
 Github
Github 文档
文档 论文
论文分割并跟踪任何物体 (SAM-Track)
在线演示:  技术报告:
技术报告:
教程: 教程-v1.6(音频),教程-v1.5 (文本), 教程-v1.0 (点击和笔刷)

分割并跟踪任何物体是一个开源项目,专注于使用自动和交互方法对视频中的任何物体进行分割和跟踪。主要使用的算法包括SAM (分割任何物体模型)用于自动/交互式关键帧分割,以及DeAOT (使用Transformer解耦特征进行物体关联) (NeurIPS2022)用于高效的多物体跟踪和传播。SAM-Track pipeline 使SAM能够动态和自动检测并分割新物体,而DeAOT负责跟踪所有已识别的物体。
:loudspeaker:新功能
-
[2024/4/23] 我们添加了音频定位功能,可以在视频的音轨中跟踪发声物体。
-
[2023/5/12] 我们为SAM-Track撰写了一份技术报告。
-
[2023/5/7] 我们添加了
demo_instseg.ipynb,使用Grounding-DINO在视频的关键帧中检测新物体。它可以应用于智慧城市和自动驾驶领域。 -
[2023/4/29] 我们为AOT-L添加了高级参数:
long_term_memory_gap和max_len_long_term。long_term_memory_gap控制AOT模型向其长期记忆中添加新参考帧的频率。在掩码传播过程中,AOT将当前帧与存储在长期记忆中的参考帧进行匹配。- 将间隔值设置为适当的值有助于获得更好的性能。为了避免长视频中的内存爆炸,我们为长期记忆存储设置了
max_len_long_term值,即当记忆帧数量达到max_len_long_term值时,最旧的记忆帧将被丢弃,新帧将被添加。
-
[2023/4/26] 交互式WebUI 1.5版本:我们在交互式WebUI-1.0版本的基础上添加了新功能。
- 我们为SAMTrack添加了一种新的交互形式——文本提示。
- 从现在开始,可以交互式地添加多个需要跟踪的物体。
- 查看交互式WebUI 1.5版本的教程。更多演示将在未来几天发布。
-
[2023/4/26] 图像序列输入:WebUI现在有一个新功能,允许输入图像序列,可用于测试视频分割数据集。从教程开始使用图像序列输入。
-
[2023/4/25] 在线演示: 您可以在Colab中轻松使用SAMTrack进行视觉跟踪任务。
-
[2023/4/23] 交互式WebUI: 我们引入了一个新的WebUI,允许用户通过笔画和点击进行交互式分割。请随意探索并享受教程!
- [2023/4/24] 教程V1.0: 查看我们的新视频教程!
- YouTube链接:交互式修改视频第一帧单个物体掩码的教程、通过点击交互式添加物体的教程、通过笔画交互式添加物体的教程。
- Bilibili视频链接:交互式修改视频第一帧单个物体掩码的教程、通过点击交互式添加物体的教程、通过笔画交互式添加物体的教程。
- 1.0版本是开发者版本,如果遇到任何bug,请随时联系我们:bug:。
- [2023/4/24] 教程V1.0: 查看我们的新视频教程!
-
[2023/4/17] SAMTrack:自动分割并跟踪视频中的任何物体!
:fire:演示

这个视频展示了SAM-Track在各种场景下的分割和跟踪能力,如街景、AR、细胞、动画、航拍等。
:calendar:待办事项
- Colab笔记本:于2023年4月25日完成。
- 1.0版本交互式网页界面:于2023年4月23日完成。
- 1.5版本交互式网页界面:于2023年4月26日完成。
- 2.x版本交互式网页界面
演示1展示了SAM-Track接受对象类别作为提示的能力。用户给出类别文本"熊猫"以实现对属于该类别的所有对象进行实例级分割和跟踪。

