访问官网
访问官网 Github
Github 文档
文档 论文
论文 cuML - GPU机器学习算法
cuML - GPU机器学习算法
cuML - GPU机器学习算法cuML是一套实现机器学习算法和数学基元函数的库,它们与其他RAPIDS项目共享兼容的API。
cuML使数据科学家、研究人员和软件工程师能够在GPU上运行传统的表格式机器学习任务,而无需深入了解CUDA编程的细节。在大多数情况下,cuML的Python API与scikit-learn的API相匹配。
对于大型数据集,这些基于GPU的实现可以比其CPU等效实现快10-50倍。有关性能的详细信息,请参阅cuML基准测试笔记本。
例如,以下Python代码片段加载输入并使用cuDF在GPU上计算DBSCAN聚类:
import cudf
from cuml.cluster import DBSCAN
# 创建并填充GPU DataFrame
gdf_float = cudf.DataFrame()
gdf_float['0'] = [1.0, 2.0, 5.0]
gdf_float['1'] = [4.0, 2.0, 1.0]
gdf_float['2'] = [4.0, 2.0, 1.0]
# 设置并拟合聚类
dbscan_float = DBSCAN(eps=1.0, min_samples=1)
dbscan_float.fit(gdf_float)
print(dbscan_float.labels_)
输出:
0 0
1 1
2 2
dtype: int32
cuML还支持多GPU和多节点多GPU操作,使用Dask实现越来越多的算法。以下Python代码片段从CSV文件读取输入,并在单个节点的多个GPU上,通过Dask工作集群执行最近邻查询:
初始化配置了UCX的LocalCUDACluster,以实现CUDA数组的快速传输
# 初始化UCX以实现CUDA数组的高速传输
from dask_cuda import LocalCUDACluster
# 创建Dask单节点CUDA集群,每个设备一个工作进程
cluster = LocalCUDACluster(protocol="ucx",
enable_tcp_over_ucx=True,
enable_nvlink=True,
enable_infiniband=False)
加载数据并执行k-最近邻搜索。cuml.dask估计器还支持Dask.Array作为输入:
from dask.distributed import Client
client = Client(cluster)
# 在工作进程间并行读取CSV文件
import dask_cudf
df = dask_cudf.read_csv("/path/to/csv")
# 拟合最近邻模型并查询
from cuml.dask.neighbors import NearestNeighbors
nn = NearestNeighbors(n_neighbors = 10, client=client)
nn.fit(df)
neighbors = nn.kneighbors(df)
如需更多示例,请浏览我们完整的API文档,或查看我们的示例演示笔记本。最后,您可以在notebooks-contrib仓库中找到完整的端到端示例。
支持的算法
| 类别 | 算法 | 说明 |
|---|---|---|
| 聚类 | 基于密度的空间聚类应用噪声(DBSCAN) | 通过Dask实现多节点多GPU |
| 基于密度的空间聚类应用噪声的层次结构(HDBSCAN) | ||
| K-均值 | 通过Dask实现多节点多GPU | |
| 单链接凝聚聚类 | ||
| 降维 | 主成分分析(PCA) | 通过Dask实现多节点多GPU |
| 增量PCA | ||
