
 Github
Github 论文
论文Keras TCN
Keras 时序卷积网络. [论文]
经测试支持 Tensorflow 2.9, 2.10, 2.11, 2.12, 2.13, 2.14 和 2.15 (2023 年 11 月 17 日)。



pip install keras-tcn
pip install keras-tcn --no-dependencies # 如果你已经有 TF/Numpy,可以不安装依赖。
对于 MacOS M1 用户:pip install --no-binary keras-tcn keras-tcn。--no-binary 选项将强制 pip 下载源代码(tar.gz)并在本地重新编译。同时,请确保 grpcio 和 h5py 正确安装。网上有一些教程可以参考。
为什么选择 TCN(时序卷积网络)而不是 LSTM/GRU?
- TCN 与相同容量的循环架构相比,具有更长的记忆。
- 在长时间序列任务(例如 Seq. MNIST,Adding Problem,Copy Memory,Word-level PTB 等)上表现优于 LSTM/GRU。
- 并行性(卷积层),灵活的感受野大小(模型的查看范围),稳定的梯度(相比于时间反向传播,梯度消失问题)……
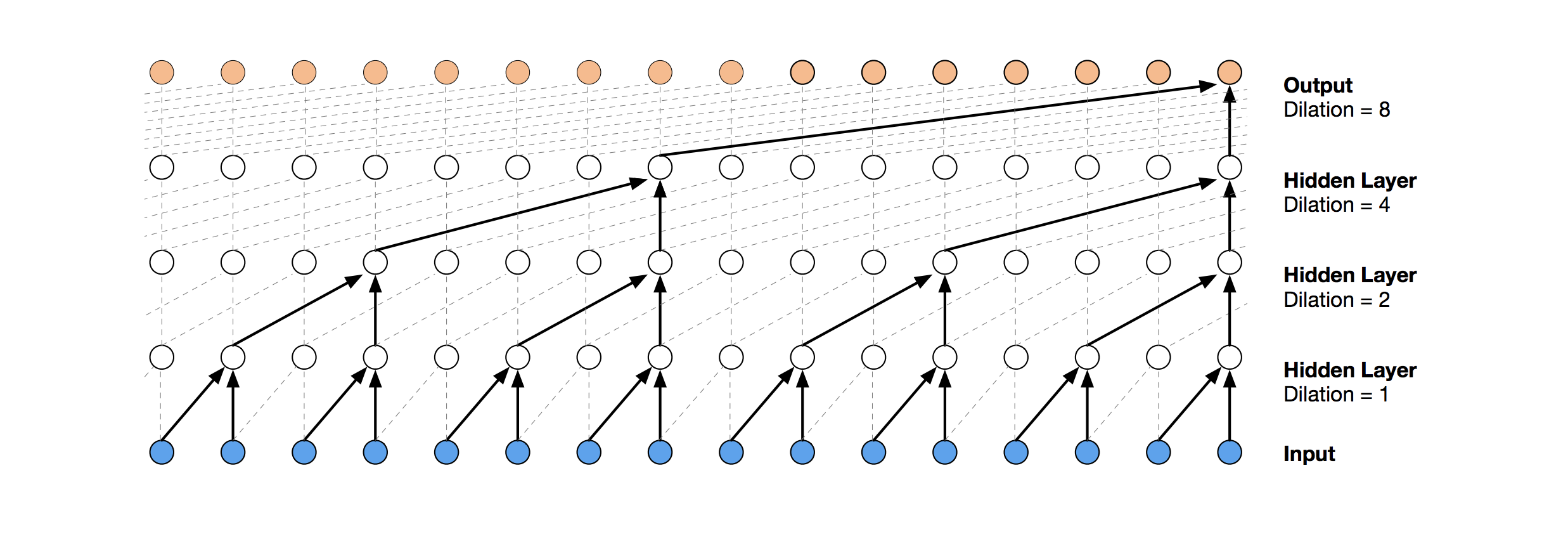 一堆膨胀因果卷积层的可视化(Wavenet,2016)
一堆膨胀因果卷积层的可视化(Wavenet,2016)
TCN 层
TCN 类
TCN(
nb_filters=64,
kernel_size=3,
nb_stacks=1,
dilations=(1, 2, 4, 8, 16, 32),
padding='causal',
use_skip_connections=True,
dropout_rate=0.0,
return_sequences=False,
activation='relu',
kernel_initializer='he_normal',
use_batch_norm=False,
use_layer_norm=False,
use_weight_norm=False,
go_backwards=False,
return_state=False,
**kwargs
)
参数说明
nb_filters: 整数。卷积层使用的滤波器数量。类似于 LSTM 的units。可以是一个列表。kernel_size: 整数。每个卷积层使用的内核大小。dilations: 列表/元组。扩张列表。示例:[1, 2, 4, 8, 16, 32, 64]。nb_stacks: 整数。使用残差块堆叠的数量。padding: 字符串。卷积使用的填充方式。‘causal’表示因果网络(在原始实现中)和 ‘same’表示非因果网络。use_skip_connections: 布尔值。是否添加从输入到每个残差块的跳跃连接。return_sequences: 布尔值。是返回输出序列的最后一个输出,还是返回整个序列。dropout_rate: 介于 0 和 1 之间的浮点数。丢弃输入单元的比例。activation: 残差块中使用的激活函数 o = activation(x + F(x))。kernel_initializer: 内核权重矩阵(Conv1D)的初始化配置。use_batch_norm: 是否在残差层中使用批量归一化。use_layer_norm: 是否在残差层中使用层归一化。use_weight_norm: 是否在残差层中使用权重归一化。go_backwards: (默认False) 布尔值。如果为 True,向后处理输入序列并返回反转的序列。return_state: 布尔值。是否除了输出外返回最后的状态。默认:False。kwargs: 其它配置父类 Layer 的参数。例如 “name=str”, 模型名称。使用多个 TCN 时使用唯一名称。
输入形状
3D 张量,形状为 (batch_size, timesteps, input_dim)。
timesteps 可以为 None。当每个序列长度不同时,这会很有用:多个长度序列示例。
输出形状
- 如果
return_sequences=True:3D 张量,形状为(batch_size, timesteps, nb_filters)。 - 如果
return_sequences=False:2D 张量,形状为(batch_size, nb_filters)。
如何选择正确的参数来配置我的 TCN 层?
