
 Github
Github Huggingface
HuggingfaceControlNetPlus
English | 简体中文
ControlNet++:用于图像生成和编辑的多合一ControlNet!

我们设计了一种新的架构,可以在条件文本到图像生成中支持10多种控制类型,并能生成视觉上可与Midjourney相媲美的高分辨率图像。该网络基于原始ControlNet架构,我们提出了两个新模块:1. 扩展原始ControlNet以使用相同的网络参数支持不同的图像条件。2. 支持多条件输入而不增加计算负载,这对于想要详细编辑图像的设计师特别重要,不同条件使用相同的条件编码器,无需增加额外的计算或参数。我们在SDXL上进行了全面的实验,并在控制能力和美学评分方面都取得了出色的性能。我们向开源社区发布了该方法和模型,让每个人都能享受其中。
如果您觉得它有用,请给我一个星标,非常感谢!
SDXL ProMax版本已经发布!!!尽情享用吧!!!
很抱歉,由于项目的收支难以平衡,GPU资源被分配给了其他更有可能盈利的项目,SD3的训练已停止,直到我找到足够的GPU支持。我会尽最大努力寻找GPU继续训练。如果这给您带来不便,我真诚地为此道歉。我想感谢每一个喜欢这个项目的人,你们的支持是我前进的动力。
注意:我们将promax模型以promax后缀放在同一个huggingface模型仓库中,详细说明将稍后添加。
Promax模型中的高级编辑功能
图块去模糊






图块变化






图块超分辨率
以下示例展示从1M分辨率 --> 9M分辨率




图像修复






图像外扩






模型优势
- 使用类似novelai的桶训练方法,可以生成任意宽高比的高分辨率图像
- 使用大量高质量数据(超过1000万张图像),数据集覆盖多样化场景
- 使用类似DALLE.3的重新描述提示词技术,利用CogVLM生成详细描述,具有良好的提示词遵循能力
- 训练过程中使用多种有效技巧,包括但不限于数据增强、多重损失函数、多分辨率等
- 与原始ControlNet相比,使用几乎相同的参数量。网络参数和计算量没有明显增加
- 支持10多种控制条件,单一条件下的性能与独立训练相比没有明显下降
- 支持多条件生成,条件融合在训练过程中学习。无需设置超参数或设计提示词
- 与其他开源SDXL模型兼容,如BluePencilXL、CounterfeitXL。与其他Lora模型兼容
我们发布的其他热门模型
https://huggingface.co/xinsir/controlnet-openpose-sdxl-1.0
https://huggingface.co/xinsir/controlnet-scribble-sdxl-1.0
https://huggingface.co/xinsir/controlnet-tile-sdxl-1.0
https://huggingface.co/xinsir/controlnet-canny-sdxl-1.0
新闻
- [2024年6月7日] 发布
ControlNet++及预训练模型 - [2024年6月7日] 发布推理代码(单条件和多条件)
- [2024年7月13日] 发布具有高级编辑功能的
ProMax ControlNet++
待办事项:
- 为gradio开发ControlNet++
- 为Comfyui开发ControlNet++
- 发布训练代码和训练指南
- 发布arXiv论文
视觉示例
Openpose
这是最重要的controlnet模型之一,我们在训练这个模型时使用了多种技巧,效果与https://huggingface.co/xinsir/controlnet-openpose-sdxl-1.0相当,在姿势控制方面达到了最先进的水平。
为了使openpose模型发挥最佳性能,你应该替换controlnet_aux包中的draw_pose函数(comfyui有自己的controlnet_aux包),详情请参考推理脚本。





深度图





Canny边缘检测
这是最重要的controlnet模型之一,canny模型与线条艺术、动漫线条艺术和mlsd进行了混合训练。在处理任何细线条时表现稳健,该模型是降低变形率的关键,建议使用细线条重绘手部/脚部。





线条艺术





动漫线条艺术





Mlsd





涂鸦
这是最重要的controlnet模型之一,涂鸦模型可以支持任何线条宽度和类型。效果与https://huggingface.co/xinsir/controlnet-scribble-sdxl-1.0相当,让每个人都成为灵魂画师。





Hed边缘检测





Pidi(软边缘)





Teed(512检测,更高分辨率,更细线条)





