
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文SAT
这是"One Model to Rule them All: Towards Universal Segmentation for Medical Images with Text Prompts"(一个模型统治全局:基于文本提示的通用医学图像分割)的官方代码库 🚀
这是一个基于前所未有的数据集(72个公开3D医学分割数据集)构建的知识增强型通用分割模型,可以通过文本提示(解剖学术语)分割来自3种不同模态(MR、CT、PET)和8个人体区域的497个类别。
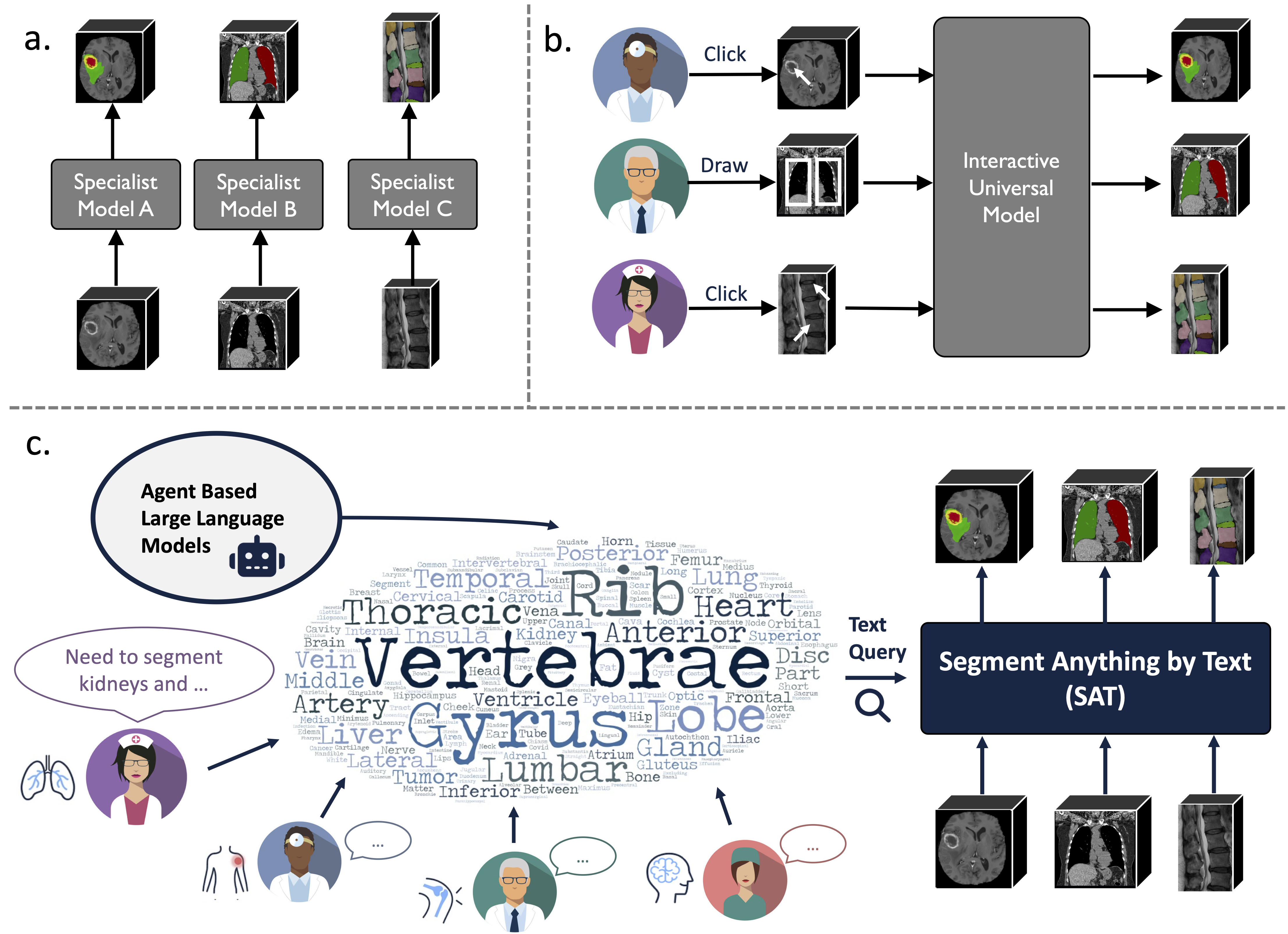
它比训练和部署一系列专家模型更强大、更高效。
最新消息:
-
2024.08 📢 基于SAT和大型语言模型,我们构建了一个全面、大规模且区域引导的3D胸部CT解释数据集。它包含196个类别的器官级分割,以及多粒度报告,每个句子都与相应的分割结果相关联。在huggingface上查看。
-
2024.06 📢 我们发布了构建SAT-DS的代码,这是一个包含72个公开分割数据集的集合,包含超过22K 3D图像、302K分割掩模和来自3种不同模态(MRI、CT、PET)和8个人体区域的497个类别,我们在此基础上构建了SAT。我们还提供了42/72个数据集的快捷下载链接,这些数据集经过我们预处理和打包,方便您直接使用,下载解压后即可使用。详情请查看此仓库。
-
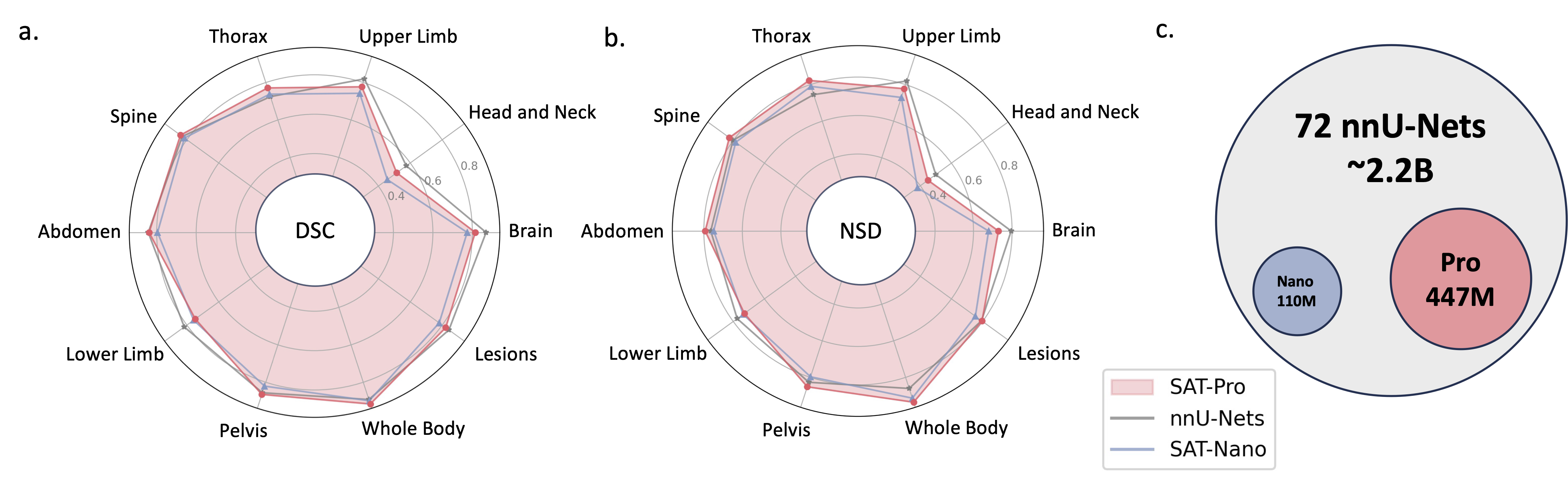
2024.05 📢 我们训练了一个更大模型规模的SAT新版本(SAT-Pro)并使用了更多数据集(72个),现在支持497个类别! 我们还更新了SAT-Nano,并发布了一些SAT-Nano的变体,基于不同的视觉骨干网络(U-Mamba和SwinUNETR)和文本编码器(MedCPT和BERT-Base)。 有关此更新的更多详细信息,请参阅我们的新论文。
⚠️ 注意:在此更新中,我们进行了大量更改,之前版本的检查点/代码与新发布的代码/检查点不兼容。但是,数据格式与之前保持一致,因此无需重新准备您的数据。
要求
U-Net的实现依赖于dynamic-network-architectures的自定义版本,安装方法:
cd model
pip install -e dynamic-network-architectures-main
其他一些关键要求:
