
 访问官网
访问官网 Github
Github
MPP-Qwen-Next: 基于 QwenLM 的多模态流水线并行
https://github.com/Coobiw/MiniGPT4Qwen/assets/48615375/963416dd-fd97-4680-b7ac-fa4a14beaaae
https://github.com/Coobiw/MiniGPT4Qwen/assets/48615375/0e7c33f6-33d3-478a-ab0e-ecc116aeec78
新闻
- [2024/6] 🔥 开源 MPP-Qwen-Next 的 sft 权重 (15GB) modelscope 链接 百度网盘链接
- [2024/6] 🔥 MPP-Qwen-Next: 加入 llava 的多轮对话 sft 数据以及 videochatgpt 的 100k sft 数据,支持图像多轮对话,视频对话,并涌现出多图对话能力 知乎博客
- [2024/5] 🔥 代码支持多轮对话 sft、视频 sft、多图 sft
- [2024/4] 🔥 支持多卡推理,修正 chat template 以获得更好的对话效果 知乎博客
- [2024/3] 🔥 MPPQwen-14B: 将 MiniGPT4Qwen-14B 扩展为 MPP-Qwen14B(多模态流水线并行)。数据和训练范式参照 LLaVA(pretrain + sft),指令微调时打开 LLM。全部训练过程在 6 张 RTX4090 上完成 README & 教程; 知乎博客
- [2024/2] 🔥 MiniGPT4Qwen-14B: 将 MiniGPT4Qwen 扩展到 14B。使用 DeepSpeed Pipeline Parallel 让全过程仅使用 2 张 4090 显卡 README & 教程; 知乎博客
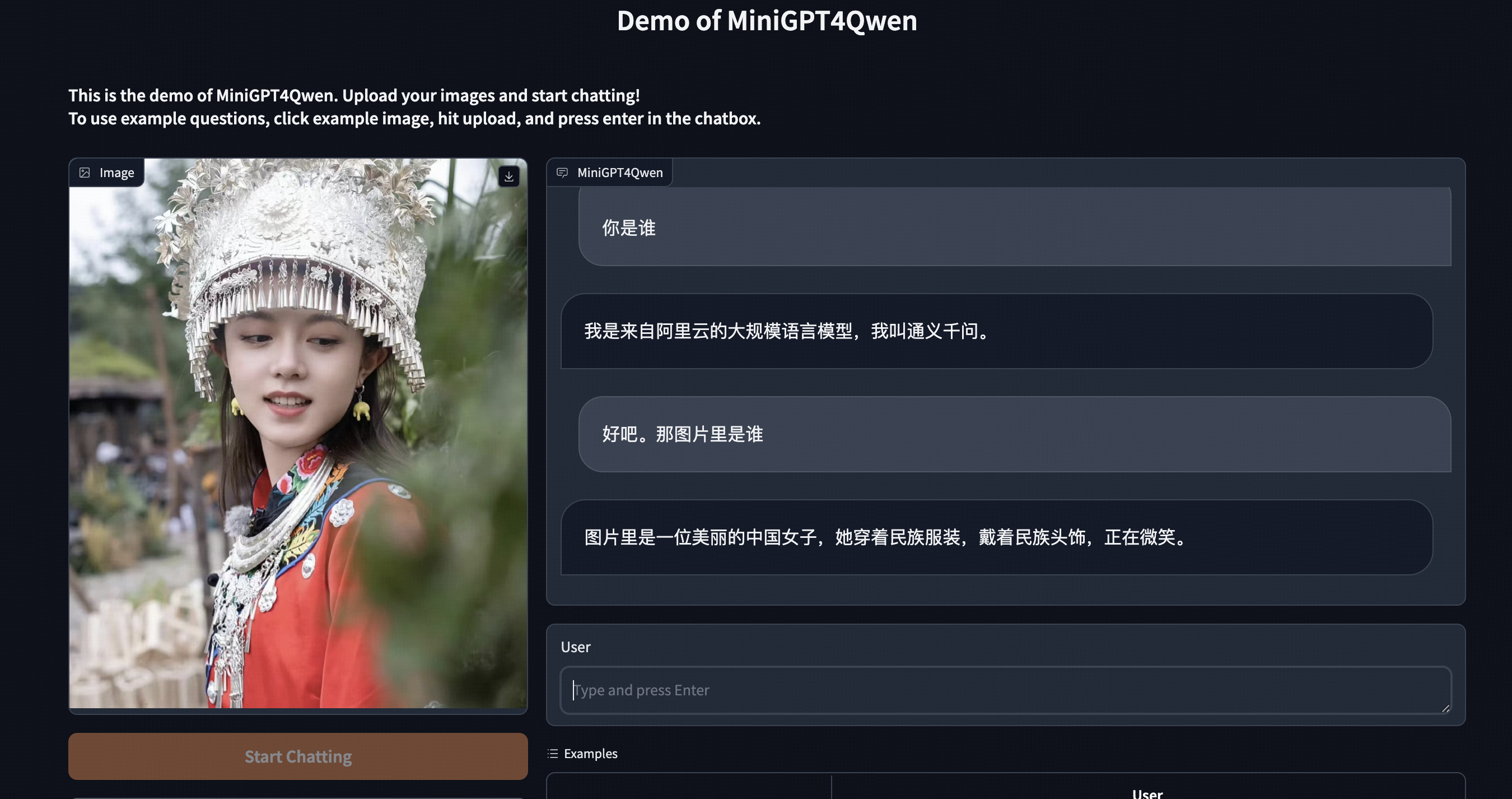