分割





正常





多重控制视觉示例
Openpose + Canny
注意:使用姿势骨架控制人体姿势,用细线绘制手/脚细节以避免变形



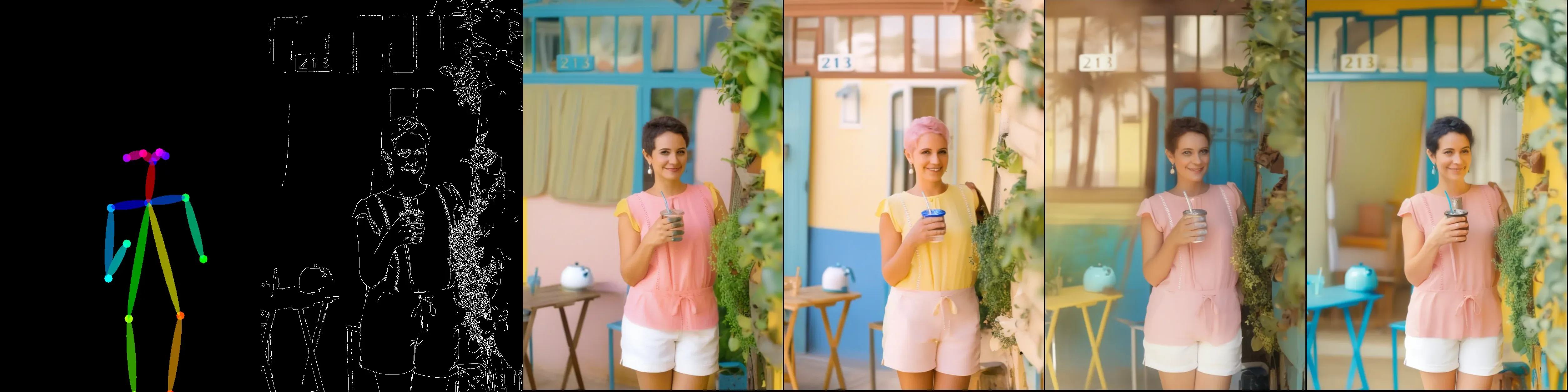


Openpose + 深度图
注意:深度图包含详细信息,建议将深度用于背景,姿势骨架用于前景






Openpose + 涂鸦
注意:涂鸦是一种强线条模型,如果你想绘制轮廓不严格的东西,可以使用它。Openpose + 涂鸦给你更多自由来生成初始图像,然后你可以使用细线编辑细节。