演示2展示了SAM-Track接受文本描述作为提示的能力。SAM-Track能够根据输入"最左边的熊猫"来分割和跟踪目标对象。

演示3展示了SAM-Track同时跟踪多个对象的能力。SAM-Track能够自动检测新出现的对象。

演示4展示了SAM-Track接受多种交互方式作为提示的能力。用户分别通过点击和笔触指定了人和滑板。

演示5展示了SAM-Track优化全景分割结果的能力。用户通过单击将电车整体合并。

演示6展示了SAM-Track在跟踪过程中添加新对象的能力。用户通过回退到中间帧来标注另一辆车。

演示7展示了SAM-Track在跟踪过程中优化预测的能力。这个功能在复杂环境下的分割和跟踪中非常有优势。
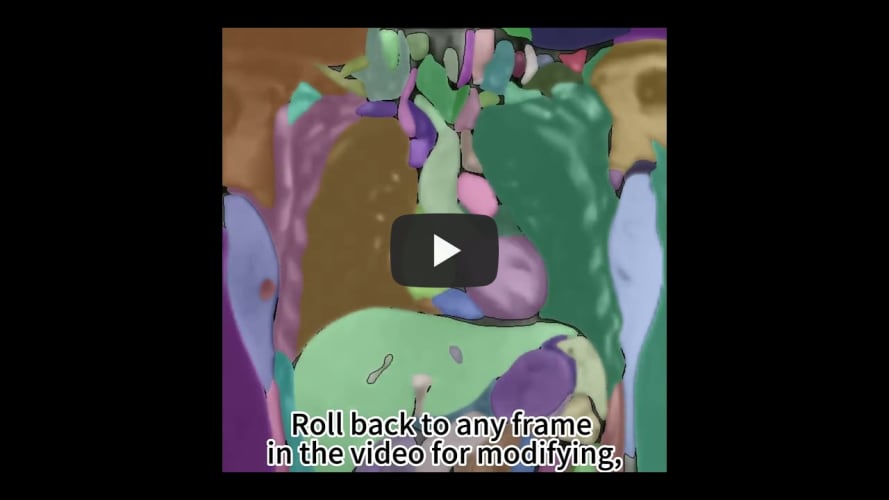
演示8展示了SAM-Track交互式分割和跟踪单个对象的能力。用户指定SAM-Track跟踪一个打街头篮球的男子。

