
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文英文版本 English
Wonder3D
使用跨域扩散的单图像到3D技术(CVPR 2024 亮点论文)
论文 | 项目主页 | Hugging Face 演示 | @camenduru 的 Colab

Wonder3D 仅需 2 ∼ 3 分钟就能从单视图图像重建高度详细的带纹理网格。Wonder3D 首先通过跨域扩散模型生成一致的多视图法线图及对应的彩色图像,然后利用新颖的法线融合方法实现快速高质量重建。
新闻
- 修复了一个严重的训练错误。'configs/train/stage1-mix-6views-lvis.yaml' 中的 "zero_init_camera_projection" 应该为 False。否则,训练中的域控制和姿态控制将无效。
- 2024.03.19 查看我们的新模型 GeoWizard,它能从单一图像联合生成高保真度的深度图和法线图。
- 2024.05.24 我们发布了一个大型原生3D扩散模型 CraftsMan3D,它直接在3D表示上训练,因此能够生成复杂结构。
- 2024.05.29 我们发布了一个更强大的多视图跨域扩散模型 Era3D,它能联合生成512x512的彩色图像和法线图,更重要的是,Era3D能自动计算输入图像的焦距和仰角,从而避免几何畸变。
使用方法
# 首先克隆仓库,并在仓库中使用以下命令
import torch
import requests
from PIL import Image
import numpy as np
from torchvision.utils import make_grid, save_image
from diffusers import DiffusionPipeline # 仅在 diffusers[torch]==0.19.3 上测试过,可能与较新版本的 diffusers 冲突
def load_wonder3d_pipeline():
pipeline = DiffusionPipeline.from_pretrained(
'flamehaze1115/wonder3d-v1.0', # 或使用本地检查点 './ckpts'
custom_pipeline='flamehaze1115/wonder3d-pipeline',
torch_dtype=torch.float16
)
# 启用 xformers
pipeline.unet.enable_xformers_memory_efficient_attention()
if torch.cuda.is_available():
pipeline.to('cuda:0')
return pipeline
pipeline = load_wonder3d_pipeline()
# 下载示例图像
cond = Image.open(requests.get("https://d.skis.ltd/nrp/sample-data/lysol.png", stream=True).raw)
# 物体应位于中心并调整大小至图像高度的80%
cond = Image.fromarray(np.array(cond)[:, :, :3])
# 运行管道!
images = pipeline(cond, num_inference_steps=20, output_type='pt', guidance_scale=1.0).images
result = make_grid(images, nrow=6, ncol=2, padding=0, value_range=(0, 1))
save_image(result, 'result.png')
合作
我们的总体使命是提高3D AIGC的速度、可负担性和质量,使3D内容创作对所有人都可及。尽管近年来取得了重大进展,但我们认识到前面还有很长的路要走。我们热切地邀请您参与讨论并探索任何形式的潜在合作。如果您有兴趣与我们联系或合作,请随时通过电子邮件(xxlong@connect.hku.hk)与我们联系。
新闻
- 2024.02 我们发布了训练代码。欢迎在您的个人数据上训练wonder3D。
- 2023.10 我们发布了推理模型和代码。
推理准备
Linux 系统设置
conda create -n wonder3d
conda activate wonder3d
pip install -r requirements.txt
pip install git+https://github.com/NVlabs/tiny-cuda-nn/#subdirectory=bindings/torch
Windows 系统设置
请切换到 main-windows 分支查看 Windows 设置详情。
Docker 设置
训练
这里我们提供两个训练脚本 train_mvdiffusion_image.py 和 train_mvdiffusion_joint.py。
训练分为两个阶段:1) 首先通过随机选择法线或颜色标志来训练多视图注意力;2) 将跨域注意力模块添加到 SD 模型中,并仅优化新添加的参数。
您需要修改配置文件 configs/train/stage1-mix-6views-lvis.yaml 和 configs/train/stage2-joint-6views-lvis.yaml 中包含数据的 root_dir。
# 第一阶段:
accelerate launch --config_file 8gpu.yaml train_mvdiffusion_image.py --config configs/train/stage1-mix-6views-lvis.yaml
# 第二阶段
accelerate launch --config_file 8gpu.yaml train_mvdiffusion_joint.py --config configs/train/stage2-joint-6views-lvis.yaml
准备训练数据
推理
- 可选。如果您连接 Hugging Face 有困难,请确保您已下载以下模型。 下载检查点并放入根文件夹。
如果您在中国大陆,可以通过阿里云下载。
Wonder3D
|-- ckpts
|-- unet
|-- scheduler
|-- vae
...