Openpose + 法线图






Openpose + 分割图






数据集
我们收集了大量高质量图像。这些图像经过严格筛选和标注,涵盖广泛的主题,包括摄影、动漫、自然、midjourney等。
网络架构
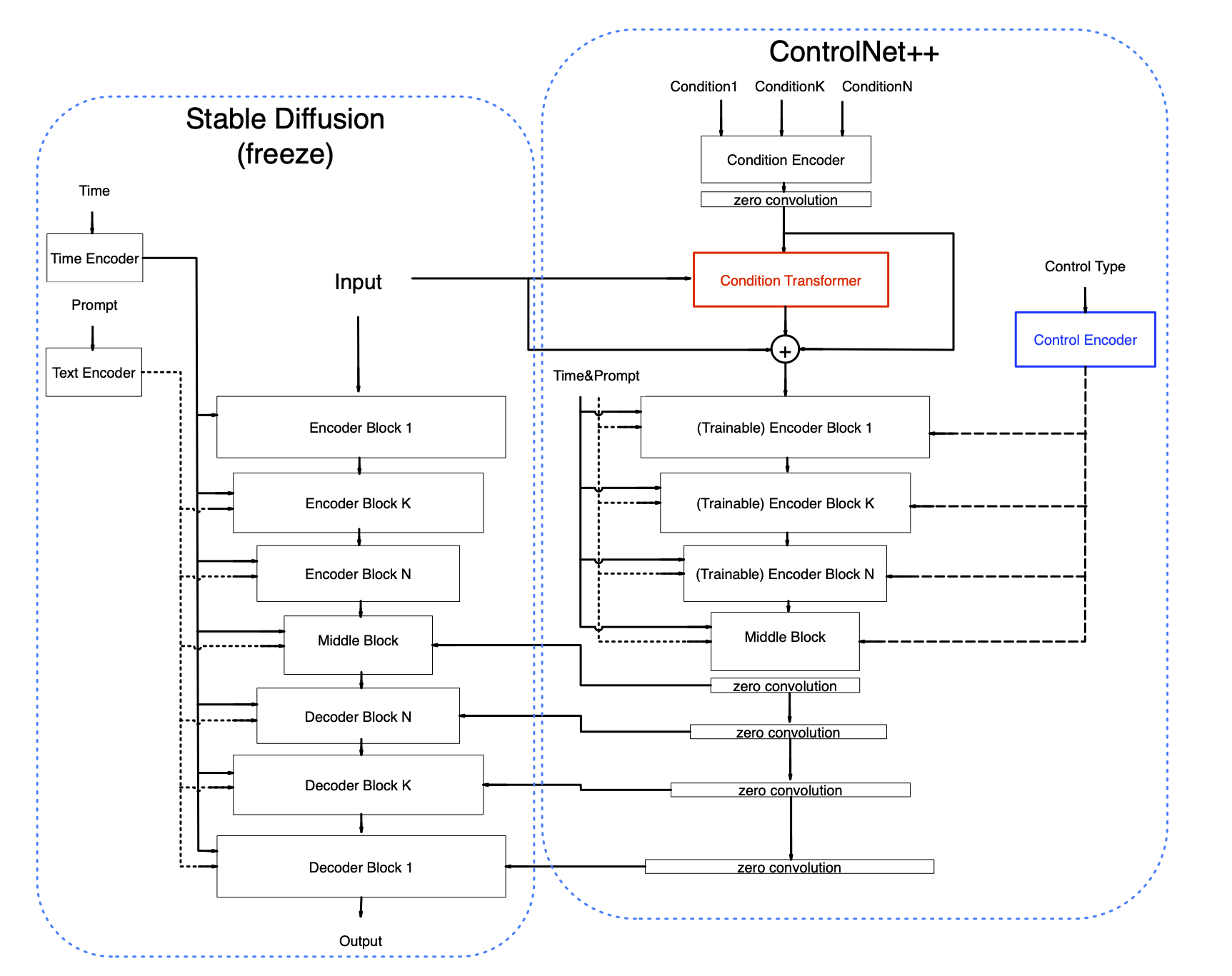 我们提出了ControlNet++中的两个新模块,分别名为条件转换器和控制编码器。我们稍微修改了一个旧模块以提高其表示能力。此外,我们提出了一个统一的训练策略,以在一个阶段实现单一和多重控制。
我们提出了ControlNet++中的两个新模块,分别名为条件转换器和控制编码器。我们稍微修改了一个旧模块以提高其表示能力。此外,我们提出了一个统一的训练策略,以在一个阶段实现单一和多重控制。
控制编码器
对于每个条件,我们分配一个控制类型ID,例如,openpose--(1, 0, 0, 0, 0, 0),深度--(0, 1, 0, 0, 0, 0),多条件将如(openpose, 深度)--(1, 1, 0, 0, 0, 0)。在控制编码器中,控制类型ID将转换为控制类型嵌入(使用正弦位置嵌入),然后我们使用单个线性层将控制类型嵌入投影到与时间嵌入相同的维度。控制类型特征被添加到时间嵌入中以指示不同的控制类型,这个简单的设置可以帮助ControlNet区分不同的控制类型,因为时间嵌入倾向于对整个网络产生全局影响。无论是单一条件还是多重条件,都有一个唯一的对应控制类型ID。
条件转换器
我们扩展了ControlNet以支持同时使用同一网络处理多个控制输入。条件转换器用于组合不同的图像条件特征。我们的方法有两个主要创新,首先,不同条件共享同一个条件编码器,使网络更简单轻量。这与其他主流方法如T2I或UniControlNet不同。其次,我们添加了一个transformer层来交换原始图像和条件图像的信息,而不是直接使用transformer的输出,我们用它来预测原始条件特征的条件偏差。这有点像ResNet,我们通过实验发现这种设置可以明显提高网络性能。
修改后的条件编码器
ControlNet的原始条件编码器是卷积层和Silu激活的堆叠。我们没有改变编码器架构,只是增加了卷积通道以获得一个"胖"编码器。这可以明显提高网络性能。原因是我们对所有图像条件共享同一编码器,因此要求编码器具有更高的表示能力。原始设置对单一条件可能表现良好,但对10多个条件则不太理想。注意,使用原始设置也可以,只是会在一定程度上牺牲图像生成质量。
统一训练策略
仅用单一条件训练可能会受到数据多样性的限制。例如,openpose要求你用含有人物的图像训练,而mlsd则需要用含有线条的图像训练,这可能会影响生成未见过物体时的性能。此外,训练不同条件的难度不同,要让所有条件同时收敛并达到各自单一条件的最佳性能是很棘手的。最后,我们倾向于同时使用两个或更多条件,多条件训练将使不同条件的融合更加平滑,并提高网络的鲁棒性(因为单一条件学习的知识有限)。我们提出了一个统一的训练阶段,以同时实现单一条件的优化收敛和多条件融合。
控制模式
ControlNet++需要向网络传递一个控制类型ID。我们将10多种控制合并为6种控制类型,每种类型的含义如下: 0 -- openpose 1 -- 深度 2 -- 粗线(涂鸦/hed/软边缘/ted-512) 3 -- 细线(canny/mlsd/线稿/动漫线稿/ted-1280) 4 -- 法线 5 -- 分割
安装
我们推荐Python版本 >= 3.8,你可以使用以下命令设置虚拟环境:
conda create -n controlplus python=3.8
conda activate controlplus
pip install -r requirements.txt
下载权重
推理脚本
我们为每个控制条件提供了推理脚本。请参考它以获取更多详细信息。
存在一些预处理差异,为获得最佳openpose控制性能,请执行以下操作: 在controlnet_aux包中找到util.py,用以下代码替换draw_bodypose函数
def draw_bodypose(canvas: np.ndarray, keypoints: List[Keypoint]) -> np.ndarray:
"""
在给定画布上绘制表示身体姿势的关键点和肢体。
参数:
canvas (np.ndarray):表示画布(图像)的3D numpy数组,用于绘制身体姿势。
keypoints (List[Keypoint]):表示要绘制的身体关键点的Keypoint对象列表。
返回:
np.ndarray:表示绘制了身体姿势的修改后画布的3D numpy数组。
注意:
函数期望关键点的x和y坐标已归一化到0和1之间。
"""
H, W, C = canvas.shape
if max(W, H) < 500:
ratio = 1.0
elif max(W, H) >= 500 and max(W, H) < 1000:
ratio = 2.0
elif max(W, H) >= 1000 and max(W, H) < 2000:
ratio = 3.0
elif max(W, H) >= 2000 and max(W, H) < 3000:
ratio = 4.0
elif max(W, H) >= 3000 and max(W, H) < 4000:
ratio = 5.0
elif max(W, H) >= 4000 and max(W, H) < 5000:
ratio = 6.0
else:
ratio = 7.0
stickwidth = 4
limbSeq = [
[2, 3], [2, 6], [3, 4], [4, 5],
[6, 7], [7, 8], [2, 9], [9, 10],
[10, 11], [2, 12], [12, 13], [13, 14],
[2, 1], [1, 15], [15, 17], [1, 16],
[16, 18],
]
colors = [[255, 0, 0], [255, 85, 0], [255, 170, 0], [255, 255, 0], [170, 255, 0], [85, 255, 0], [0, 255, 0],
[0, 255, 85], [0, 255, 170], [0, 255, 255], [0, 170, 255], [0, 85, 255], [0, 0, 255], [85, 0, 255],
[170, 0, 255], [255, 0, 255], [255, 0, 170], [255, 0, 85]]
for (k1_index, k2_index), color in zip(limbSeq, colors):
keypoint1 = keypoints[k1_index - 1]
keypoint2 = keypoints[k2_index - 1]
if keypoint1 is None or keypoint2 is None:
continue
Y = np.array([keypoint1.x, keypoint2.x]) * float(W)
X = np.array([keypoint1.y, keypoint2.y]) * float(H)
mX = np.mean(X)
mY = np.mean(Y)
length = ((X[0] - X[1]) ** 2 + (Y[0] - Y[1]) ** 2) ** 0.5
angle = math.degrees(math.atan2(X[0] - X[1], Y[0] - Y[1]))
polygon = cv2.ellipse2Poly((int(mY), int(mX)), (int(length / 2), int(stickwidth * ratio)), int(angle), 0, 360, 1)
cv2.fillConvexPoly(canvas, polygon, [int(float(c) * 0.6) for c in color])
for keypoint, color in zip(keypoints, colors):
if keypoint is None:
continue
x, y = keypoint.x, keypoint.y
x = int(x * W)
y = int(y * H)
cv2.circle(canvas, (int(x), int(y)), int(4 * ratio), color, thickness=-1)
返回画布
对于单一条件推理,你应该提供一个提示和一个控制图像,在 Python 文件中修改相应的行。
```shell
python controlnet_union_test_openpose.py
对于多条件推理,你应确保你的输入 image_list 与你的 control_type 兼容,例如,如果你想使用 openpose 和深度控制,image_list --> [controlnet_img_pose, controlnet_img_depth, 0, 0, 0, 0],control_type --> [1, 1, 0, 0, 0, 0]。更多细节请参考 controlnet_union_test_multi_control.py。 理论上,你不需要为不同的条件设置条件比例,网络被设计和训练成自然融合不同的条件。默认设置是每个条件输入为 1.0,这与多条件训练相同。 然而,如果你想增加某些特定输入条件的影响,你可以在条件变换器模块中调整条件比例。在该模块中,输入条件将与偏差预测一起添加到源图像特征中。 将其乘以特定比例会产生很大影响(但可能会导致一些未知结果)。
python controlnet_union_test_multi_control.py