以下是我在使用 TCN 时的一些经验笔记:
-
nb_filters: 这是任何卷积网络架构中都存在的。它与模型的预测能力和网络大小有关。除非开始过拟合,否则越多越好。它也类似于 LSTM/GRU 架构中的单元数。 -
kernel_size: 控制卷积操作中考虑的空间区域/体积。通常,2 到 8 之间的值是好的。如果你认为序列在 t-1 和 t-2 上严重依赖,但在其余部分上较少依赖,则选择 2/3 的内核大小。对于 NLP 任务,我们更喜欢更大的内核大小。较大的内核大小将使你的网络更大。 -
dilations: 它控制 TCN 层的深度。通常,考虑以二的倍数列表。你可以通过匹配(TCN 的)感受野和序列中特征的长度来猜测需要多少扩展。例如,如果你的输入序列是周期性的,你可能希望有这个周期的倍数作为扩展。 -
nb_stacks: 除非你的序列非常长(如有数十万个时间步的波形),否则不太有用。 -
padding: 我只使用causal,因为 TCN 代表时序卷积网络。因果填充可以防止信息泄漏。 -
use_skip_connections: 跳跃连接类似于 DenseNet 中的层连接。它有助于梯度流动。除非性能下降,否则你应始终启用它。 -
return_sequences: 与 LSTM 层中的相同。参阅 Keras 文档了解此参数。 -
dropout_rate: 类似于 LSTM 层的recurrent_dropout。我通常不怎么使用它。或者将其设为较低的值,如0.05。 -
activation: 保持默认值。我从未更改过它。 -
kernel_initializer: 如果 TCN 训练卡住,可能值得更改此参数。例如:glorot_uniform。 -
use_batch_norm、use_weight_norm、use_weight_norm: 如果你的网络足够大且任务包含足够的数据,则使用归一化。我通常更喜欢使用use_layer_norm,但你可以尝试所有这些并选择效果最好的。
感受野
感受野定义为:当前样本在时间 T 上,来自(块、层、堆栈、TCN)的过滤器可以命中的最大步长(有效历史)+ 1。TCN 的感受野可以用公式计算:
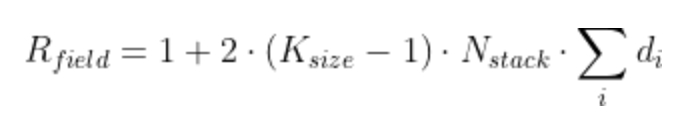
