
 访问官网
访问官网 Github
Github 论文
论文概述
这是RecSys2023论文"揭示ChatGPT在推荐系统中的能力"的官方实现。[arXiv]
摘要: ChatGPT的首次亮相最近引起了自然语言处理界及其他领域的关注。现有研究表明,ChatGPT在一系列下游NLP任务中显示出显著改进,但ChatGPT在推荐方面的能力和局限性仍不清楚。在本研究中,我们旨在从信息检索(IR)的角度对ChatGPT的推荐能力进行实证分析,包括逐点、成对和列表式排序。为实现这一目标,我们将上述三种推荐策略重新制定为特定领域的提示格式。通过在来自不同领域的四个数据集上进行广泛实验,我们证明ChatGPT在所有三种排序策略中均优于其他大型语言模型。基于单位成本改进的分析,我们发现与逐点和成对排序相比,采用列表式排序的ChatGPT在成本和性能之间达到了最佳平衡。此外,ChatGPT还显示出缓解冷启动问题和可解释推荐的潜力。
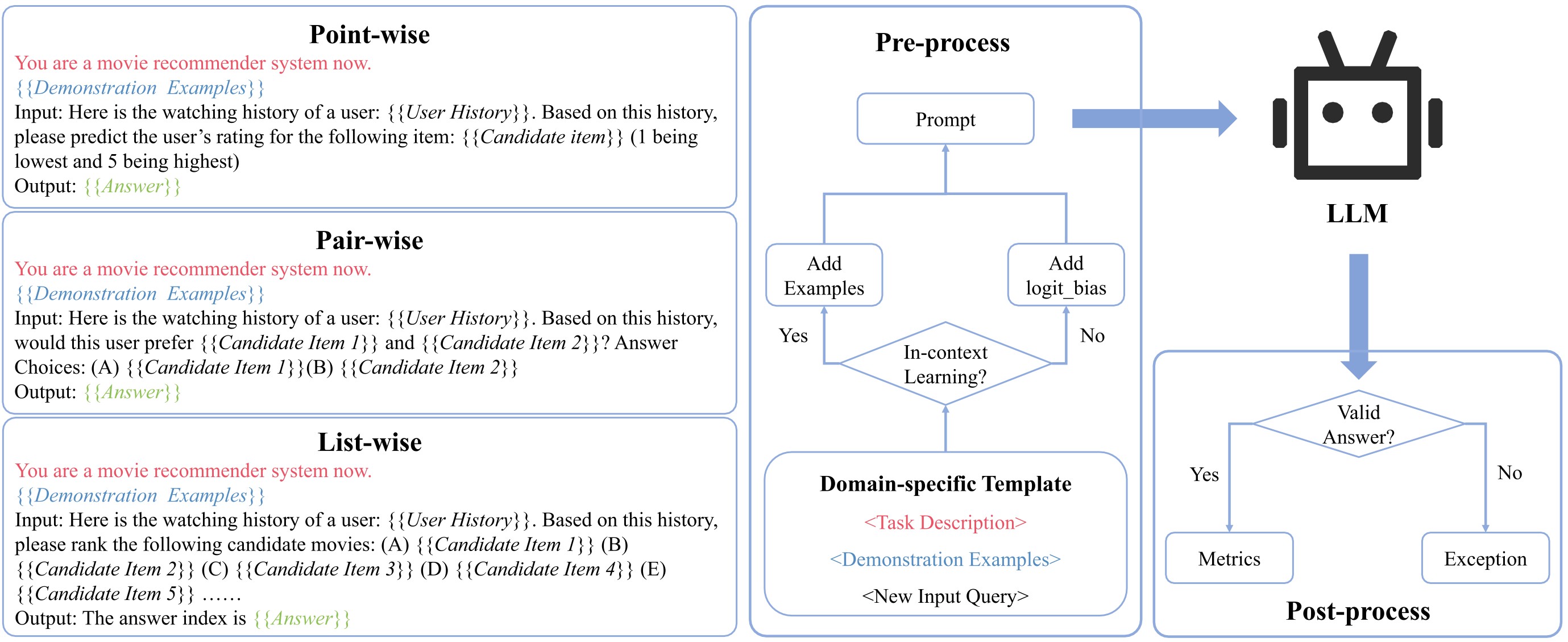
LLM用于推荐任务的整体评估框架如下图所示:
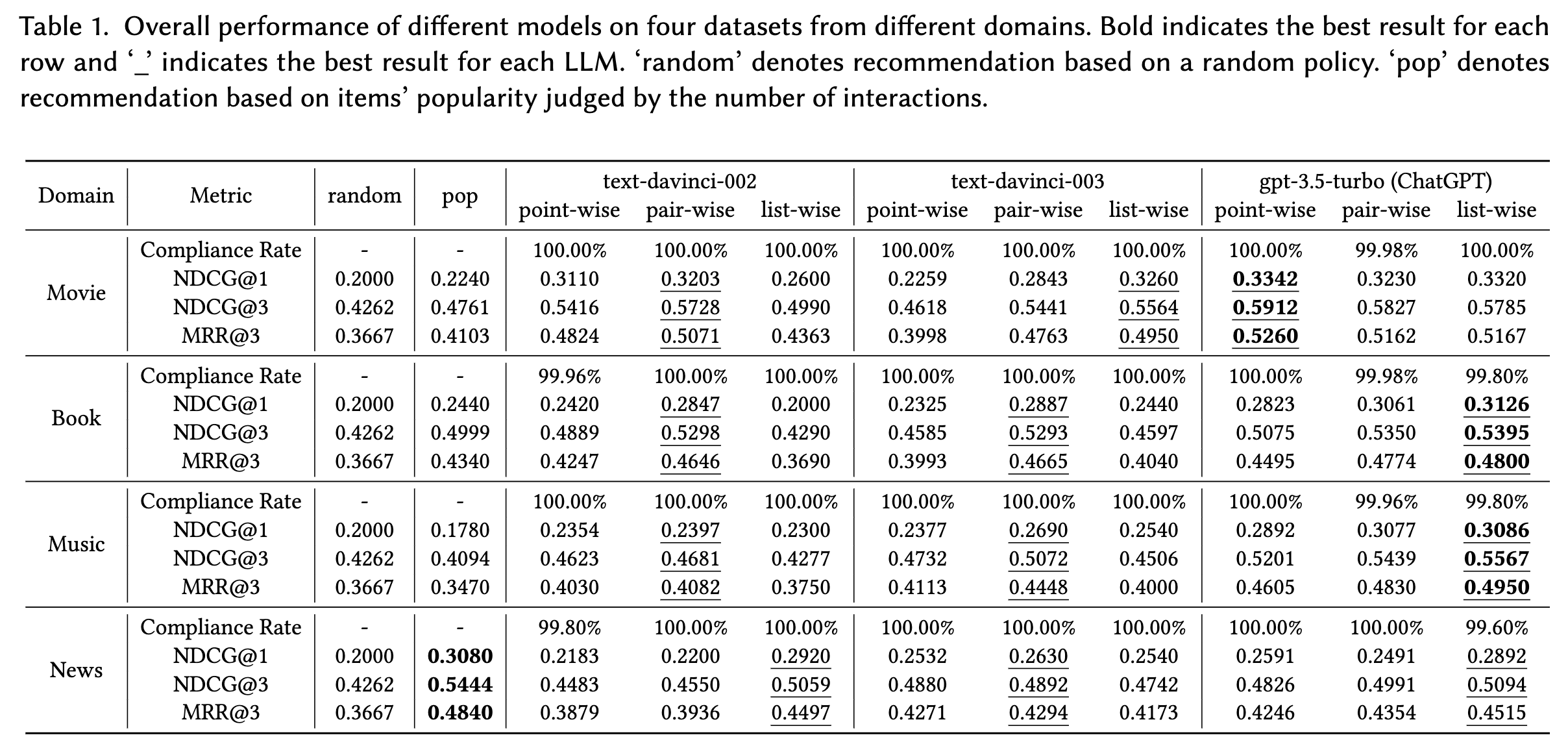
不同LLM在四个不同领域数据集上的主要结果如下所示:
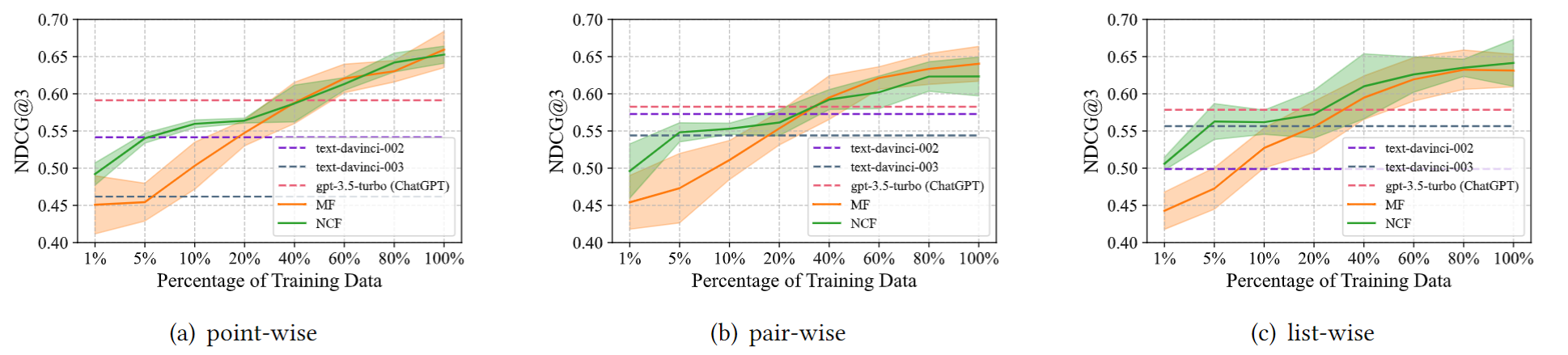
快速开始
-
有关数据集的详细信息,请查看文件
data/readme.md。 -
有关相关工作和更多实验结果的详细信息,请查看文件
assets/Supplemental_Material.pdf。 -
有关提示的详细信息,请查看文件
assets/prompts.pdf。 -
有关原始结果的详细信息,请从此处下载
文件结构
.