torch>=1.10.0
numpy==1.21.5
monai==1.1.0
transformers==4.21.3
nibabel==4.0.2
einops==0.6.1
positional_encodings==6.0.1
如果您想要使用SAT-Nano的U-Mamba变体,还需要安装mamba_ssm
推理指南(命令行):
-
步骤1. 按照
requirements.txt构建环境。 -
S2. 从huggingface下载SAT和Text Encoder的检查点。
-
S3. 准备jsonl格式的数据文件。查看
data/inference_demo/demo.jsonl中的示例。-
每个待分割样本需要包含
image(图像路径)、labe(分割目标名称)、dataset(样本所属数据集)和modality(ct、mri或pet)。SAT支持的模态和类别可在论文的表12中找到。 -
orientation_code(方向)默认为RAS,适用于大多数轴向平面的图像。对于矢状面图像(如脊柱检查),将其设置为ASR。 输入图像的形状应为H,W,D。我们的数据处理代码会对输入图像进行方向、强度、间距等方面的标准化。demo\processed_data中有两个成功处理的图像示例,请确保正确进行标准化以保证SAT的性能。
-
-
S4. 开始使用SAT-Pro进行推理 🕶:
torchrun \ --nproc_per_node=1 \ --master_port 1234 \ inference.py \ --rcd_dir 'demo/inference_demo/results' \ --datasets_jsonl 'demo/inference_demo/demo.jsonl' \ --vision_backbone 'UNET-L' \ --checkpoint 'SAT-Pro检查点路径' \ --text_encoder 'ours' \ --text_encoder_checkpoint 'Text encoder检查点路径' \ --max_queries 256 \ --batchsize_3d 2⚠️ 注意:
--batchsize_3d是输入图像块的批量大小,需要根据GPU内存进行调整(参考下表); 建议将--max_queries设置为大于推理数据集中的类别数,除非GPU内存非常有限;模型 batchsize_3d GPU内存 SAT-Pro 1 ~ 34GB SAT-Pro 2 ~ 62GB SAT-Nano 1 ~ 24GB SAT-Nano 2 ~ 36GB -