其中 Nstack 是堆栈数量,Nb 是每个堆栈中的残差块数量,d 是每个堆栈中每个残差块的扩张向量,K 是内核大小。2 的存在是因为在单个 ResidualBlock 中有两个 Conv1d 层。
理想情况下,你希望感受野大于输入序列的最大长度,如果你将比感受野更长的序列传递到模型中,任何额外的值(序列中更远的地方)将被替换为零。
示例
注意:与 TCN 不同,示例图像仅包含每层一个 Conv1d,因此公式变为 Rfield = 1 + (K-1)⋅Nstack⋅Σi di(没有 2 因子)。
- 如果扩张卷积网络只有一个堆栈的残差块,内核大小为
2,扩张为[1, 2, 4, 8],其感受野为16。如下图所示:
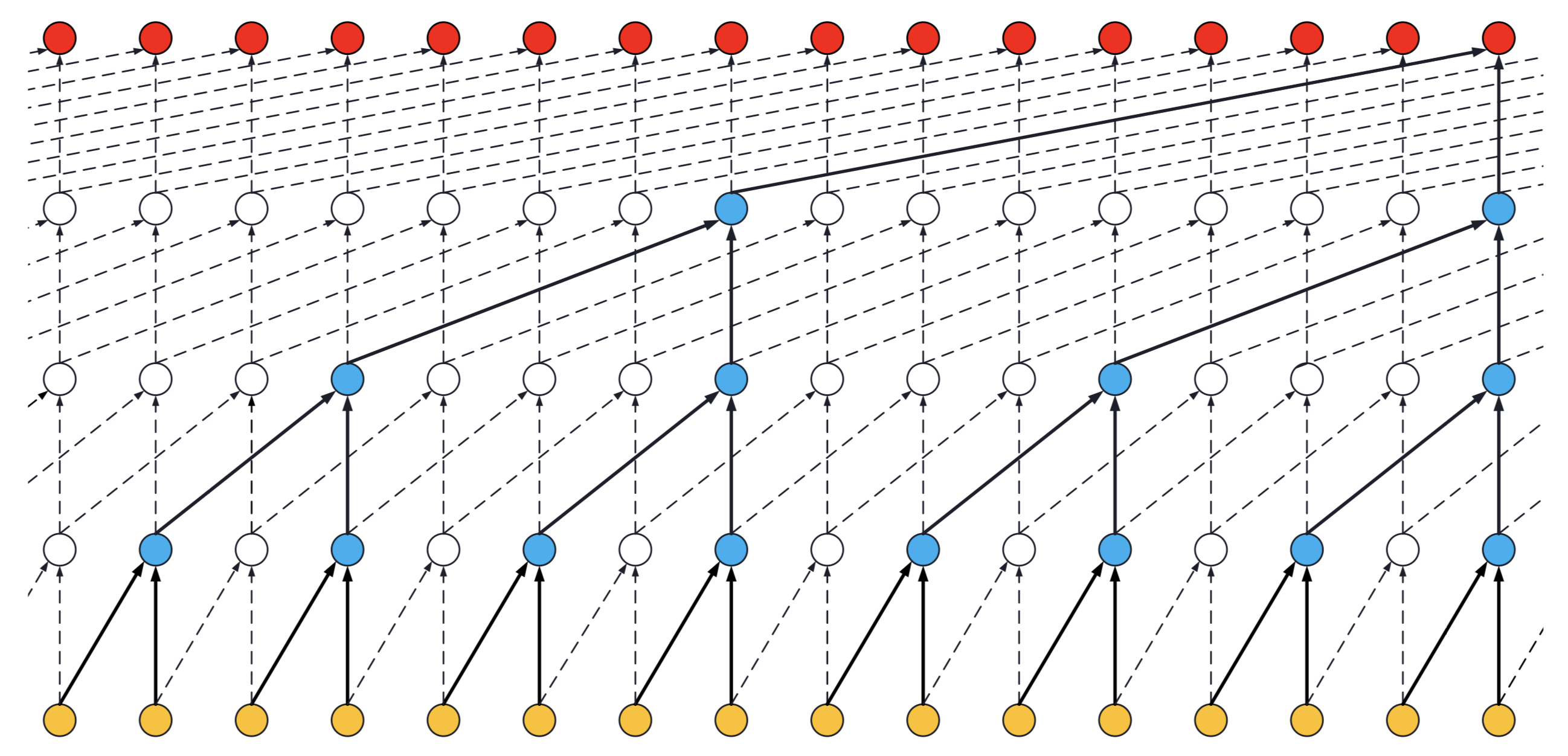 ks = 2,扩张 = [1, 2, 4, 8],1 个块
ks = 2,扩张 = [1, 2, 4, 8],1 个块
- 如果扩张卷积网络有 2 个堆栈的残差块,你会有如下情况,即增加感受野到 31:
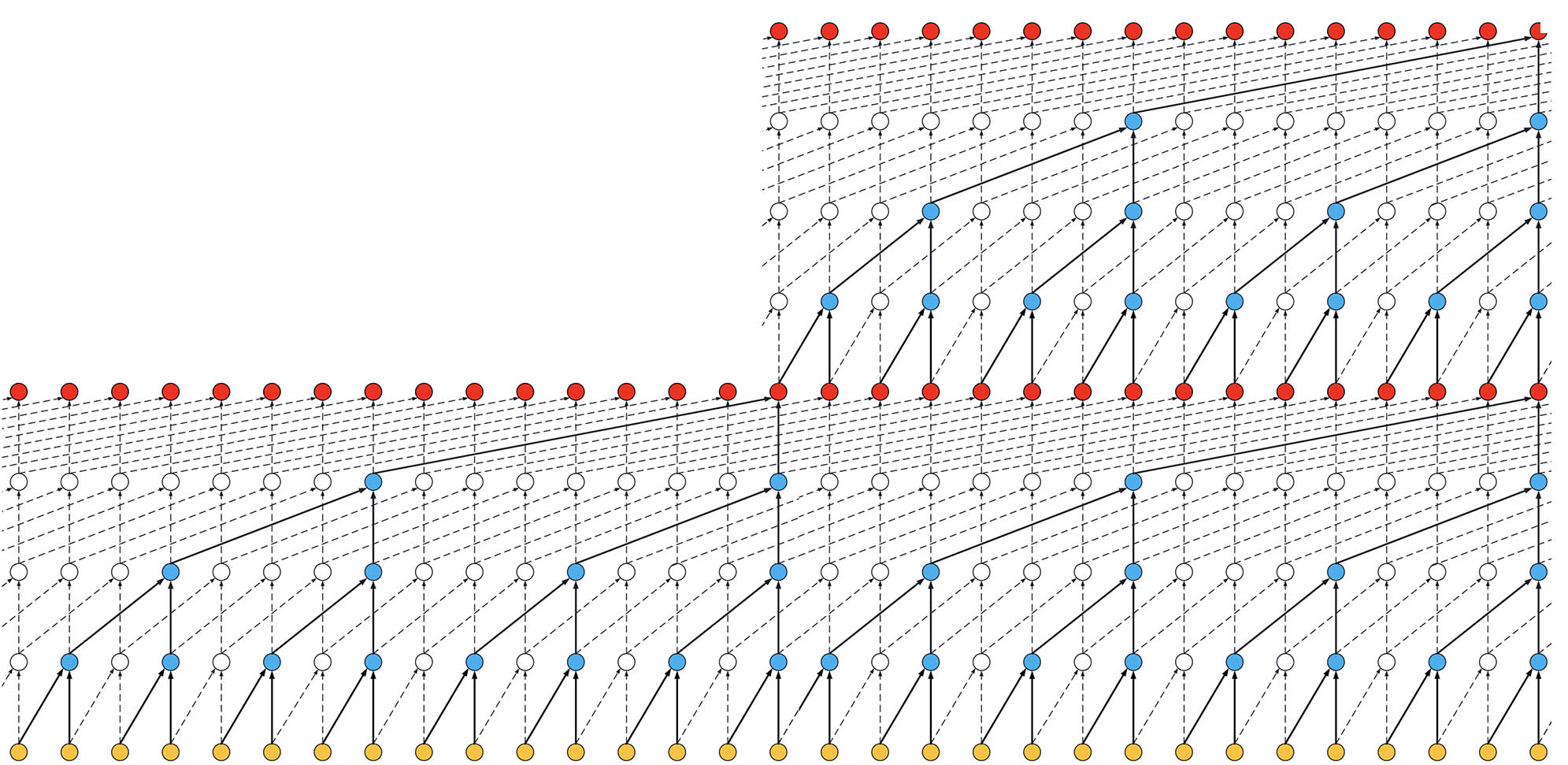 ks = 2,扩张 = [1, 2, 4, 8],2 个块
ks = 2,扩张 = [1, 2, 4, 8],2 个块