├── data # * 数据路径
│ ├── Book
│ ├── Movie
│ ├── Music
│ ├── News
│ └── preprocess # * 用于预处理原始数据集的Jupyter笔记本文件夹
├── result # * 用于保存请求、响应、结果和日志的文件夹
├── script # * 用于保存脚本的文件夹
└── src # * 源代码
├── api # * 访问API的代码
├── postprocess # * 数据后处理的代码
└── preprocess # * 数据预处理的代码
使用方法
-
克隆此仓库。
git clone https://github.com/rainym00d/LLM4RS.git -
从这里下载预处理好的数据。然后将它们放入
data文件夹。(如果你想使用自己的数据,可以查看data/readme.md中的原始数据集链接,并参考我们在data/preprocess中的预处理代码。) -
根据你自己的需求编辑
script/run.py中的参数。(此代码可以批量执行,只需将参数写入一个列表即可。) -
在项目的根目录下运行
python script/run.py。 -
检查
result目录中的相应文件夹并记录实验结果。
示例
git clone https://github.com/rainym00d/LLM4RS.git
cd LLM4RS
# * 在运行此命令之前,你应该在script/run.py中填写自己的api-key。
python script/run.py
run.py中的参数
- model
- LLM的模型名称。
- 默认值:"text-davinci-003"
- 选项:["text-davinci-002", "text-davinci-003", "gpt-3.5-turbo"]
- domain
- 领域名称。
- 默认值:"Movie"
- 选项:["Movie", "Book", "Music", "News"]
- task
- 任务名称。
- 默认值:"list"
- 选项:["point", "pair", "list"]
- no_instruction
- 是否使用指令。
- 默认值:False
- 选项:[True, False]
- example_num
- 给模型的示例数量。
- 默认值:1
- 选项:[1, 2, 3, 4, 5]
- begin_index
- 数据的起始索引。
- 默认值:5
- 选项:大于4但小于数据大小的整数
- end_index
- 数据的结束索引。
- 默认值:505
- 选项:大于`begin_index`但小于数据大小的整数
- api_key
- 取决于你自己的openai账户的openai api-key。
- max_requests_per_minute
- 每分钟最大请求数。
- 默认值:2000
- 选项:最大值取决于你自己的openai账户。
- max_tokens_per_minute
- 每分钟最大令牌数。
- 默认值:10000
- 选项:最大值取决于你自己的openai账户。
- max_attempts
- 每个请求的最大尝试次数。
- 默认值:10
- proxy
- 你自己的代理。
- 默认值:None
依赖
本仓库有以下依赖要求。
python==3.9
aiohttp==3.8.4
pandas==1.5.3
tiktoken==0.3.0
xpflow==0.8
可以通过pip install -r requirements.txt安装所需的包。
引用
如果你发现我们的代码或工作对你的研究有用,请引用我们的工作。
@inproceedings{dai2023uncovering,
title={揭示ChatGPT在推荐系统中的能力},
author={戴孙浩 and 邵宁路 and 赵海源 and 于伟杰 and 司子华 and 徐晨 and 孙钟祥 and 张晓 and 徐军},
booktitle={第17届ACM推荐系统会议论文集},
year={2023}
}
联系方式
如果您有任何问题,请随时通过Github issues与我们联系。谢谢!











