanja Fidler},
booktitle={Advances In Neural Information Processing Systems},
year={2022}
}