- 如果我们增加堆栈数到 3,感受野的大小将再次增加,如下图所示:
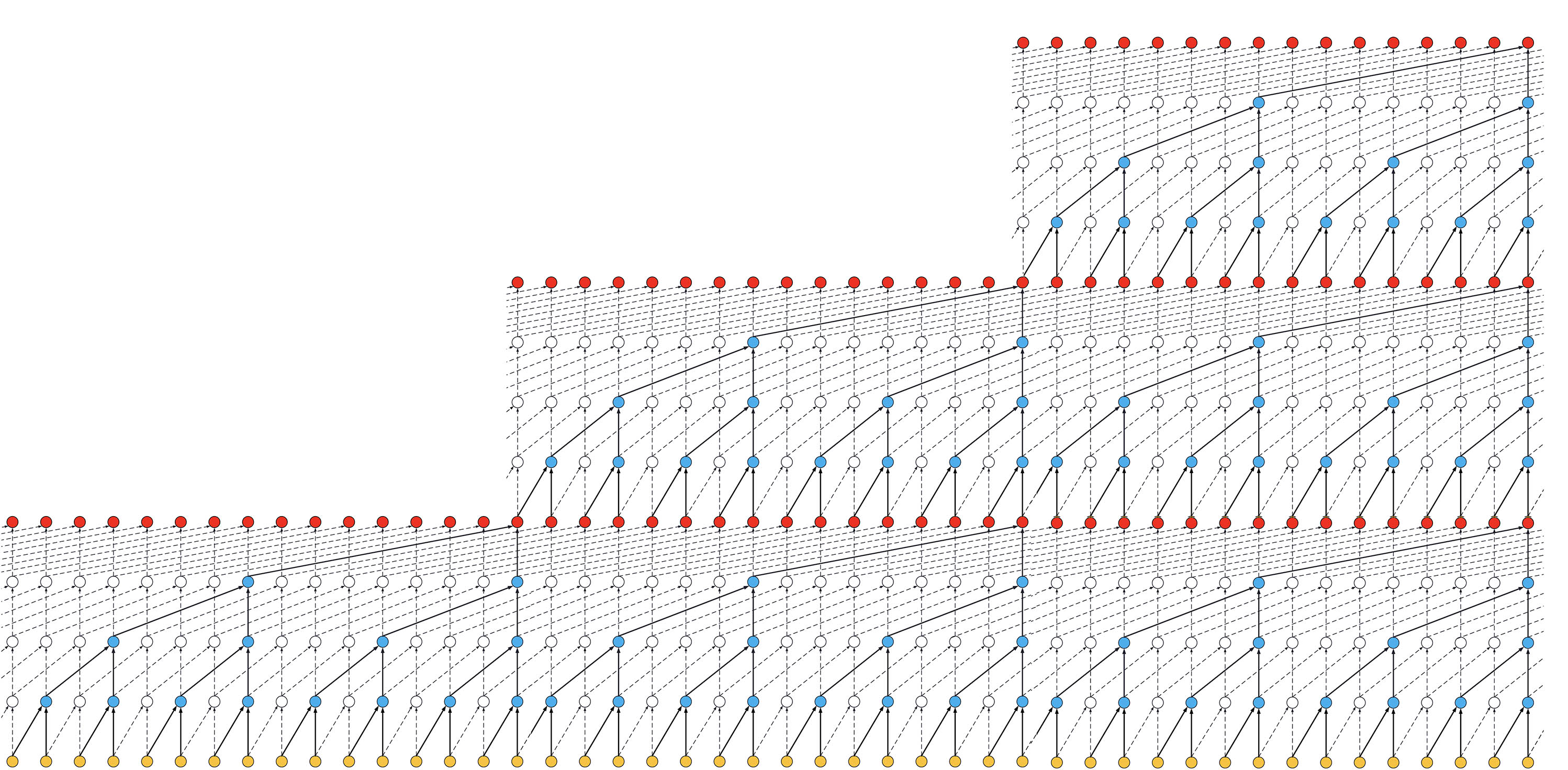 ks = 2,扩张 = [1, 2, 4, 8],3 个块
ks = 2,扩张 = [1, 2, 4, 8],3 个块
非因果 TCN
使 TCN 架构非因果可以考虑未来进行预测,如下图所示。
然而,它不再适用于实时应用。
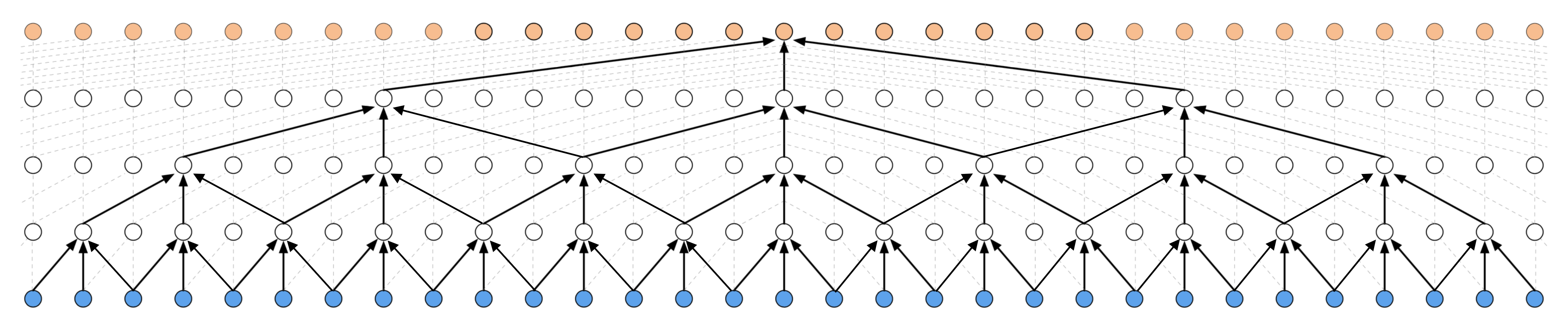 非因果TCN - ks = 3, dilations = [1, 2, 4, 8], 1个块
非因果TCN - ks = 3, dilations = [1, 2, 4, 8], 1个块
要使用非因果TCN,在初始化TCN层时指定padding='valid'或padding='same'。
运行
一旦keras-tcn作为一个包安装好,你就可以一窥TCN所能实现的功能。为了这个目的,仓库里提供了一些任务示例:
cd adding_problem/
python main.py # 运行加法问题任务
cd copy_memory/
python main.py # 运行内存复制任务