然后修改文件 ./configs/mvdiffusion-joint-ortho-6views.yaml,设置 pretrained_model_name_or_path="./ckpts"
- 下载 SAM 模型。将其放入
sam_pt文件夹。
Wonder3D
|-- sam_pt
|-- sam_vit_h_4b8939.pth
- 将前景掩码预测为 alpha 通道。我们使用 Clipdrop 交互式地分割前景对象。
您也可以使用
rembg来移除背景。
# !pip install rembg
import rembg
result = rembg.remove(result)
result.show()
- 运行 Wonder3d 生成多视图一致的法线图和彩色图像。然后您可以在
./outputs文件夹中查看结果。(我们使用rembg移除结果的背景,但分割并不总是完美的。可以考虑使用 Clipdrop 为生成的法线图和彩色图像获取掩码,因为掩码质量会显著影响重建网格的质量。)
accelerate launch --config_file 1gpu.yaml test_mvdiffusion_seq.py \
--config configs/mvdiffusion-joint-ortho-6views.yaml validation_dataset.root_dir={your_data_path} \
validation_dataset.filepaths=['your_img_file'] save_dir={your_save_path}
示例:
accelerate launch --config_file 1gpu.yaml test_mvdiffusion_seq.py \
--config configs/mvdiffusion-joint-ortho-6views.yaml validation_dataset.root_dir=./example_images \
validation_dataset.filepaths=['owl.png'] save_dir=./outputs
交互式推理:运行本地 Gradio 演示。(仅生成法线和颜色,不进行重建)
python gradio_app_mv.py # 生成多视图法线和颜色
- 网格提取
Instant-NSR 网格提取
cd ./instant-nsr-pl
python launch.py --config configs/neuralangelo-ortho-wmask.yaml --gpu 0 --train dataset.root_dir=../{your_save_path}/cropsize-{crop_size}-cfg{guidance_scale:.1f}/ dataset.scene={scene}
示例:
cd ./instant-nsr-pl
python launch.py --config configs/neuralangelo-ortho-wmask.yaml --gpu 0 --train dataset.root_dir=../outputs/cropsize-192-cfg1.0/ dataset.scene=owl
我们生成的法线和彩色图像是在正交视图中定义的,因此重建的网格也在正交相机空间中。如果您使用 MeshLab 查看网格,可以在 View 选项卡中点击 Toggle Orthographic Camera。
交互式推理:运行本地 Gradio 演示。(首先生成法线和颜色,然后进行重建。无需先执行 gradio_app_mv.py。)
python gradio_app_recon.py
基于 NeuS 的网格提取
由于有许多关于 instant-nsr-pl 在 Windows 上设置的抱怨,我们提供了基于 NeuS 的重建,这可能会避免一些依赖问题。 NeuS 消耗的 GPU 内存较少,且无需参数调整即可生成光滑的表面。然而,NeuS 消耗的时间较多,其纹理可能不太清晰。如果您对时间不敏感,我们建议使用 NeuS 进行优化,因为它具有较强的稳健性。
cd ./NeuS
bash run.sh 输出文件夹路径 场景名称
常见问题
问:获得更好结果的技巧。
- Wonder3D 对输入图像的朝向较为敏感。根据实验,正面朝向的图像通常能得到良好的重建效果。
- 受资源限制,当前实现仅支持有限视角(6 个视角)和低分辨率(256x256)。任何图像都会先调整为 256x256 大小进行生成,因此在这种降采样后仍能保持清晰和锐利特征的图像会产生较好的结果。
- 有遮挡的图像会导致重建效果较差,因为 6 个视角无法覆盖完整的物体。遮挡较少的图像会产生更好的结果。
- 增加 instant-nsr-pl 中的优化步骤,修改
instant-nsr-pl/configs/neuralangelo-ortho-wmask.yaml中的trainer.max_steps: 3000为更多步骤,如trainer.max_steps: 10000。更长的优化时间会带来更好的纹理效果。
问:生成视图的仰角和方位角是多少?
答:与之前的工作(如 Zero123、SyncDreamer 和 One2345)采用物体世界坐标系不同,我们的视图是在输入图像的相机坐标系中定义的。六个视图位于输入图像相机坐标系中仰角为 0 度的平面上。因此,我们不需要估计输入图像的仰角。六个视图的方位角分别为 0、45、90、180、-90、-45 度。
问:生成视图的焦距是多少?
