
 Github
Github Huggingface
Huggingface 论文
论文StableVideo


StableVideo: 文本驱动一致性扩散视频编辑
柴文昊,郭汛✉️,王皋昂,卢岩
ICCV 2023
https://github.com/rese1f/StableVideo/assets/58205475/558555f1-711c-46f0-85bc-9c229ff1f511
https://github.com/rese1f/StableVideo/assets/58205475/c152d0fa-16d3-4528-b9c2-ad2ec53944b9
https://github.com/rese1f/StableVideo/assets/58205475/0edbefdd-9b5f-4868-842c-9bf3156a54d3
显存要求
| VRAM (MiB) | |
|---|---|
| float32 | 29145 |
| amp | 23005 |
| amp + cpu | 17639 |
| amp + cpu + xformers | 14185 |
- cpu: 使用 CPU 缓存,参数:
save_memory
在 app.py 中的默认设置下(例如分辨率等)
安装
git clone https://github.com/rese1f/StableVideo.git
conda create -n stablevideo python=3.11
pip install -r requirements.txt
(可选)pip install xformers
(可选)我们也提供仅 CPU 版本 huggingface demo。
git lfs install
git clone https://huggingface.co/spaces/Reself/StableVideo
pip install -r requirements.txt
下载预训练模型
所有模型和检测器可以从 ControlNet 的 Hugging Face 页面下载 下载链接。
下载示例视频
下载示例集,包括 car-turn、boat、libby、blackswa、bear、bicycle_tali、giraffe、kite-surf、lucia 和 motorbike。下载链接 下载链接 由 Text2LIVE 作者共享。
您也可以按照 NLA 的方法在自己的视频上进行训练。
它将创建一个文件夹 data:
StableVideo
├── ...
├── ckpt
│ ├── cldm_v15.yaml
│ ├── dpt_hybrid-midas-501f0c75.pt
│ ├── control_sd15_canny.pth
│ └── control_sd15_depth.pth
├── data
│ └── car-turn
│ ├── checkpoint # NLA 模型保存在这里
│ ├── car-turn # 包含视频帧
│ ├── ...
│ ├── blackswan
│ ├── ...
└── ...
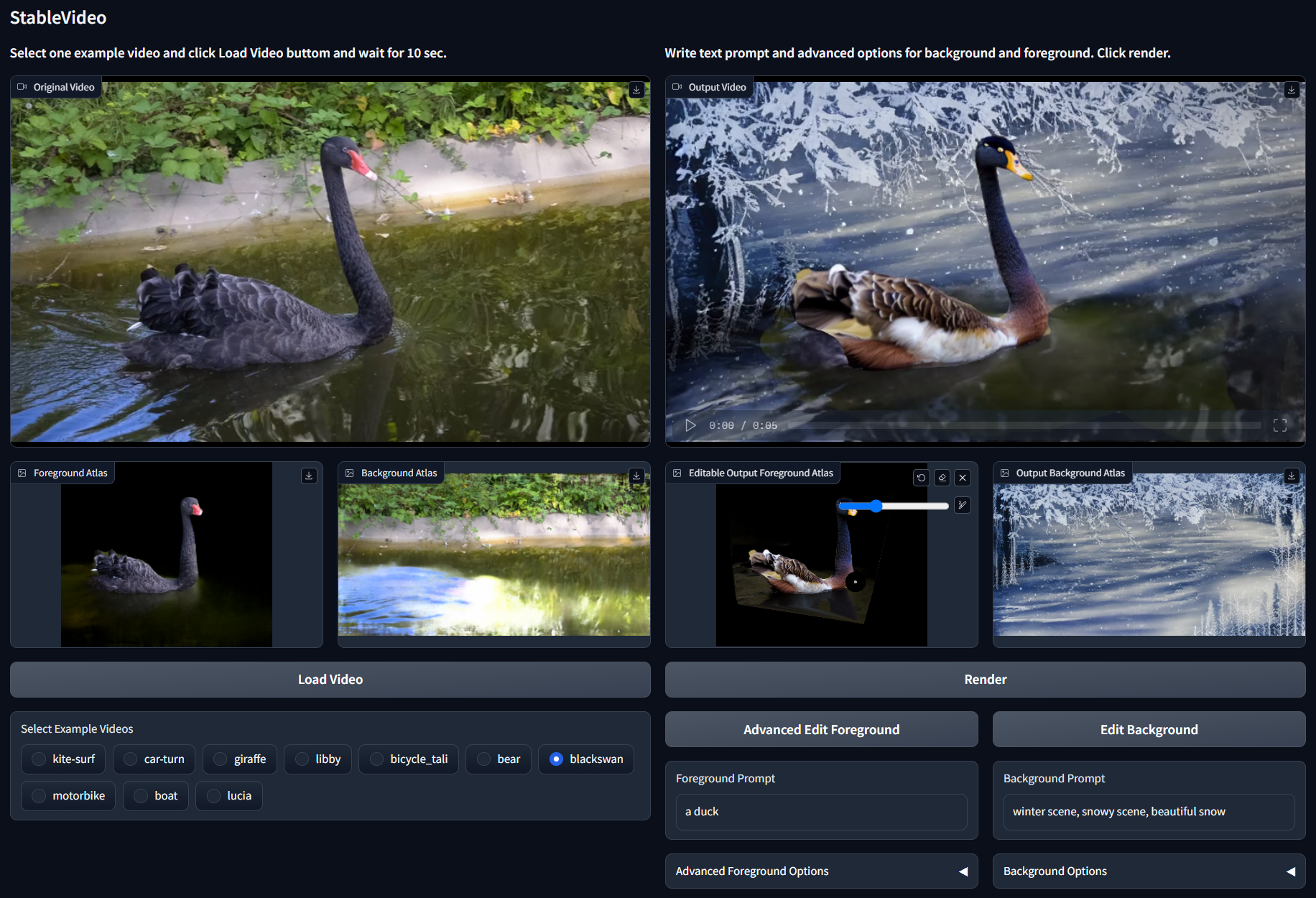
运行和播放
运行以下命令开始。
python app.py
点击 render 按钮后,结果 .mp4 视频和关键帧将存储在目录 ./log 中。
您还可以按如下所述编辑前景图集的蒙版区域。目前 Gradio 可能存在一个错误。请仔细检查 可编辑输出前景图集区块 是否与上面的相同。如果不是,请尝试重新启动整个程序。
引用
如果我们的工作对您的研究有帮助,请考虑引用以下内容。非常感谢 :)
@article{chai2023stablevideo,
title={StableVideo: Text-driven Consistency-aware Diffusion Video Editing},
author={Chai, Wenhao and Guo, Xun and Wang, Gaoang and Lu, Yan},
journal={arXiv preprint arXiv:2308.09592},
year={2023}
}
致谢
此实现部分基于 Text2LIVE 和 ControlNet。











