
 Github
Github 文档
文档文本正规化与逆文本正规化
0. 简介
- **必读文档**(中文):https://mp.weixin.qq.com/s/q_11lck78qcjylHCi6wVsQ
WeTextProcessing:以生产为先、生产就绪的文本处理工具包
0.1 文本正规化
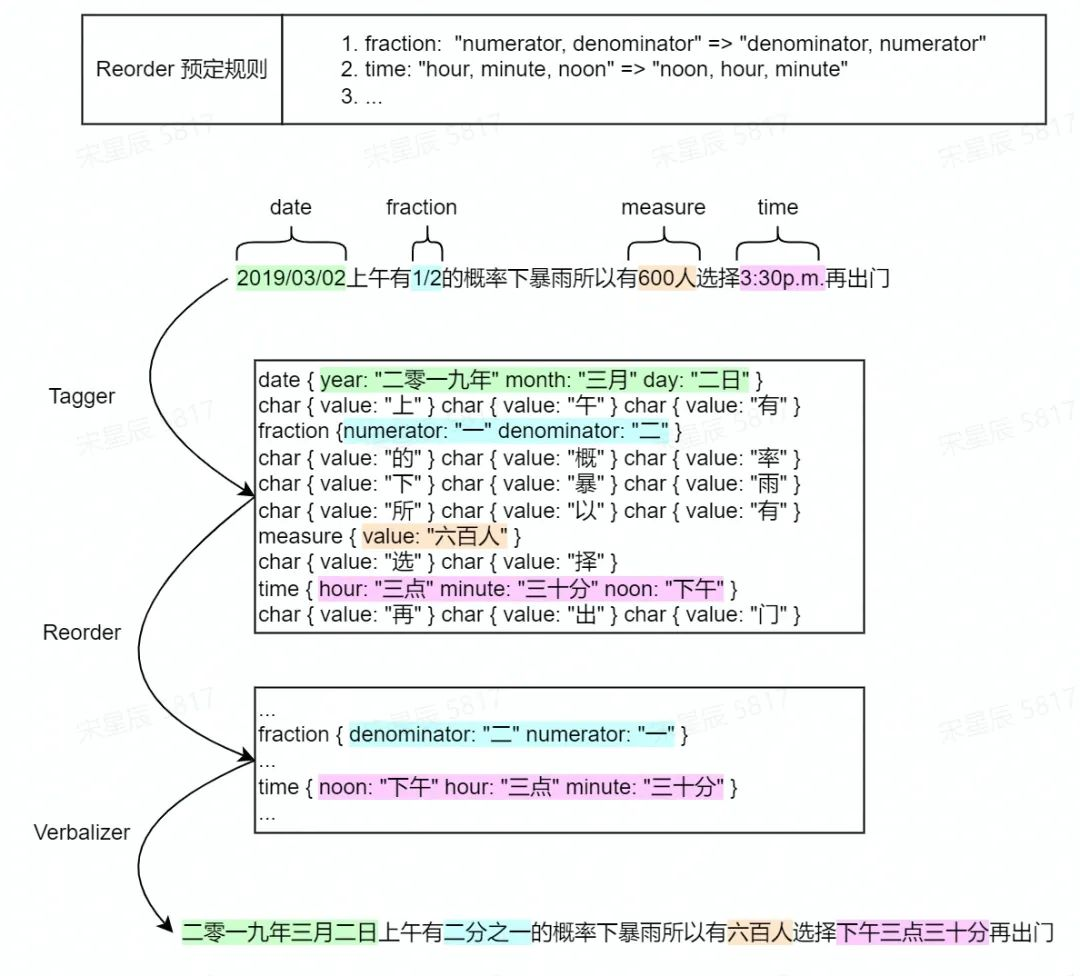
0.2 逆文本正规化

1. 使用方法
1.1 快速开始:
# 安装
pip install WeTextProcessing
命令行用法:
wetn --text "2.5平方电线"
weitn --text "二点五平方电线"
Python 用法:
from itn.chinese.inverse_normalizer import InverseNormalizer
from tn.chinese.normalizer import Normalizer as ZhNormalizer
from tn.english.normalizer import Normalizer as EnNormalizer
# 注意:当参数与默认值不同时,必须重新构图,重新构图时请务必指定 `overwrite_cache=True`
zh_tn_text = "你好 WeTextProcessing 1.0,船新版本儿,船新体验儿,简直666,9和10"
zh_itn_text = "你好 WeTextProcessing 一点零,船新版本儿,船新体验儿,简直六六六,九和六"
en_tn_text = "Hello WeTextProcessing 1.0, life is short, just use wetext, 666, 9 and 10"
zh_tn_model = ZhNormalizer(remove_erhua=True, overwrite_cache=True)
zh_itn_model = InverseNormalizer(enable_0_to_9=False, overwrite_cache=True)
en_tn_model = EnNormalizer(overwrite_cache=True)
print("中文 TN (去除儿化音,重新在线构图):\n\t{} => {}".format(zh_tn_text, zh_tn_model.normalize(zh_tn_text)))
print("中文ITN (小于10的单独数字不转换,重新在线构图):\n\t{} => {}".format(zh_itn_text, zh_itn_model.normalize(zh_itn_text)))
print("英文 TN (暂时还没有可控的选项,后面会加...):\n\t{} => {}\n".format(en_tn_text, en_tn_model.normalize(en_tn_text)))
zh_tn_model = ZhNormalizer(overwrite_cache=False)
zh_itn_model = InverseNormalizer(overwrite_cache=False)
en_tn_model = EnNormalizer(overwrite_cache=False)
print("中文 TN (复用之前编译好的图):\n\t{} => {}".format(zh_tn_text, zh_tn_model.normalize(zh_tn_text)))
print("中文ITN (复用之前编译好的图):\n\t{} => {}".format(zh_itn_text, zh_itn_model.normalize(zh_itn_text)))
print("英文 TN (复用之前编译好的图):\n\t{} => {}\n".format(en_tn_text, en_tn_model.normalize(en_tn_text)))
zh_tn_model = ZhNormalizer(remove_erhua=False, overwrite_cache=True)
zh_itn_model = InverseNormalizer(enable_0_to_9=True, overwrite_cache=True)
