
 Github
Github Huggingface
Huggingface 论文
论文LongQLoRA:延长大语言模型上下文长度的高效有效方法
技术报告
技术报告:LongQLoRA:高效有效地延长大语言模型上下文长度的方法
简介
LongQLoRA是一种内存高效且有效的方法,可以使用较少的训练GPU来延长大语言模型的上下文长度。 在单个32GB V100 GPU上,LongQLoRA可以将LLaMA2 7B和13B的上下文长度从4096扩展到8192,甚至达到12k。 LongQLoRA在仅经过1000步微调后,就在PG19和Proof-pile数据集上达到了具有竞争力的困惑度性能,我们的模型优于LongLoRA,并且非常接近MPT-7B-8K。
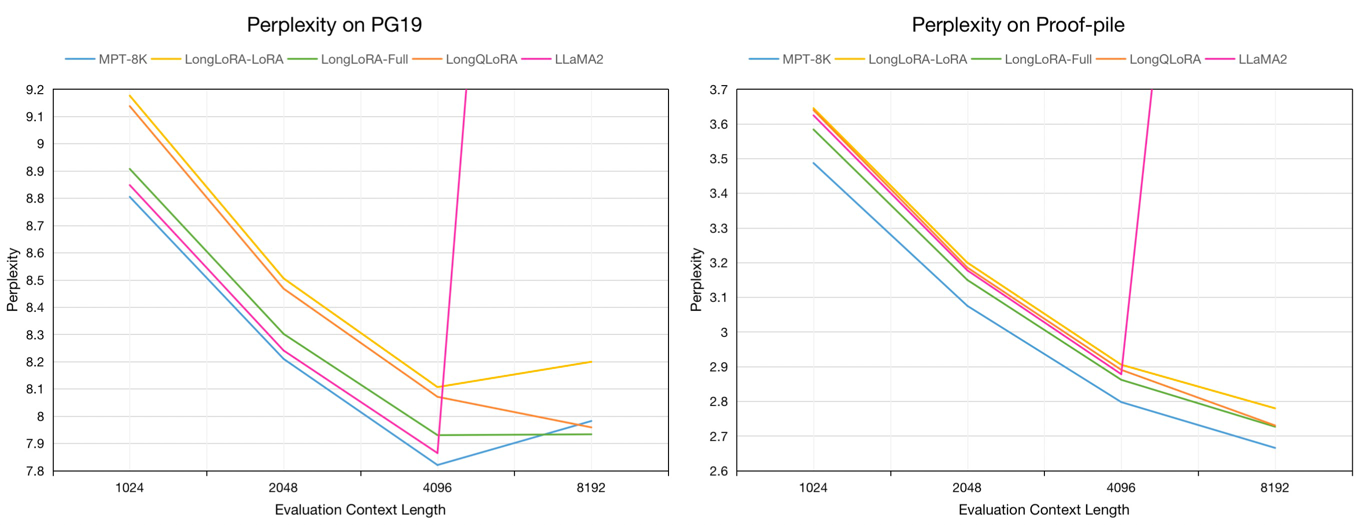
在8192评估上下文长度下,PG19验证集和Proof-pile测试集上的评估困惑度:
| 模型 | PG19 | Proof-pile |
|---|---|---|
| LLaMA2-7B | >1000 | >1000 |
| MPT-7B-8K | 7.98 | 2.67 |
| LongLoRA-LoRA-7B-8K | 8.20 | 2.78 |
| LongLoRA-Full-7B-8K | 7.93 | 2.73 |
| LongQLoRA-7B-8K | 7.96 | 2.73 |
7B模型在PG19验证集和Proof-pile测试集上从1024到8192评估上下文长度的评估困惑度:
数据集
我们从Redpajama数据集中采样了约54k长文本来微调预训练模型,其标记长度范围从4096到32768。
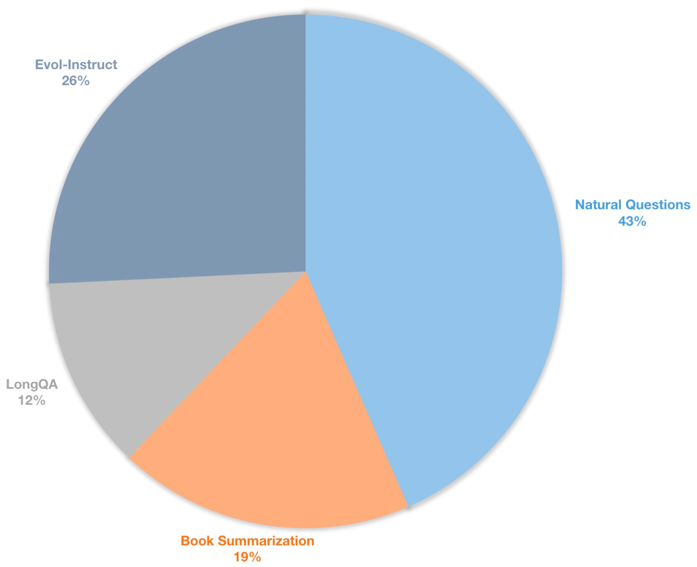
我们还构建了一个长上下文指令数据集,用于有监督微调对话模型。该数据集包含39k条指令数据,主要包括图书摘要、自然问题、LongQA的子集和WizardLM的Evol-Instruct。 为了适应8192的目标长度,每条数据的最大标记数为8192。分布如下所示。
| 数据集 | 描述 |
|---|---|
| 🤗LongQLoRA-Pretrain-Data-54k | 包含54212条数据,用于微调预训练模型 |
| 🤗LongQLoRA-SFT-Data-39k | 包含38821条数据,用于微调对话模型 |
模型
| 模型 | 上下文长度 | 描述 |
|---|---|---|
| 🤗LongQLoRA-Llama2-7b-8k | 8192 | 基于LLaMA2-7B,使用LongQLoRA-Pretrain-Data-54k微调1k步 |
| 🤗LongQLoRA-Vicuna-13b-8k | 8192 | 基于Vicuna-13B-V1.5,使用LongQLoRA-SFT-Data-39k微调1.7k步 |
| 🤗LongQLoRA-Llama2-7b-8k-lora | 8192 | LoRA权重 |
| 🤗LongQLoRA-Vicuna-13b-8k-lora | 8192 | LoRA权重 |
训练
训练配置保存在train_args目录中,一些参数如下:
sft:如果设置为True,则执行sft任务,否则执行预训练任务。model_max_length:目标上下文长度。max_seq_length:训练中的最大序列长度,应小于或等于model_max_length。logging_steps:每n步记录一次训练损失。save_steps:每n步保存一次模型。lora_rank:训练中的LoRA秩。
延长预训练模型LLaMA2-7B的上下文长度:
deepspeed train.py --train_args_file ./train_args/llama2-7b-pretrain.yaml
扩展聊天模型Vicuna-13B的上下文长度:
deepspeed train.py --train_args_file ./train_args/vicuna-13b-sft.yaml
推理
你可以将lora权重合并到基础模型中:
cd script
python merge_lora.py
使用预训练模型进行推理:
cd script/inference
python inference.py
与聊天模型对话:
cd script/inference
python chat.py
评估
下载由LongLoRA使用LLaMA2分词器处理的评估数据集。
评估模型的困惑度。你可以将load_in_4bit设置为True以节省内存:
cd script/evaluate
python evaluate.py \
--batch_size 1 \
--base_model YeungNLP/LongQLoRA-Llama2-7b-8k \
--seq_len 8192 \
--context_size 8192 \
--sliding_window 8192 \
--data_path pg19-validation.bin
使用LoRA权重评估模型的困惑度:
cd script/evaluate
python evaluate.py \
--batch_size 1 \
--base_model YeungNLP/LongQLoRA-Llama2-7b-8k \
--peft_model LongQLoRA-Llama2-7b-8k-lora\
--seq_len 8192 \
--context_size 8192 \
--sliding_window 8192 \
--data_path pg19-validation.bin
示例
以下是由LongQLoRA-Vicuna-13b-8k生成的示例。
长上下文生成的示例,输入上下文长度在4096到8192之间,超过了LLaMA2的原始上下文长度。

短上下文生成的示例,模型保持了短指令跟随的性能。

引用
@misc{yang2023longqlora,
title={LongQLoRA: Efficient and Effective Method to Extend Context Length of Large Language Models},
author={Jianxin Yang},
year={2023},
eprint={2311.04879},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
致谢
- 本工作结合了QLoRA、Position Interpolation和LongLoRA的优点
- Shift Short Attention的代码由LongLoRA实现
- 训练代码基于Firefly修改而来