答:我们假设输入图像是由正交相机拍摄的,因此生成的视图也在正交空间中。这种设计使我们的模型对非真实图像保持较强的泛化能力,但有时可能会在真实拍摄的图像上受到焦距畸变的影响。
关于相机系统和相机姿态的详细信息
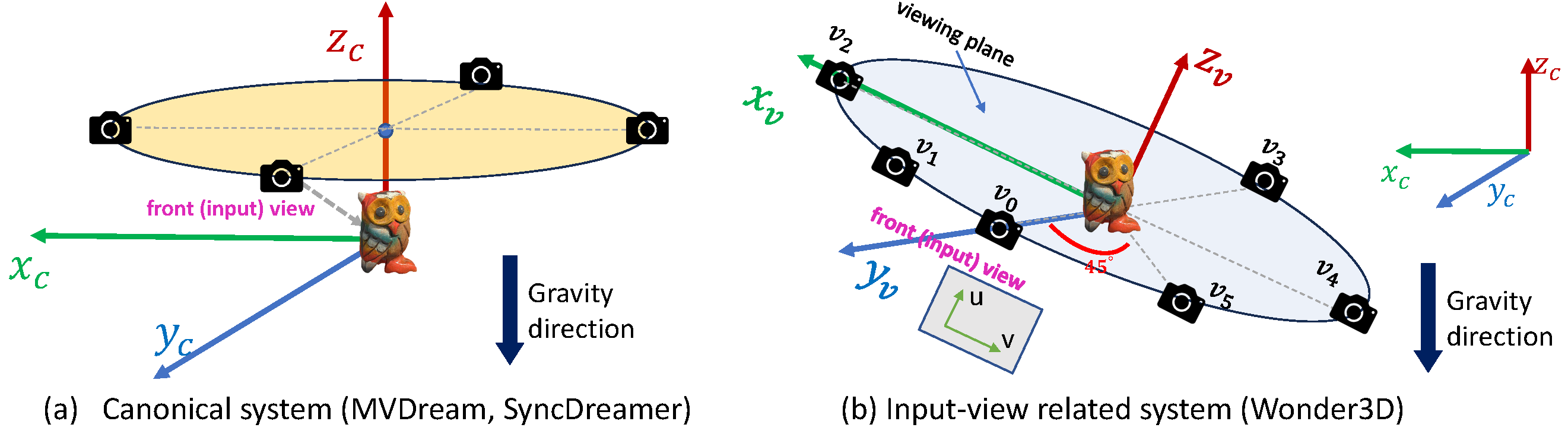 在实践中,假设目标物体沿重力方向放置。
在实践中,假设目标物体沿重力方向放置。
- 规范坐标系。 一些先前的工作(如 MVDream 和 SyncDreamer)为所有物体采用共享的规范系统,其中 $Z_c$ 轴与重力方向相同(a)。
- 输入视图相关系统。 Wonder3D 为每个物体采用一个独立的坐标系,该坐标系与输入视图相关。其 $Z_v$ 和 $X_v$ 轴与 2D 输入图像空间的 UV 维度对齐,其 $Y_v$ 轴垂直于 2D 图像平面并通过 ROI(感兴趣区域)的中心(b)。
- 相机姿态。 Wonder3D 输出 6 个视图 ${v_i, i=0,...,5}$,这些视图在输入视图相关系统的 $X_vOY_v$ 平面上以固定半径采样,其中前视图 $v_0$ 初始化为输入视图,其他视图以预定义的方位角采样(见(b))。
致谢
我们大量借鉴了以下代码库。非常感谢这些作者分享他们的代码。
许可证
Wonder3D 采用 AGPL-3.0 许可,因此任何包含 wonder3d 代码或训练模型(包括预训练或自定义训练)的下游解决方案和产品(包括云服务)都应开源以遵守 AGPL 条件。如果您对 Wonder3D 的使用有任何疑问,请先与我们联系。
引用
如果您在项目中发现本仓库有用,请引用以下工作。:)
@article{long2023wonder3d,
title={Wonder3D: Single Image to 3D using Cross-Domain Diffusion},
author={Long, Xiaoxiao and Guo, Yuan-Chen and Lin, Cheng and Liu, Yuan and Dou, Zhiyang and Liu, Lingjie and Ma, Yuexin and Zhang, Song-Hai and Habermann, Marc and Theobalt, Christian and others},
journal={arXiv preprint arXiv:2310.15008},
year={2023}
}











