
 访问官网
访问官网 Github
Github 论文
论文PyTorch 稀疏门控专家混合层
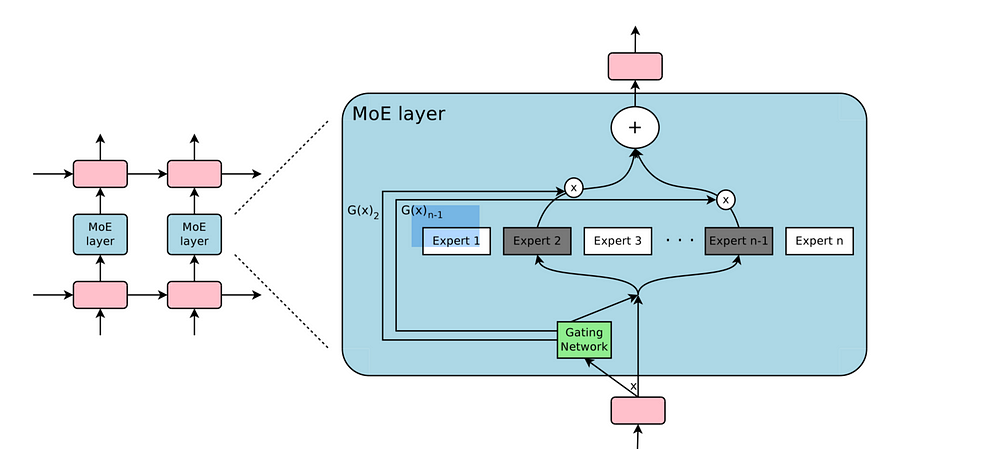
本仓库包含了论文《极其庞大的神经网络》中描述的稀疏门控专家混合(MoE)层在PyTorch中的重新实现。
from moe import MoE
import torch
# 实例化MoE层
model = MoE(input_size=1000, output_size=20, num_experts=10, hidden_size=66, k=4, noisy_gating=True)
X = torch.rand(32, 1000)
# 训练
model.train()
# 前向传播
y_hat, aux_loss = model(X)
# 评估
model.eval()
y_hat, aux_loss = model(X)
安装要求
要安装所需依赖,请运行:
pip install -r requirements.py
示例
文件example.py包含了一个最小工作示例,说明如何使用虚拟输入和目标来训练和评估MoE层。运行示例:
python example.py
CIFAR 10示例
文件cifar10_example.py包含了CIFAR 10数据集的最小工作示例。使用任意超参数且未完全收敛的情况下,它达到了39%的准确率。运行示例:
python cifar10_example.py
使用本项目的论文
FastMoE:快速专家混合训练系统 本实现被用作单GPU训练的PyTorch参考实现。
致谢
本代码基于此处的TensorFlow实现。
引用
@misc{rau2019moe,
title={Sparsely-gated Mixture-of-Experts PyTorch implementation},
author={Rau, David},
journal={https://github.com/davidmrau/mixture-of-experts},
year={2019}
}











