
 访问官网
访问官网 Github
Github Huggingface
HuggingfacePALLAIDIUM - 集成到Blender视频编辑器中的生成式AI电影工作室
从文本提示或视频、图像、文本条生成AI视频、图像和音频。
Discord
功能
| 文本生成视频 | 文本生成音频 |
| 文本转语音 | 文本生成图像 |
| 图像生成图像 | 图像生成视频 |
| 视频生成视频 | 图像转文本 |
| ControlNet | OpenPose |
| ADetailer | IP Adapter 人脸/风格 |
| Canny | Illusion |
| 多个LoRA | Segmind蒸馏SDXL |
| 种子 | 质量步骤 |
| 帧数 | 词语权重 |
| 风格选择器 | 条带权重 |
| 批量转换 | 批量优化图像 |
| 批量放大和优化视频 | 模型卡选择器 |
| 渲染路径选择器 | 渲染完成通知 |
| 模型卡 | 一键安装和卸载依赖 |
| 用户自定义生成文件路径 | 种子和提示添加到条带名称 |
要求
- Windows(不支持Linux和MacOS)
- 支持CUDA的Nvidia显卡,至少6 GB显存
- CUDA: 12.4
- 20+ GB硬盘空间(每个模型6+ GB)
对于Mac和Linux,我们需要依靠贡献者的支持。请在这里发布Mac相关问题:https://github.com/tin2tin/Pallaidium/issues/106,在这里发布Linux相关问题:https://github.com/tin2tin/Pallaidium/issues/105,希望有贡献者愿意帮助你。
如何安装
-
首先,下载并安装git(必须在PATH中):https://git-scm.com/downloads
-
下载插件:https://github.com/tin2tin/text_to_video/archive/refs/heads/main.zip
-
在Windows上,右键单击Blender图标并选择"以管理员身份运行Blender"(否则会出现写入权限错误)
-
按常规方式安装插件:首选项 > 插件 > 安装 > 选择文件 > 启用插件
-
在生成式AI插件首选项中,点击"卸载依赖项"按钮(清除任何不兼容的库)
-
重启Blender
-
在生成式AI插件首选项中,点击"安装依赖项"按钮
-
重启Blender
-
在序列编辑器 > 侧边栏 > 生成式AI中打开插件UI
-
首次执行任何模型时,需要先下载5-10 GB的数据
| 提示 |
|---|
| 如果缺少任何Python模块,使用此插件手动安装: |
| https://github.com/amb/blender_pip |
更新日志
- 2024-8-5:添加:Flux Dev - 注意:需要更新依赖项和24 GB显存
- 2024-8-2:添加:Flux Schnell - 注意:需要更新依赖项和24 GB显存
- 2024-7-12:添加:Kwai/Kolors(文本生成图像和图像生成图像)
- 2024-6-13:添加:SD3 - 需要输入HuggingFace的"Read"令牌,它是免费的(图像生成图像)。修复:依赖项安装
- 2024-6-6:添加:Stable Audio Open,帧数:-1将继承持续时间
- 2024-6-1:IP Adapter(使用SDXL时):人脸(图像或文件夹),风格(图像或文件夹)新图像模型:Mobius、OpenVision、Juggernaut X Hyper
- 2024-4-29:添加:PixArt Sigma 2k、PixArt 1024和RealViz V4
- 2024-2-23:添加:Proteus Lightning和Dreamshaper XL Lightning
- 2024-2-21:添加:SDXL-Lightning 2 Step和Proteus v. 0.3
- 2024-1-02:添加:WhisperSpeech
- 2024-01-01:修复安装和Bark错误
- 2024-01-31:添加OpenDalle、速度选项、SDXL,以及Canny和OpenPose的LoRA支持,包括OpenPose骨架图像。清理旧模型包括SD
- 2023-12-18:添加:Bark音频增强,Segmind Vega
- 2023-12-1:添加SD Turbo和MusicGen Medium,MacOS的MPS设备
- 2023-11-30:添加:SVD、SVD-XT、SDXL Turbo
位置
在插件首选项中安装依赖项,并设置声音通知:
视频序列编辑器 > 侧边栏 > 生成式AI:
风格:
在此查看SDXL处理大多数风格: https://stable-diffusion-art.com/sdxl-styles/
提示:
https://replicate.com/blog/get-the-best-from-stable-diffusion-3
https://github.com/invoke-ai/InvokeAI/blob/main/docs/features/PROMPTS.md
https://stablediffusion.fr/prompts
https://blog.segmind.com/generating-photographic-images-with-stable-diffusion/
| 提示 |
|---|
| 如果渲染图像出现问题,请在偏好设置中使用模型卡中的分辨率。 |
| 提示 |
|---|
| 如果图像播放卡顿,请选择一个条带 > 菜单 > 条带 > 电影条带 > 设置渲染大小。 |
| 提示 |
|---|
| 如果出现CUDA内存不足的提示,请重启Blender以释放内存并使其再次稳定。 |
批处理
选择多个条带并点击生成。执行此操作时,文件名以及找到的种子值会自动插入到提示和种子值中。但是,在插件偏好设置中可以关闭此行为。
https://github.com/tin2tin/Pallaidium/assets/1322593/28098eb6-3a93-4bcb-bd6f-53b71faabd8d
文本转音频
Bark
在此查找Bark文档: https://github.com/suno-ai/bark
- [笑声]
- [笑]
- [叹气]
- [音乐]
- [倒吸一口气]
- [清嗓子]
- — 或 ... 表示犹豫
- ♪ 表示歌词
- 大写字母强调某个词
- 男人/女人: 用于说话者偏好
说话人库: https://suno-ai.notion.site/8b8e8749ed514b0cbf3f699013548683?v=bc67cff786b04b50b3ceb756fd05f68c
| 提示 |
|---|
| 如果音频断断续续,请尝试处理更长的句子。 |
性能
可以通过以下指南提高性能: https://nvidia.custhelp.com/app/answers/detail/a_id/5490/~/system-memory-fallback-for-stable-diffusion
Blender新手?
观看此教程: https://youtu.be/4_MIaxzjh5Y?feature=shared
卸载
Hugging Face Diffusers模型从hub下载并保存到本地缓存目录。默认情况下,缓存目录位于:
Linux和macOS: ~/.cache/huggingface/hub
Windows: %userprofile%\.cache\huggingface\hub
您可以在这里找到并删除各个模型。
实用插件
添加渲染条带
由于生成式AI插件只能输入图像或电影条带,您需要将其他条带类型转换为电影条带。为此,可以使用此插件:
https://github.com/tin2tin/Add_Rendered_Strips
VSE遮罩工具
要在序列编辑器中的剪辑上创建遮罩,可以使用此插件将剪辑作为背景输入到Blender图像编辑器中。然后可以将创建的遮罩作为条带添加到VSE中,并使用上述插件转换为视频:
https://github.com/tin2tin/vse_masking_tools
字幕编辑器
编辑和导航生成的文本条带。
https://github.com/tin2tin/Subtitle_Editor
编剧助手
使用chatGPT生成故事,可用作提示。
https://github.com/tin2tin/Blender_Screenwriter_Assistant_chat_GPT
文本转条带
将文本编辑器中的文本转换为条带,可用作批量生成的提示。
https://github.com/tin2tin/text_to_strip
实用项目
LoRAs训练器: https://github.com/Nerogar/OneTrainer https://github.com/johnman3032/simple-lora-dreambooth-trainer HD Horizon(用于使SD 1.5在更高分辨率下工作的LoRA):https://civitai.com/models/238891/hd-horizon-the-resolution-frontier-multi-resolution-high-resolution-native-inferencing
Windows手动安装Triton:https://huggingface.co/madbuda/triton-windows-builds
视频示例
图像到文本
https://github.com/tin2tin/Pallaidium/assets/1322593/91eb17e4-72d6-4c69-8e5c-a3d38af5a770
幻觉扩散
https://github.com/tin2tin/Pallaidium/assets/1322593/42eadfd8-3ebf-4747-b8e0-7b79fe8626b6
涂鸦
https://github.com/tin2tin/Pallaidium/assets/1322593/c74a4e38-8b16-423b-be78-aadfbfe284dc
风格
https://github.com/tin2tin/Pallaidium/assets/1322593/b80812b4-e3be-40b0-a73b-bc55b7eeadf7
Canny边缘检测
https://github.com/tin2tin/Pallaidium/assets/1322593/a1e94e09-0147-40ae-b4c2-4ce0671b1289
OpenPose
https://github.com/tin2tin/Pallaidium/assets/1322593/ac9f278e-9fc9-46fc-a4e7-562ff041964f
剧本到电影

