
 访问官网
访问官网 Github
Github 论文
论文Codec-SUPERB:声音编解码器语音处理通用性能基准测试
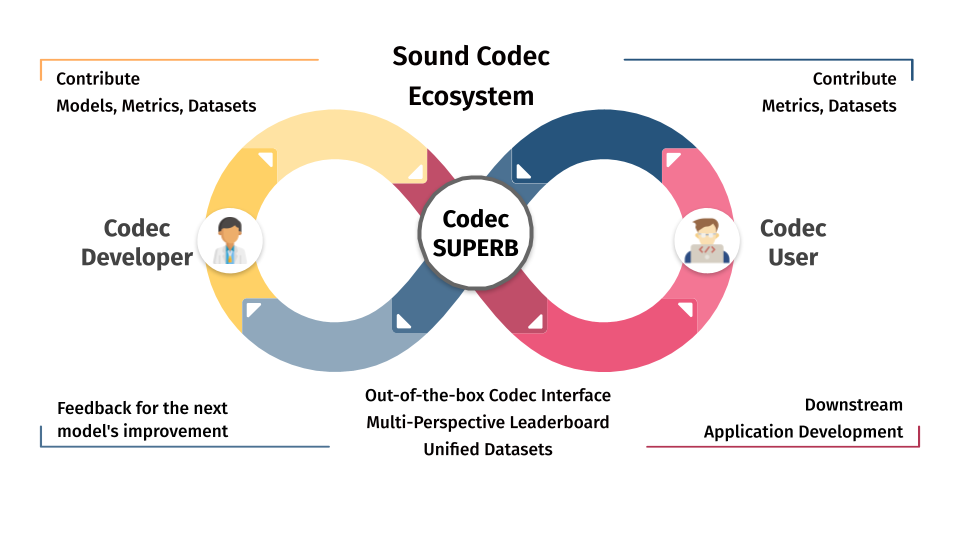
Codec-SUPERB是一个全面的基准测试,旨在评估音频编解码器模型在各种语音任务中的表现。我们的目标是通过保护和提高语音信息质量,促进社区合作并加速语音处理领域的进展。
目录
简介
Codec-SUPERB为评估声音编解码器模型设立了新的基准,提供了一个严格和透明的框架,用于评估各种语音处理任务的性能。我们的目标是促进创新,并在音频质量和处理效率方面设立新标准。
主要特点
即插即用的编解码器接口
Codec-SUPERB提供了一个直观的即插即用编解码器接口,便于集成和测试各种编解码器模型,有利于快速迭代和实验。
多角度排行榜
Codec-SUPERB独特的多角度评估和在线排行榜组合,通过提供全面的评估并促进开发者之间的透明竞争,推动了声音编解码器研究的创新。
标准化环境
我们确保标准化的测试环境,以保证所有模型的公平和一致比较。这种统一性使基准测试结果具有可靠性,使其具有普遍可解释性。
统一数据集
我们提供了一系列统一的数据集,精心策划以测试各种语音处理场景。这确保了模型在多样化的条件下进行评估,反映了真实世界的应用。
安装
git clone https://github.com/voidful/Codec-SUPERB.git
cd Codec-SUPERB
pip install -r requirements.txt
使用
排行榜
即插即用编解码器接口
from SoundCodec import codec
import torchaudio
# 获取所有可用的编解码器
print(codec.list_codec())
# 通过名称加载编解码器,以encodec为例
encodec_24k_6bps = codec.load_codec('encodec_24k_6bps')
# 加载音频
waveform, sample_rate = torchaudio.load('样本音频')
resampled_waveform = waveform.numpy()[-1]
data_item = {'audio': {'array': resampled_waveform,
'sampling_rate': sample_rate}}
# 提取单元
sound_unit = encodec_24k_6bps.extract_unit(data_item).unit
# 声音合成
decoded_waveform = encodec_24k_6bps.synth(sound_unit, local_save=False)['audio']['array']
引用
如果您在论文中使用了这段代码或结果,请引用我们的工作:
@misc{wu2024codecsuperb,
title={Codec-SUPERB: An In-Depth Analysis of Sound Codec Models},
author={Haibin Wu and Ho-Lam Chung and Yi-Cheng Lin and Yuan-Kuei Wu and Xuanjun Chen and Yu-Chi Pai and Hsiu-Hsuan Wang and Kai-Wei Chang and Alexander H. Liu and Hung-yi Lee},
year={2024},
eprint={2402.13071},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
@article{wu2024towards,
title={Towards audio language modeling-an overview},
author={Wu, Haibin and Chen, Xuanjun and Lin, Yi-Cheng and Chang, Kai-wei and Chung, Ho-Lam and Liu, Alexander H and Lee, Hung-yi},
journal={arXiv preprint arXiv:2402.13236},
year={2024}
}
贡献
我们非常鼓励贡献,无论是添加新的编解码器模型、扩展数据集收集,还是增强基准测试框架。更多详情请参阅CONTRIBUTING.md。
许可证
本项目采用MIT许可证 - 详情请见LICENSE文件。











