
 Github
GithubRecStudio

RecStudio是一个基于PyTorch的统一、高度模块化和推荐效率高的推荐系统库。所有算法根据推荐任务分类如下:
- 通用推荐
- 序列推荐
- 基于知识的推荐
- 基于特征的推荐
- 社交推荐
描述
模型结构
在库的核心部分,所有推荐模型被分为三个基类:
TowerFreeRecommender:最灵活的基类,可以实现任何复杂的特征交互建模。ItemTowerRecommender:物品编码器与推荐器分离,支持快速ANN和基于模型的负采样。TwoTowerRecommender:ItemTowerRecommender的子类,推荐器仅由用户编码器和物品编码器组成。
数据集结构
对于数据集结构,数据集被分为五类:
| 数据集 | 应用 | 示例 |
|---|---|---|
| TripletDataset | 提供用户-物品-评分三元组的数据集 | BPR, NCF, CML等 |
| UserDataset | 用于基于AutoEncoder的ItemTowerRecommender的数据集 | MultiVAE, RecVAE等 |
| SeqDataset | 用于因果预测的序列推荐器的数据集 | GRU4Rec, SASRec等 |
| Seq2SeqDataset | 用于掩码预测的序列推荐器的数据集 | Bert4Rec等 |
| ALSDataset | 用于交替最小二乘法优化的推荐器的数据集 | WRMF等 |
为了加速数据集处理,处理后的数据集会自动缓存,以便快速重复训练。
模型评估
RecStudio基于PyTorch实现了推荐系统中几乎所有常用的指标,如NDCG、Recall、Precision等。所有指标函数具有相同的接口,完全使用张量运算符实现。因此,评估过程可以移至GPU上,从而显著加快评估速度。
ANNs与采样器
为了加速训练和评估,RecStudio集成了各种近似最近邻搜索(ANNs)和负采样器。通过使用ANNs构建索引,基于欧氏距离、内积和余弦相似度的topk运算可以显著加速。负采样器包括静态采样器和RecStudio团队开发的基于模型的采样器。静态采样器包括均匀采样器和流行度采样器。基于模型的采样器基于物品向量的量化或重要性重采样。此外,我们还在数据集中实现了静态采样,这使我们能够在加载数据时生成负样本。
损失函数与评分函数
在RecStudio中,损失函数分为三类:
- FullScoreLoss:在所有物品上计算分数,如SoftmaxLoss。
- PairwiseLoss:在正样本和负样本上计算分数,如BPRLoss、BinaryCrossEntropyLoss等。
- PointwiseLoss:为单个(用户,物品)交互计算分数,如HingeLoss。
评分函数用于建模用户对物品的偏好。RecStudio实现了各种常用的评分函数,如InnerProduct、EuclideanDistance、CosineDistance、MLPScorer等。
| 损失函数 | 数学类型 | 采样分布 | 计算复杂度 | 采样复杂度 | 收敛速度 | 相关指标 |
|---|---|---|---|---|---|---|
| Softmax | | 无采样 | | - | 非常快 | NDCG |
| 采样Softmax | | 无采样 | | - | 快 | NDCG |
| BPR | | 均匀采样 | | | 慢 | AUC |
| WARP | | 拒绝采样 | | 越来越慢 | 慢 | 精确率 |
| InfoNCE | | 流行度采样 | | | 快 | DCG |
| WRMF | | 无采样 | | - | 非常快 | - |
| PRIS | | 聚类采样 | | | 非常快 | DCG |
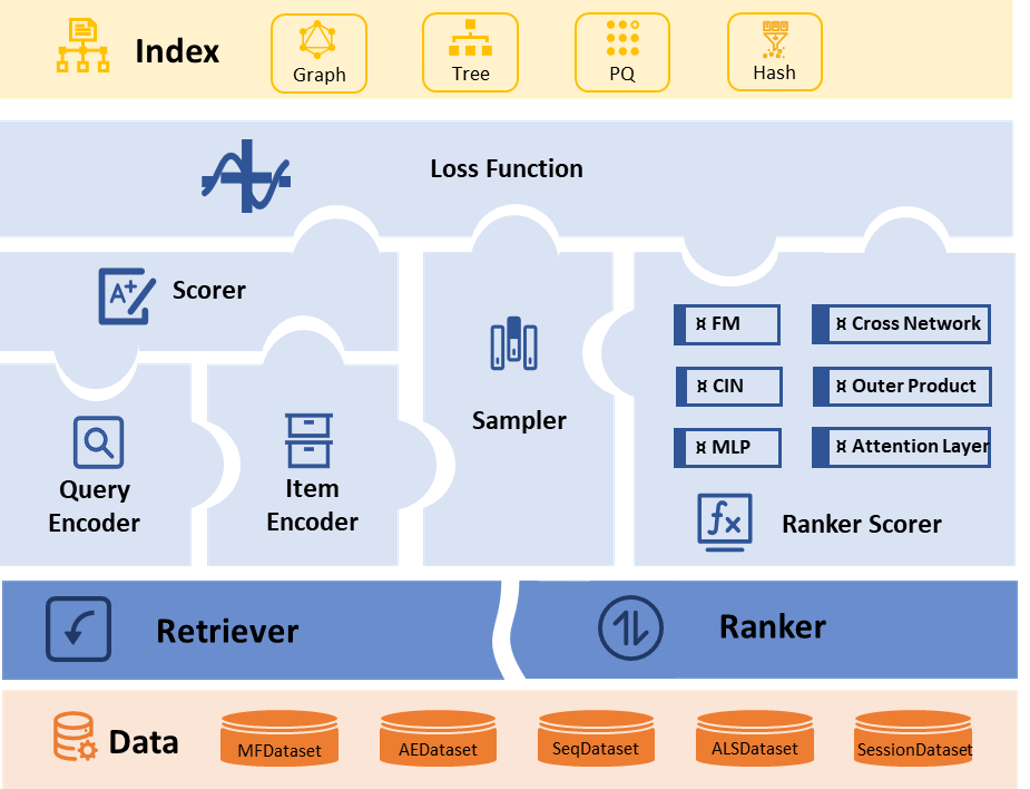
图片:RecStudio 框架
特性
- 通用数据集结构 RecStudio 支持基于原子数据文件和自动数据缓存的统一数据集配置。