| 截断奇异值分解(tSVD) | 通过Dask实现多节点多GPU | |
| 统一流形近似和投影(UMAP) | 通过Dask实现多节点多GPU推理 | |
| 随机投影 | ||
| t-分布随机邻居嵌入(TSNE) | ||
| 用于回归或分类的线性模型 | 线性回归(OLS) | 通过Dask实现多节点多GPU |
| 带有Lasso或Ridge正则化的线性回归 | 通过Dask实现多节点多GPU | |
| ElasticNet回归 | ||
| LARS回归 | (实验性) | |
| 逻辑回归 | 通过Dask-GLM实现多节点多GPU 演示 | |
| 朴素贝叶斯 | 通过Dask实现多节点多GPU | |
| 随机梯度下降(SGD)、坐标下降(CD)和拟牛顿(QN)(包括L-BFGS和OWL-QN)求解器用于线性模型 | ||
| 用于回归或分类的非线性模型 | 随机森林(RF)分类 | 通过Dask实现实验性多节点多GPU |
| 随机森林(RF)回归 | 通过Dask实现实验性多节点多GPU | |
| 基于决策树模型的推理 | 森林推理库(FIL) | |
| K-最近邻(KNN)分类 | 通过Dask+UCX实现多节点多GPU,使用Faiss进行最近邻查询 | |
| K-最近邻(KNN)回归 | 通过Dask+UCX实现多节点多GPU,使用Faiss进行最近邻查询 | |
| 支持向量机分类器(SVC) | ||
| Epsilon-支持向量回归(SVR) | ||
| 预处理 | 标准化、均值移除和方差缩放 / 归一化 / 分类特征编码 / 离散化 / 缺失值插补 / 多项式特征生成 / 即将推出自定义转换器和非线性变换 | 基于Scikit-Learn预处理 |
| 时间序列 | Holt-Winters指数平滑 | |
| 自回归综合移动平均(ARIMA) | 支持季节性(SARIMA) | |
| 模型解释 | SHAP核心解释器 | 基于SHAP |
| SHAP排列解释器 | 基于SHAP | |
| 执行设备互操作性 | 通过最少的代码更改,可在主机/CPU或设备/GPU上互换运行估计器 演示 | |
| 其他 | K-最近邻(KNN)搜索 | 通过Dask+UCX实现多节点多GPU,使用Faiss进行最近邻查询 |
安装
请查看RAPIDS发布选择器,了解通过Conda或Docker安装每晚构建版或官方发布版cuML软件包的命令行。
从源代码构建/安装
请参阅构建指南。
贡献
请查看我们的cuML贡献指南。
参考文献
RAPIDS团队有许多深入技术探讨和示例的博客。您可以在Medium上找到它们。
有关cuML背后技术的更多细节,以及Python机器学习领域的更广泛概述,请参阅Sebastian Raschka、Joshua Patterson和Corey Nolet撰写的《Python中的机器学习:数据科学、机器学习和人工智能的主要发展和技术趋势》(2020)。
在项目中使用cuML时,请考虑引用此文献。您可以使用以下BibTeX引用格式:
@article{raschka2020machine,
title={Python中的机器学习:数据科学、机器学习和人工智能领域的主要发展和技术趋势},
author={Raschka, Sebastian and Patterson, Joshua and Nolet, Corey},
journal={arXiv预印本 arXiv:2002.04803},
year={2020}
}
联系方式
在RAPIDS网站上了解更多详情
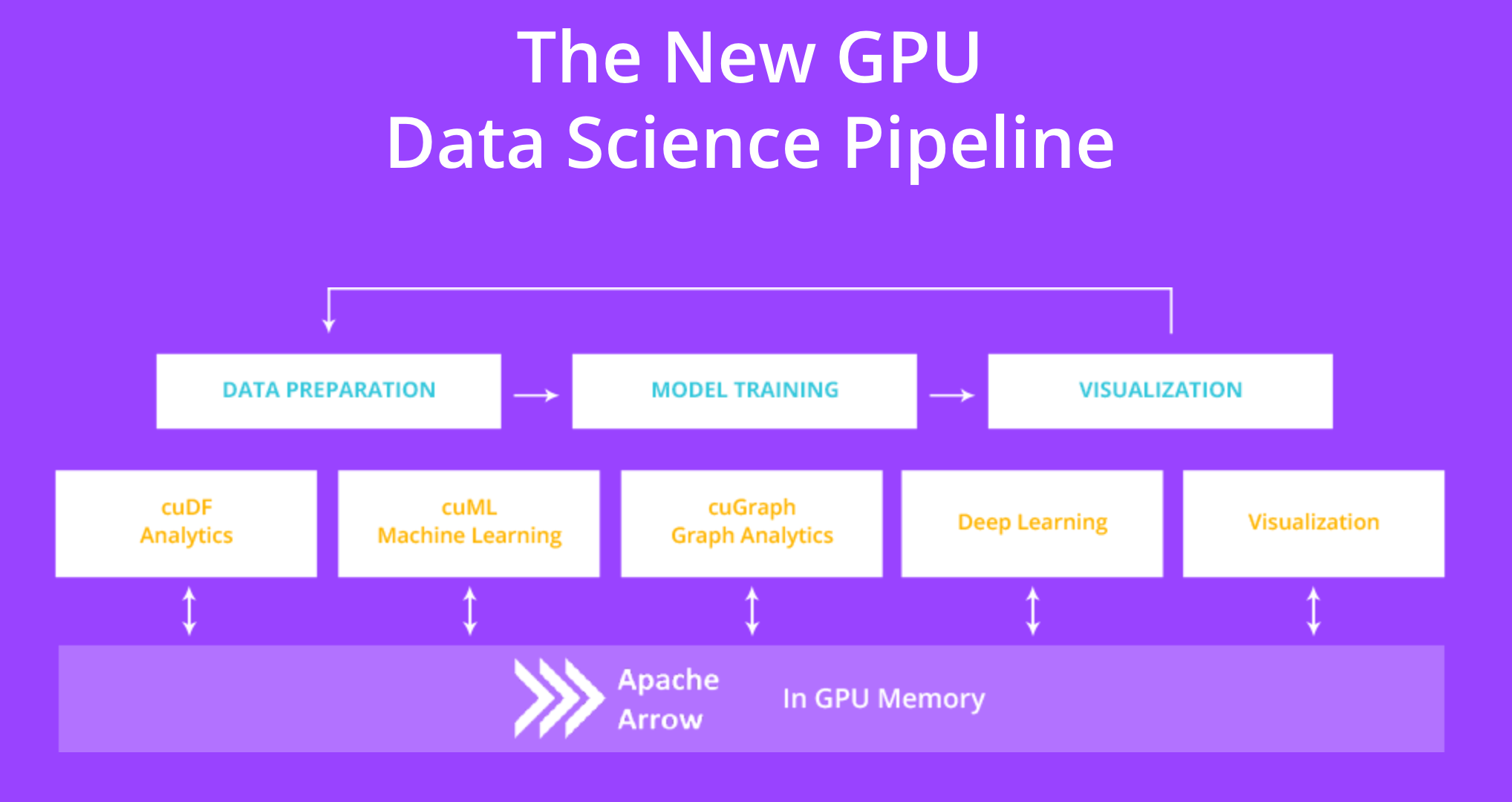
开放式GPU数据科学
RAPIDS开源软件库套件旨在实现端到端数据科学和分析流程完全在GPU上执行。它依赖NVIDIA® CUDA®原语进行低级计算优化,但通过用户友好的Python接口展现GPU并行性和高带宽内存速度。