cd mnist_pixel/
python main.py # 运行顺序MNIST像素任务
在(NVIDIA) GPUs上使用tensorflow-determinism库可以实现可重复性的结果。它通过@lingdoc对keras-tcn进行了测试。
任务
Word PTB
语言建模仍然是递归网络的主要应用之一。在这个例子中,我们展示了TCN可以在WordPTB任务中击败LSTM,而不需要太多的调优。
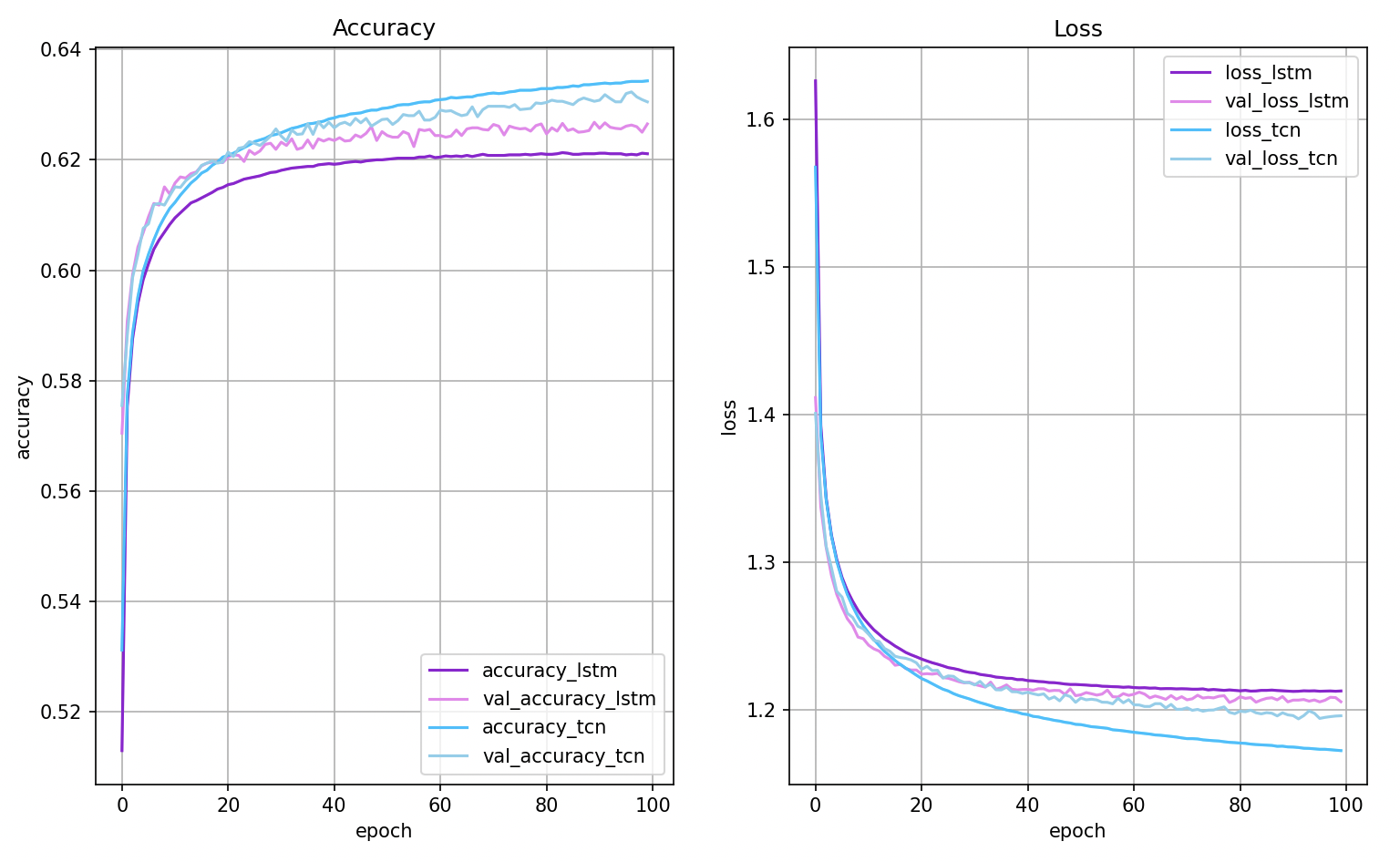
TCN vs LSTM(相似数量的权重)
加法任务
该任务包含向网络输入一个大的十进制数数组,以及同等长度的布尔数组。目标是求出布尔数组包含的两个1中的两个十进制数的和。
解释
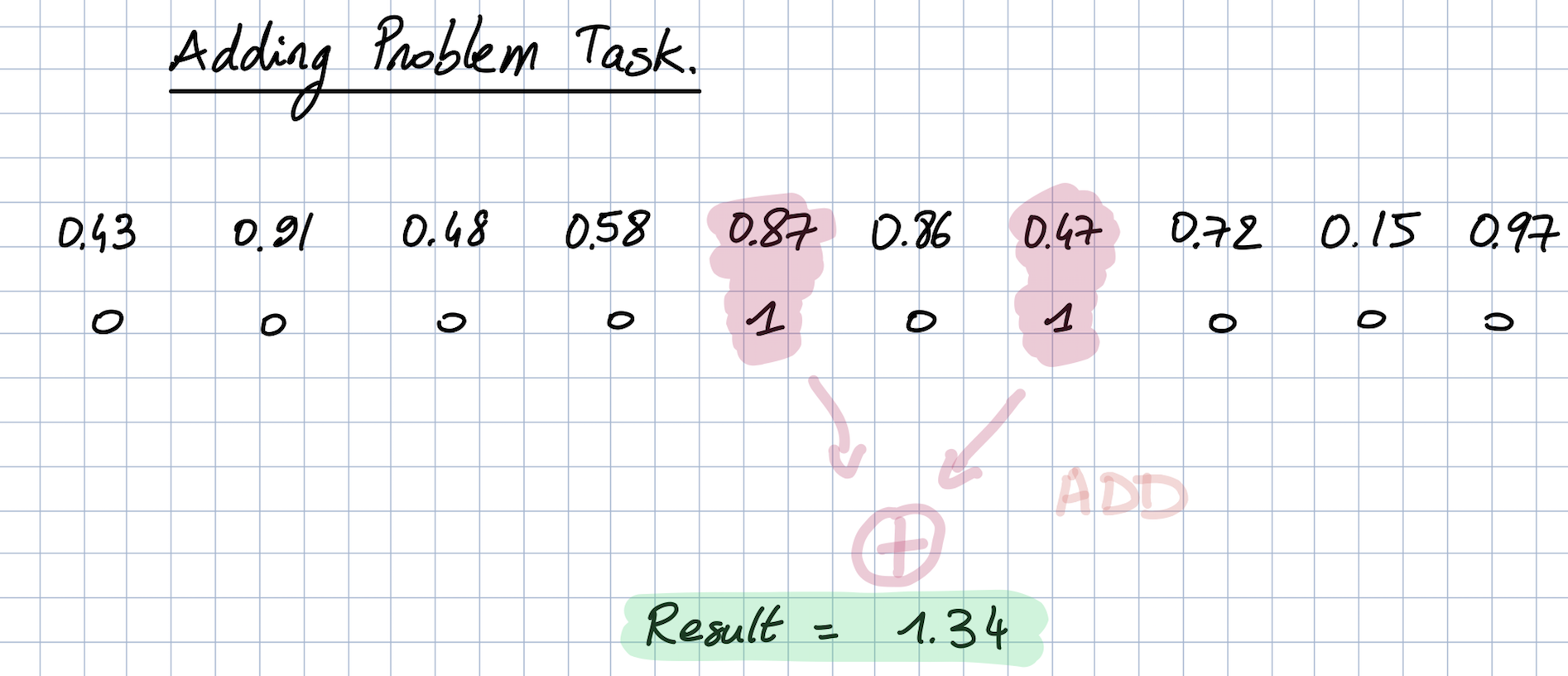 加法问题任务
加法问题任务
实现结果
782/782 [==============================] - 154s 197ms/step - loss: 0.8437 - val_loss: 0.1883