- 模块化模型结构 通过将整个推荐器组织成不同的模块、损失函数、评分函数、采样器和人工神经网络,您可以像搭建积木一样定制您的模型。
- GPU 加速 从模型训练到模型评估的整个操作可以轻松地在 GPU 和分布式 GPU 上运行。
- 简单的模型分类 RecStudio 根据编码器的数量对所有模型进行分类,易于理解和使用。这种分类方法可以涵盖所有模型。
- 简单和复杂的负采样器 RecStudio 仅使用张量运算符集成了静态和基于模型的采样器。
快速开始
通过下载源代码,您可以运行提供的脚本 run.py 来初步使用 RecStudio。
python run.py
初始配置将在 MovieLens-100k(ml-100k)数据集上训练和评估 BPR 模型。
一般来说,这个简单的示例在 GPU 上运行不到一分钟。输出将类似于以下内容:
[2023-08-24 10:51:41] INFO 日志保存在 /home/RecStudio/log/BPR/ml-100k/2023-08-24-10-51-41-738329.log。
[2023-08-24 10:51:41] INFO 全局种子设置为 2022
[2023-08-24 10:51:41] INFO 数据集从 /home/RecStudio/recstudio/dataset_demo/ml-100k 读取。
[2023-08-24 10:51:42] INFO
数据集信息:
=============================================================================
交互信息:
字段 用户ID 物品ID 评分 时间戳
类型 标记 标记 浮点数 浮点数
## 944 1575 - -
=============================================================================
用户信息:
字段 用户ID 年龄 性别 职业 邮编
类型 标记 标记 标记 标记 标记
## 944 62 3 22 795
=============================================================================
物品信息:
字段 物品ID
类型 标记
## 1575
=============================================================================
总交互数:82520
稀疏度:0.944404
=============================================================================
时间戳=StandardScaler()
[2023-08-24 10:51:42] INFO
模型配置:
数据:
二值化评分阈值=无
fm评估=False
负样本数=0
采样器=无
随机打乱=True
划分模式=用户条目
划分比例=[0.8, 0.1, 0.1]
fm评估=False
二值化评分阈值=0.0
评估:
批量大小=20
截断=[5, 10, 20]
验证指标=['ndcg', '召回率']
验证周期=1
测试指标=['ndcg', '召回率', '精确率', 'map', 'mrr', '命中率']
topk=100
保存路径=./saved/
模型:
嵌入维度=64
物品偏置=False
训练:
加速器=gpu
近似最近邻=无
批量大小=512
早停模式=最大化
早停耐心值=10
训练轮数=1000
gpu=1
梯度裁剪范数=无
初始化方法=xavier_normal
物品批量大小=1024
优化器=adam
学习率=0.001
线程数=10
采样方法=无
采样器=均匀
负样本数=1
排除历史=False
学习率调度器=无
随机种子=2022
权重衰减=0.0
tensorboard路径=无