演示9展示了SAM-Track交互式添加指定对象进行跟踪的能力。用户在SAM-Track对场景中所有物体进行分割的基础上,自定义添加要跟踪的对象。

:computer:开始使用
:bookmark_tabs:要求
已克隆Segment-Anything仓库并重命名为sam,同时克隆了aot-benchmark仓库并重命名为aot。
该实现在Python 3.9以及PyTorch 1.10和torchvision 0.11下进行了测试。我们推荐使用等效或更高版本的PyTorch。
使用install.sh安装SAM-Track所需的库
bash script/install.sh
:star:模型准备
将SAM模型下载到ckpt目录,默认模型为SAM-VIT-B(sam_vit_b_01ec64.pth)。
将DeAOT/AOT模型下载到ckpt目录,默认模型为R50-DeAOT-L(R50_DeAOTL_PRE_YTB_DAV.pth)。 将Grounding-Dino模型下载到ckpt目录,默认模型是GroundingDINO-T(groundingdino_swint_ogc)。
将AST模型下载到ast_master/pretrained_models目录,默认模型是audioset_0.4593(audioset_0.4593.pth)。
你可以使用以下命令行下载默认权重。
bash script/download_ckpt.sh
:heart:运行演示
- 将要处理的视频放入./assets目录。
- 然后逐步运行demo.ipynb生成结果。
- 结果将保存为每一帧的掩码和一个用于可视化的gif文件。
SAM-Track、DeAOT和SAM的参数可以在model_args.py中手动修改,以便使用其他模型或控制每个模型的行为。
:muscle:WebUI应用
我们的用户友好的可视化界面允许你轻松获取实验结果。只需使用命令行启动它。
python app.py
用户可以直接在UI上上传视频,并使用SegTracker自动/交互式地跟踪视频中的对象。我们以一个打篮球的男子视频为例。
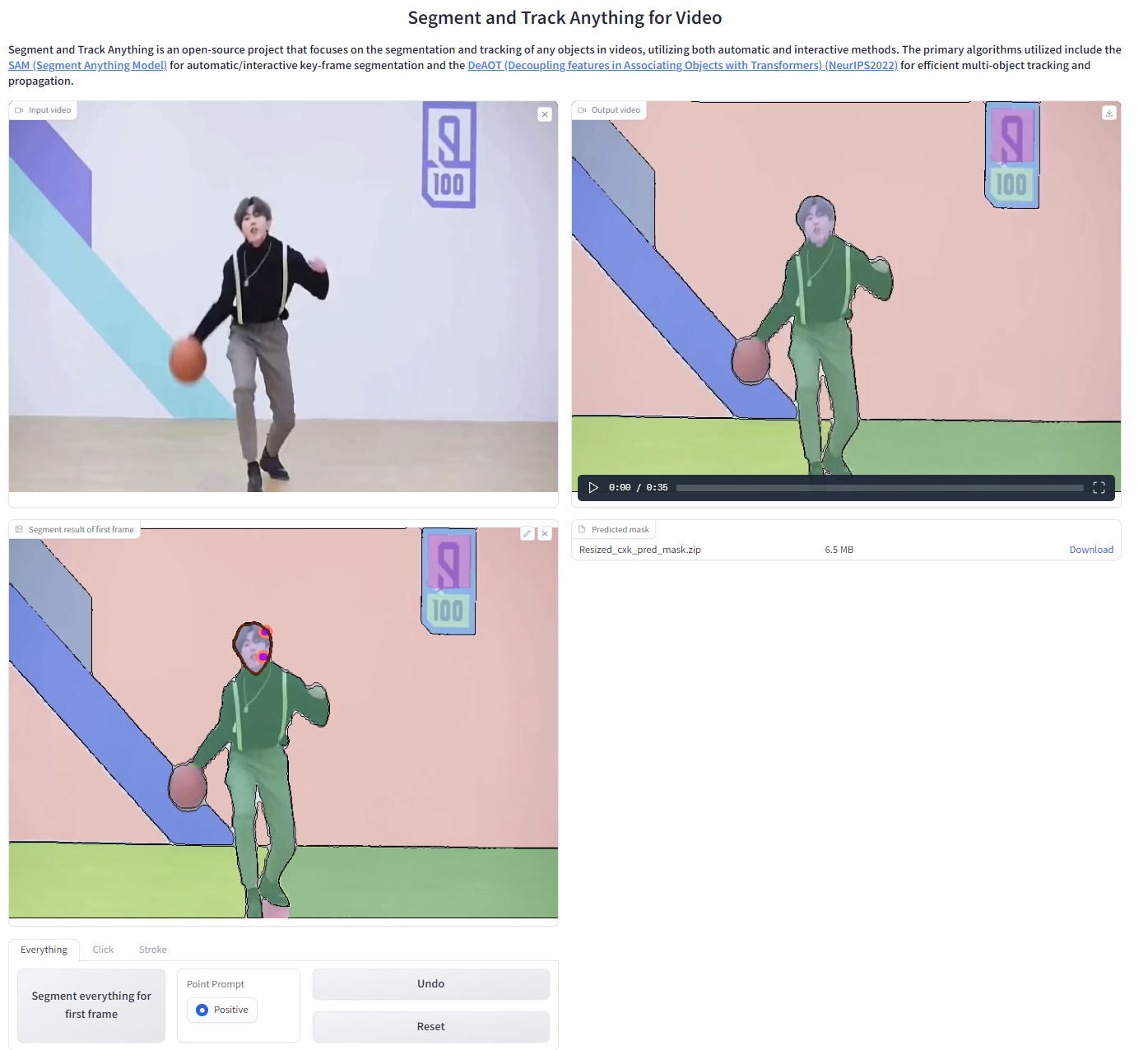
SegTracker参数:
- aot_model:用于选择用于跟踪和传播的DeAOT/AOT版本。
- sam_gap:用于控制SAM在指定帧间隔添加新出现对象的频率。增加此值可减少发现新目标的频率,但会显著提高推理速度。
- points_per_side:用于控制通过在图像上采样网格来生成掩码的每边点数。增加大小可以增强检测小物体的能力,但较大的目标可能会被分割得更细。
- max_obj_num:用于限制SAM-Track可以检测和跟踪的最大对象数。更多的对象需要更多的内存使用,约16GB内存可以处理最多255个对象。
使用方法:详情请参考1.0版WebUI教程。
:school:关于我们
感谢您对本项目的兴趣。该项目由浙江大学计算机科学与技术学院ReLER实验室指导。ReLER由浙江大学求是特聘教授杨易创立。我们的贡献团队包括程杨明、胡济远、徐源友、李柳磊、李晓迪、杨宗鑫、王文冠和杨易。
:full_moon_with_face:致谢
借用代码的许可证可以在licenses.md文件中找到。
- DeAOT/AOT - https://github.com/yoxu515/aot-benchmark
- SAM - https://github.com/facebookresearch/segment-anything
- Gradio(用于构建WebUI) - https://github.com/gradio-app/gradio
- Grounding-Dino - https://github.com/yamy-cheng/GroundingDINO
- AST - https://github.com/YuanGongND/ast
许可证
本项目采用AGPL-3.0许可证。如需通过专有方式将此项目用于商业目的或进行进一步开发,必须获得我们(以及任何借用代码的所有者)的许可。
引用
如果本项目对您的研究有帮助,请考虑在您的出版物中引用相关论文。
@article{cheng2023segment,
title={Segment and Track Anything},
author={Cheng, Yangming and Li, Liulei and Xu, Yuanyou and Li, Xiaodi and Yang, Zongxin and Wang, Wenguan and Yang, Yi},
journal={arXiv preprint arXiv:2305.06558},
year={2023}
}
@article{kirillov2023segment,
title={Segment anything},
author={Kirillov, Alexander and Mintun, Eric and Ravi, Nikhila and Mao, Hanzi and Rolland, Chloe and Gustafson, Laura and Xiao, Tete and Whitehead, Spencer and Berg, Alexander C and Lo, Wan-Yen and others},
journal={arXiv preprint arXiv:2304.02643},
year={2023}
}
@inproceedings{yang2022deaot,
title={Decoupling Features in Hierarchical Propagation for Video Object Segmentation},
author={Yang, Zongxin and Yang, Yi},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2022}
}
@inproceedings{yang2021aot,
title={Associating Objects with Transformers for Video Object Segmentation},
author={Yang, Zongxin and Wei, Yunchao and Yang, Yi},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2021}
}
@article{liu2023grounding,
title={Grounding dino: Marrying dino with grounded pre-training for open-set object detection},
author={Liu, Shilong and Zeng, Zhaoyang and Ren, Tianhe and Li, Feng and Zhang, Hao and Yang, Jie and Li, Chunyuan and Yang, Jianwei and Su, Hang and Zhu, Jun and others},
journal={arXiv preprint arXiv:2303.05499},
year={2023}
}
@inproceedings{gong21b_interspeech,
author={Yuan Gong and Yu-An Chung and James Glass},
title={AST: Audio Spectrogram Transformer},
booktitle={Proc. Interspeech 2021},
pages={571--575},
doi={10.21437/Interspeech.2021-698}
year={2021}
}