782/782 [==============================] - 154s 196ms/step - loss: 0.0702 - val_loss: 0.0111
[...]
782/782 [==============================] - 152s 194ms/step - loss: 6.9630e-04 - val_loss: 3.7180e-04
内存复制任务
内存复制任务由一个非常大的数组组成:
- 一开始有一个长度为N的向量x。这是要复制的向量。
- 最后有N+1个9。第一个9被视为分隔符。
- 中间只有0。
这个任务的想法是将向量x的内容复制到大数组的末尾。通过增加中间0的数量,使任务变得相当复杂。
解释
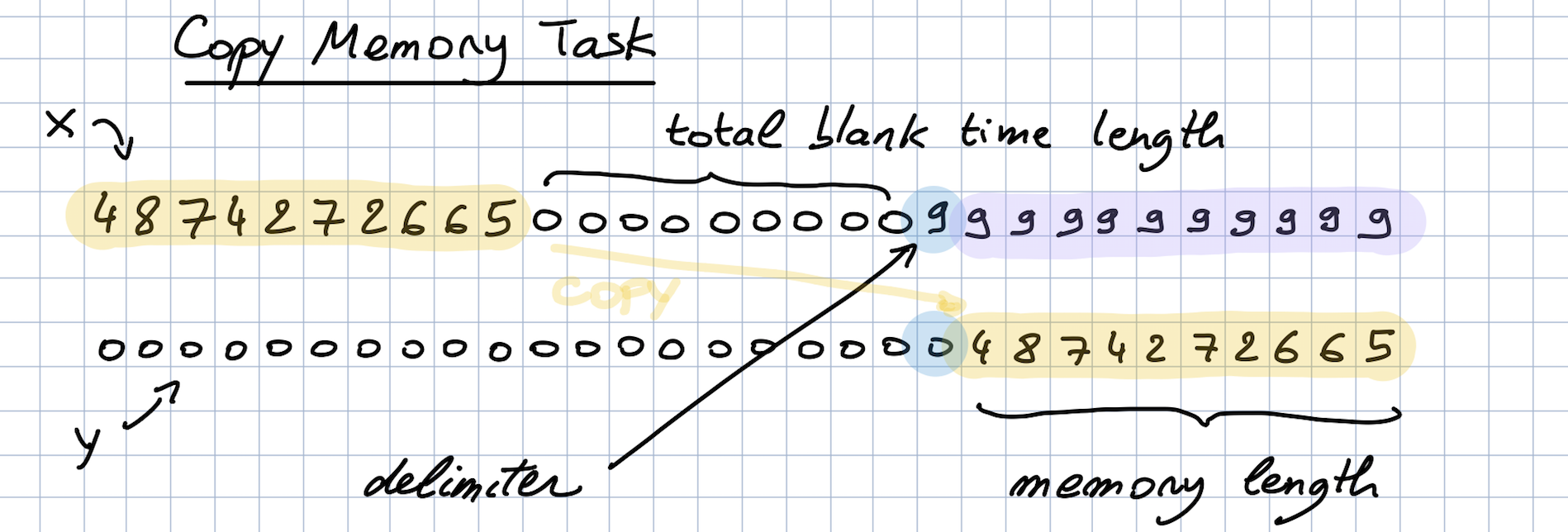 内存复制任务
内存复制任务
实现结果(前几轮)
118/118 [==============================] - 17s 143ms/step - loss: 1.1732 - accuracy: 0.6725 - val_loss: 0.1119 - val_accuracy: 0.9796
[...]