S5. 检查
--rcd_dir获取输出结果。结果按数据集组织。对于每个案例,您将找到输入图像、聚合后的分割结果以及包含每个类别分割的文件夹。所有输出都以nifti格式存储。您可以使用ITK-SNAP进行可视化。 -
如果您想使用在72个数据集上训练的SAT-Nano,只需将
--vision_backbone改为'UNET',并相应地更改--checkpoint和--text_encoder_checkpoint。 -
对于其他SAT-Nano变体(在49个数据集上训练):
UNET-Ours: 设置
--vision_backbone 'UNET'和--text_encoder 'ours';UNET-CPT: 设置
--vision_backbone 'UNET'和--text_encoder 'medcpt';UNET-BB: 设置
--vision_backbone 'UNET'和--text_encoder 'basebert';UMamba-CPT: 设置
--vision_backbone 'UMamba'和--text_encoder 'medcpt';SwinUNETR-CPT: 设置
--vision_backbone 'SwinUNETR'和--text_encoder 'medcpt';
训练指南:
开始训练前的一些准备工作:
- 您需要按照这个仓库构建训练数据,需要一个包含所有训练样本的jsonl文件。
- 您需要从https://huggingface.co/zzh99/SAT 获取文本编码器检查点以生成提示。
我们建议训练SAT-Nano使用8个或更多A100-80G,训练SAT-Pro使用16个或更多A100-80G。请使用
sh/中的slurm脚本启动训练过程。以SAT-Pro为例:
sbatch sh/train_sat_pro.sh
待办事项
- 网站上的推理演示。
- 发布用于构建SAT-DS的数据预处理代码。
- 发布训练指南。
引用
如果您在研究或项目中使用此代码,请引用:
@arxiv{zhao2023model,
title={基于文本提示的通用医学图像分割模型},
author={赵子恒 和 张瑶 和 吴超逸 和 张晓曼 和 张亚 和 王彦峰 和 谢伟迪},
year={2023},
journal={arXiv预印本 arXiv:2312.17183},
}