[2023-08-24 10:51:42] 信息 Tensorboard日志保存在 ./tensorboard/BPR/ml-100k/2023-08-24-10-51-41-738329。
[2023-08-24 10:51:42] 信息 默认使用的字段设置为[用户ID, 物品ID, 评分]。如需更多字段,请使用"self._set_data_field()"重新设置。
[2023-08-24 10:51:42] 信息 保存目录:./saved/
[2023-08-24 10:51:42] 信息 BPR(
(得分函数): 内积评分器()
(损失函数): BPR损失()
(物品编码器): 嵌入(1575, 64, padding_idx=0)
(查询编码器): 嵌入(944, 64, padding_idx=0)
(采样器): 均匀采样器()
)
[2023-08-24 10:51:42] 信息 选择了GPU [8]。
[2023-08-24 10:51:45] 信息 训练: 轮次= 0 [ndcg@5=0.0111 召回率@5=0.0044 训练损失_0=0.6931]
[2023-08-24 10:51:45] 信息 训练时间: 0.88524秒。验证时间: 0.18036秒。GPU内存: 0.03/10.76 GB
[2023-08-24 10:51:45] 信息 ndcg@5有所提升。最佳值: 0.0111
[2023-08-24 10:51:45] 信息 最佳模型检查点保存在 ./saved/BPR/ml-100k/2023-08-24-10-51-41-738329.ckpt。
...
[2023-08-24 10:52:08] 信息 训练: 轮次= 34 [ndcg@5=0.1802 召回率@5=0.1260 训练损失_0=0.1901]
[2023-08-24 10:52:08] 信息 训练时间: 0.41784秒。验证时间: 0.32394秒。GPU内存: 0.03/10.76 GB
[2023-08-24 10:52:08] 信息 提前停止。由于指标ndcg@5在10轮内未有改善。
[2023-08-24 10:52:08] 信息 ndcg@5的最佳分数是0.1807,出现在第24轮
[2023-08-24 10:52:08] 信息 最佳模型检查点保存在 ./saved/BPR/ml-100k/2023-08-24-10-51-41-738329.ckpt。
[2023-08-24 10:52:08] 信息 测试: [ndcg@5=0.2389 召回率@5=0.1550 精确率@5=0.1885 map@5=0.1629 mrr@5=0.3845 命中率@5=0.5705 ndcg@10=0.2442 召回率@10=0.2391 精确率@10=0.1498 map@10=0.1447 mrr@10=0.4021 命中率@10=0.6999 ndcg@20=0.2701 召回率@20=0.3530 精确率@20=0.1170 map@20=0.1429 mrr@20=0.4109 命中率@20=0.8240]
如果你想更改模型或数据集,命令行已经准备就绪。
```bash
python run.py -m=NCF -d=ml-1m
-
支持的命令行参数:
参数 类型 描述 默认值 可选项 -m,--model 字符串 模型名称 BPR RecStudio中的所有模型 -d,--dataset 字符串 数据集名称 ml-100k RecStudio支持的所有数据集 --data_dir 字符串 数据集文件夹 datasets RecStudio可以读取的文件夹 mode 字符串 训练模式 light ['light','detail','tune'] --learning_rate 浮点数 学习率 0.001 --learner 字符串 优化器名称 adam ['adam','sgd','adasgd','rmsprop','sparse_adam'] --weight_decay 浮点数 优化器的权重衰减 0 --epochs 整数 训练轮数 20,50 --batch_size 整数 训练时的小批量大小 2048 --eval_batch_size 整数 评估时的小批量大小 128 --embed_dim 整数 嵌入层的输出大小 64 -