118/118 [==============================] - 15s 125ms/step - loss: 0.0268 - accuracy: 0.9885 - val_loss: 0.0206 - val_accuracy: 0.9908
118/118 [==============================] - 15s 125ms/step - loss: 0.0228 - accuracy: 0.9900 - val_loss: 0.0169 - val_accuracy: 0.9933
顺序MNIST
解释
这里的想法是将MNIST图像视为1-D序列并将其输入到网络中。这项任务特别困难,因为序列包含28*28 = 784个元素。为了正确分类,网络必须记住整个序列。普通的LSTM无法在这项任务中表现良好。
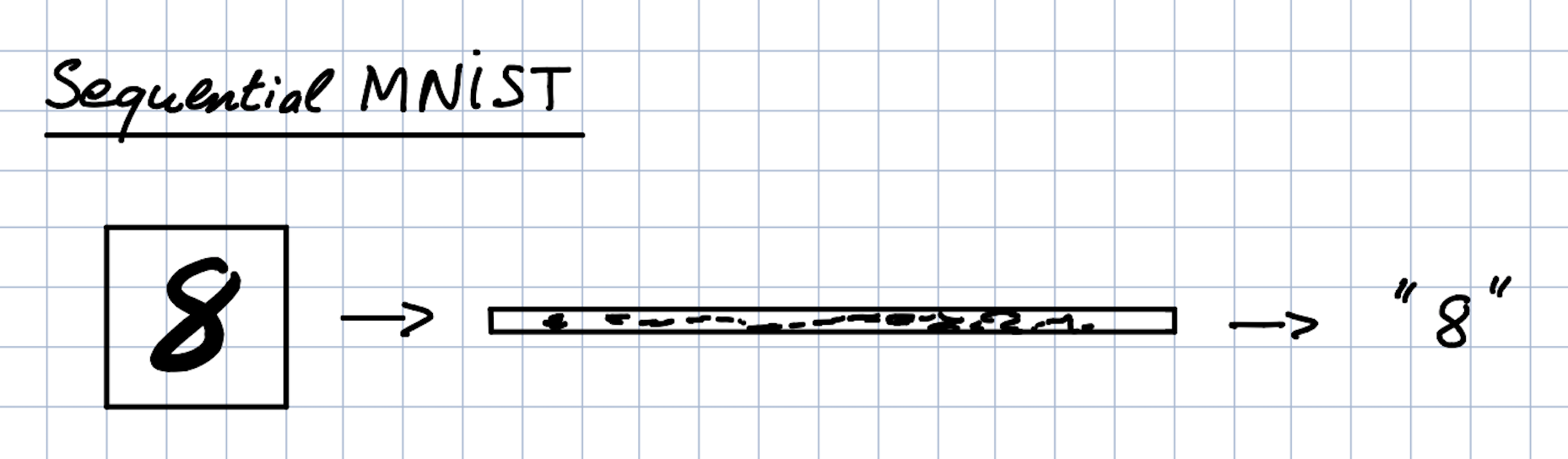 顺序MNIST
顺序MNIST
实现结果
1875/1875 [==============================] - 46s 25ms/step - loss: 0.0949 - accuracy: 0.9706 - val_loss: 0.0763 - val_accuracy: 0.9756
1875/1875 [==============================] - 46s 25ms/step - loss: 0.0831 - accuracy: 0.9743 - val_loss: 0.0656 - val_accuracy: 0.9807
[...]
1875/1875 [==============================] - 46s 25ms/step - loss: 0.0486 - accuracy: 0.9840 - val_loss: 0.0572 - val_accuracy: 0.9832
1875/1875 [==============================] - 46s 25ms/step - loss: 0.0453 - accuracy: 0.9858 - val_loss: 0.0424 - val_accuracy: 0.9862
参考文献
- https://github.com/locuslab/TCN/ (适用于Pytorch的TCN)
- https://arxiv.org/pdf/1803.01271(针对序列建模的通用卷积网络和递归网络的实证评估)
- https://arxiv.org/pdf/1609.03499 (原始Wavenet论文)
- https://github.com/Baichenjia/Tensorflow-TCN (TCNs的Tensorflow Eager实现)
引用
@misc{KerasTCN,
author = {Philippe Remy},
title = {Temporal Convolutional Networks for Keras},
year = {2020},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/philipperemy/keras-tcn}},
}
贡献者