图像到文本到音频

Zeroscope

Würstchen

Bark

从文本条批量生成
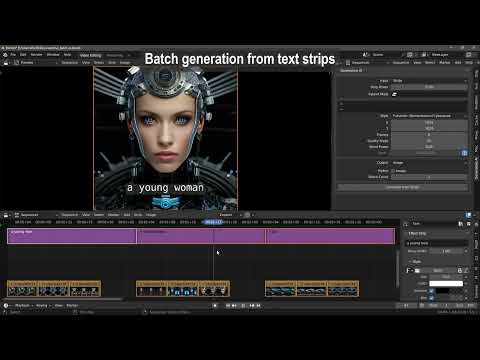
视频到视频:
https://github.com/tin2tin/Generative_AI/assets/1322593/c044a0b0-95c2-4b54-af0b-45bc0c670c89
https://github.com/tin2tin/Generative_AI/assets/1322593/0105cd35-b3b2-49cf-91c1-0633dd484177
图像到图像:
https://github.com/tin2tin/Generative_AI/assets/1322593/2dd2d2f1-a1f6-4562-8116-ffce872b79c3
绘画
https://github.com/tin2tin/Generative_AI/assets/1322593/7cd69cd0-5842-40f0-b41f-455c77443535
增强信息
LCM
https://huggingface.co/blog/lcm_lora
使用Pallaidium的限制:
- 禁止使用Pallaidium生成贬低或伤害他人、其环境、文化、宗教等的内容。
- 禁止使用Pallaidium生成色情、暴力和血腥内容。
- 禁止使用Pallaidium生成错误和虚假信息。
使用AI模型的限制:
- Pallaidium不包含任何生成式AI模型(权重)。如果用户决定使用模型,它将从HuggingFace下载。
- 通常,这些模型只能用于非商业目的,并且仅用于研究目的。
- 请查阅HuggingFace上各个模型的许可证,了解它们是否可以商业使用等信息。