对于"ItemTowerRecommender",还支持一些额外的参数:
参数 类型 描述 默认值 可选项 --sampler 字符串 采样器名称 uniform ['uniform','popularity','midx_uni','midx_pop','cluster_uni','cluster_pop'] --negative_count 整数 负样本数量 1 正整数 -
对于"TwoTowerRecommender",在"ItemTowerRecommender"的基础上还支持一些额外的参数:
参数 类型 描述 默认值 可选项 --split_mode 字符串 数据集的划分方法 user_entry ['user','entry','user_entry']
以下是一些不明确参数的详细说明。
-
mode:在light模式和detail模式下,输出将显示在终端上,后者提供更详细的信息。tune模式将使用神经网络智能(NNI)显示一个漂亮的可视化界面。你可以使用类似config.yaml的配置文件运行tune.sh。有关NNI的更多详情,请参阅NNI文档。 -
sampler:uniform表示使用均匀采样器。popularity表示根据物品流行度进行采样(更受欢迎的物品被采样的概率更高)。midx_uni和midx_pop是midx动态采样器,更多详情请参阅FastVAE。cluster_uni和cluster_pop是cluster动态采样器,更多详情请参阅PRIS。 -
split_mode:user表示将所有用户分成训练/验证/测试数据集,这些数据集中的用户是互不相交的。entry表示将所有交互分成这三个数据集。user_entry表示将每个用户的交互分成三部分。
此外,你可以通过PyPi安装RecStudio:
pip install recstudio
基本用法如下:
import recstudio
recstudio.run(model="BPR", data_dir="./datasets/", dataset='ml-100k')
更详细的信息,请参阅我们的文档 http://recstudio.org.cn/docs/。
自动超参数调优
RecStudio集成了NNI模块,用于自动调优超参数。为了简单使用,你可以在bash中运行以下命令:
nnictl create --config ./nni-experiments/config/bpr.yaml --port 2023
根据个人需求配置nni-experiments/config/bpr.yaml和nni-experiments/search_space/bpr.yaml。
有关NNI的更多详细信息,请参阅NNI文档。
贡献
如果你遇到bug或有任何建议,请通过提交问题让我们知道。
我们欢迎所有贡献,从修复bug到新功能和扩展。
我们希望所有贡献首先在问题追踪器中讨论,然后通过PR进行。
团队
RecStudio由USTC BigData Lab开发和维护。
| 用户 | 贡献 |
|---|---|
| @DefuLian | 框架设计和构建 |
| @AngusHuang17 | 序列模型、文档、修复bug |
| @Xiuchen519 | 基于知识的模型、修复bug |
| @JennahF | NCF、CML、logisticMF模型 |
| @HERECJ | AutoEncoder模型 |
| @BinbinJin | IRGAN模型 |
| @pepsi2222 | 排序模型 |
| @echobelbo | 文档 |
| @jinbaobaojhr | 文档 |
许可证
RecStudio使用MIT许可证。