print("中文 TN (不去除儿化音,重新在线构图):\n\t{} => {}".format(zh_tn_text, zh_tn_model.normalize(zh_tn_text)))
print("中文ITN (小于10的单独数字也进行转换,重新在线构图):\n\t{} => {}\n".format(zh_itn_text, zh_itn_model.normalize(zh_itn_text)))
1.2 高级用法:
自定义规则并使用 C++ 运行时部署 WeTextProcessing!
对于想修改和调整 tn/itn 规则以修复错误案例的用户,请尝试:
git clone https://github.com/wenet-e2e/WeTextProcessing.git
cd WeTextProcessing
pip install -r requirements.txt
pre-commit install # 保持代码整洁
# `overwrite_cache` 将根据你对 tn/chinese/rules/xx.py(itn/chinese/rules/xx.py)的修改重建所有规则。
# 重建后,你可以在 `$PWD/tn` 和 `$PWD/itn` 找到新的 far 文件。
python -m tn --text "2.5平方电线" --overwrite_cache
python -m itn --text "二点五平方电线" --overwrite_cache
成功重建规则后,你可以使用已安装的 PyPI 包部署它们:
# tn 用法
>>> from tn.chinese.normalizer import Normalizer
>>> normalizer = Normalizer(cache_dir="PATH_TO_GIT_CLONED_WETEXTPROCESSING/tn")
>>> normalizer.normalize("2.5平方电线")
# itn 用法
>>> from itn.chinese.inverse_normalizer import InverseNormalizer
>>> invnormalizer = InverseNormalizer(cache_dir="PATH_TO_GIT_CLONED_WETEXTPROCESSING/itn")
>>> invnormalizer.normalize("二点五平方电线")
或者使用 C++ 运行时:
cmake -B build -S runtime -DCMAKE_BUILD_TYPE=Release
cmake --build build
# tn 用法
cache_dir=PATH_TO_GIT_CLONED_WETEXTPROCESSING/tn
./build/processor_main --tagger $cache_dir/zh_tn_tagger.fst --verbalizer $cache_dir/zh_tn_verbalizer.fst --text "2.5平方电线"
# itn 用法
cache_dir=PATH_TO_GIT_CLONED_WETEXTPROCESSING/itn
./build/processor_main --tagger $cache_dir/zh_itn_tagger.fst --verbalizer $cache_dir/zh_itn_verbalizer.fst --text "二点五平方电线"
2. TN 流程
请参考 TN.README
3. ITN 流程
请参考 ITN.README
讨论与交流
对于中国用户,你也可以扫描左侧的二维码关注我们的 WeNet 官方公众号。 我们创建了一个微信群,以便更好地讨论和更快地回复。 请扫描右侧的个人二维码,该人负责邀请你加入聊天群。
 |  |
|---|
或者你可以直接在 Github Issues 上讨论。
致谢
- 感谢基础库如 OpenFst 和 Pynini 的作者。
- 感谢 NeMo 团队和 NeMo 开源社区。
- 感谢 马振翔、杜家豫 和 SpeechColab 组织。
- 参考了 Pynini 中读取 FAR 和在 C++ 运行时打印最短路径的方法。
- 参考了 NeMo 的 TN 中用于构建标注器图的数据。
- 参考了 chinese_text_normalization 的 ITN 中用于构建标注器图的数据。