- [2023/10] 🔥 MiniGPT4Qwen: 采用 18.8k 的高质量双语指令微调数据,得到单阶段训练的个人版双语 MLLM README & 教程; 知乎博客
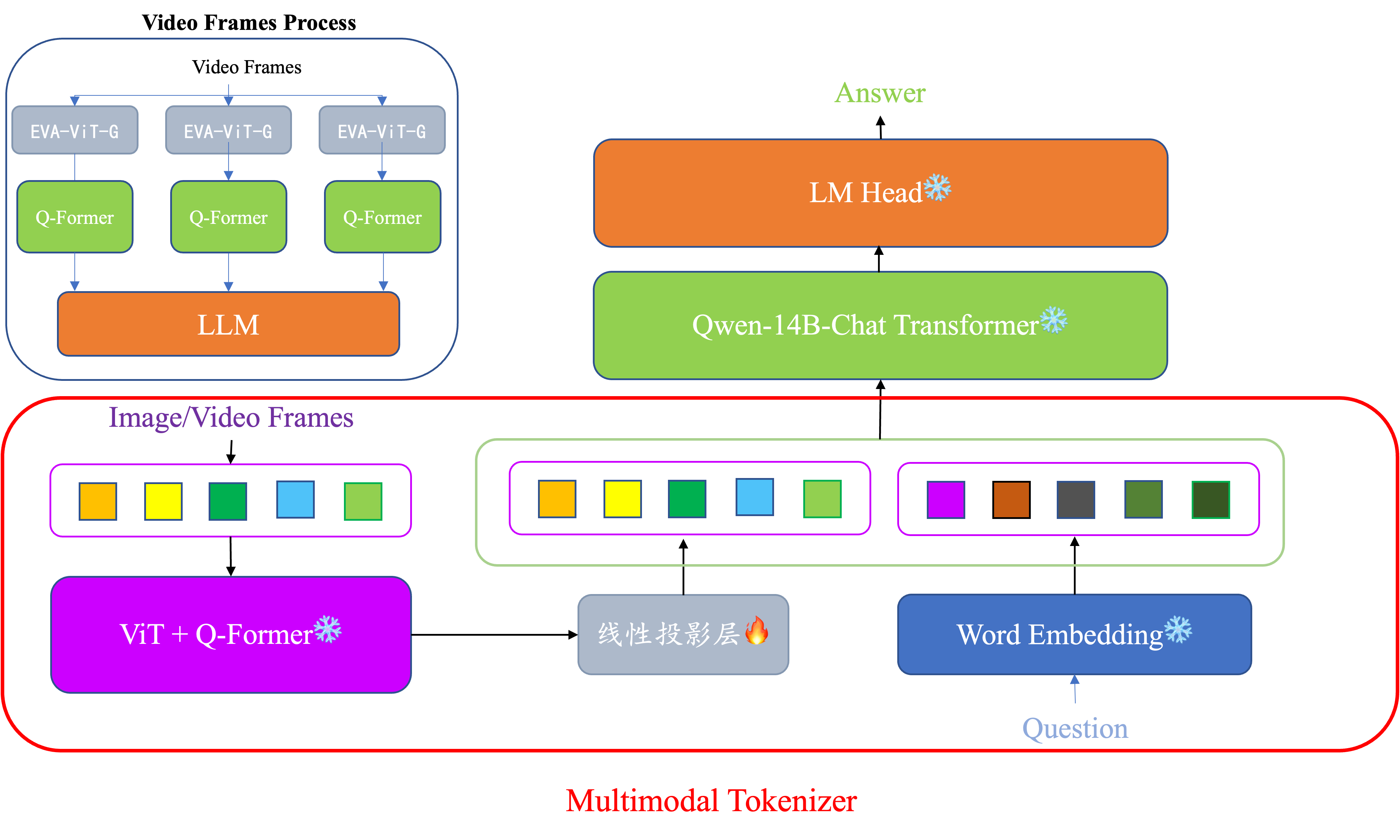
框架
特性
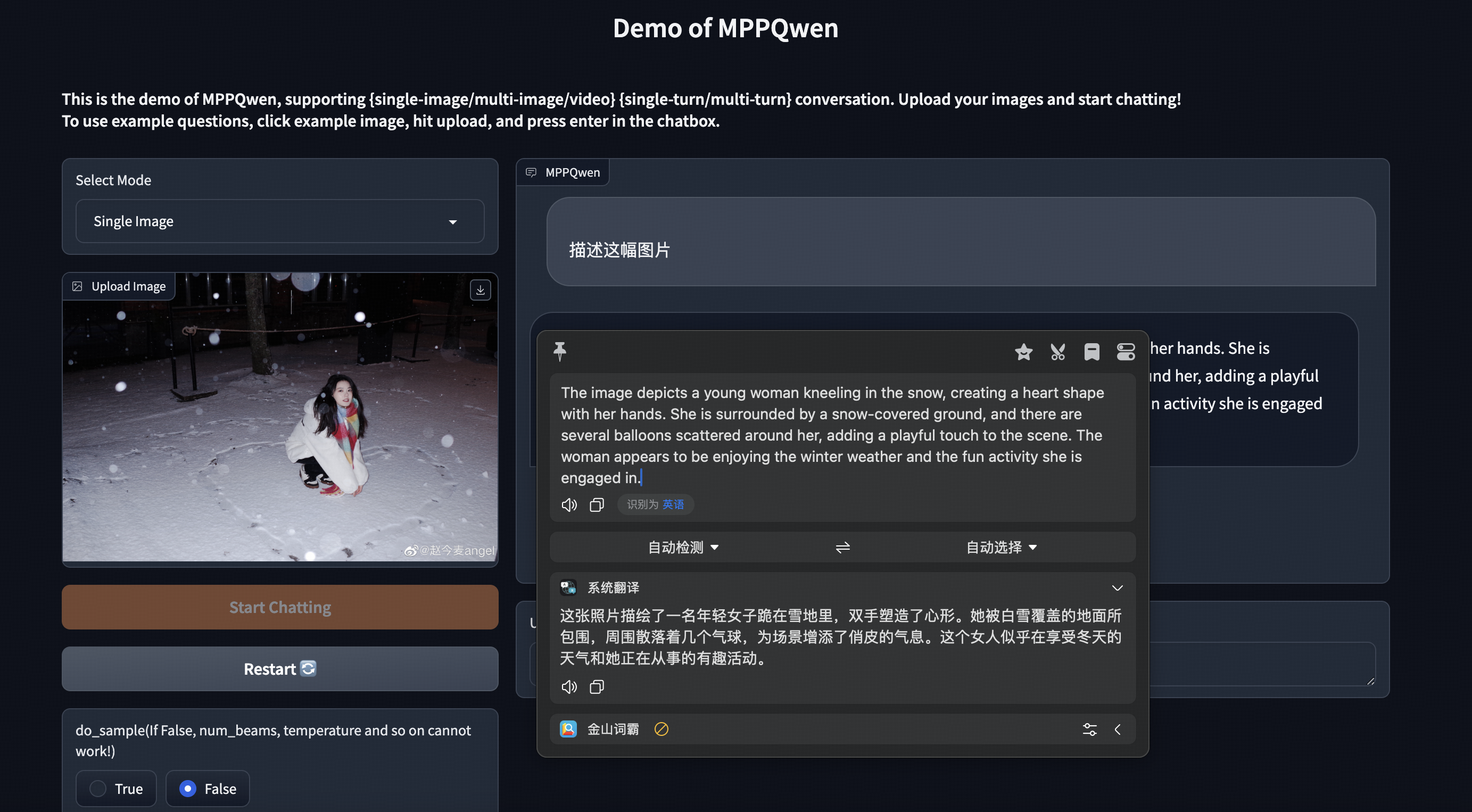
图像-单轮问答
图像-多轮对话
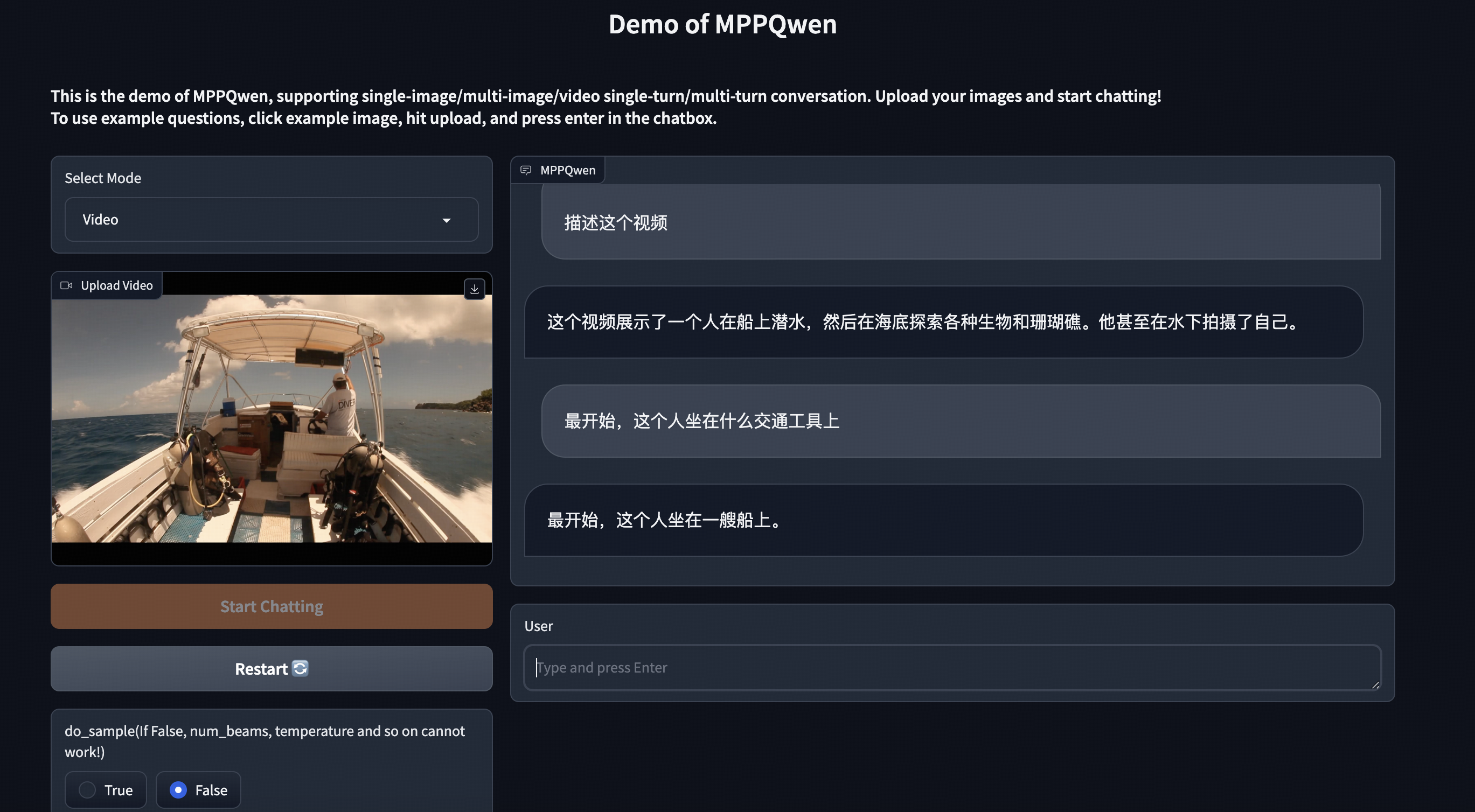
视频-对话
多图-对话(未经过多图 sft,视频 sft 后涌现该能力)
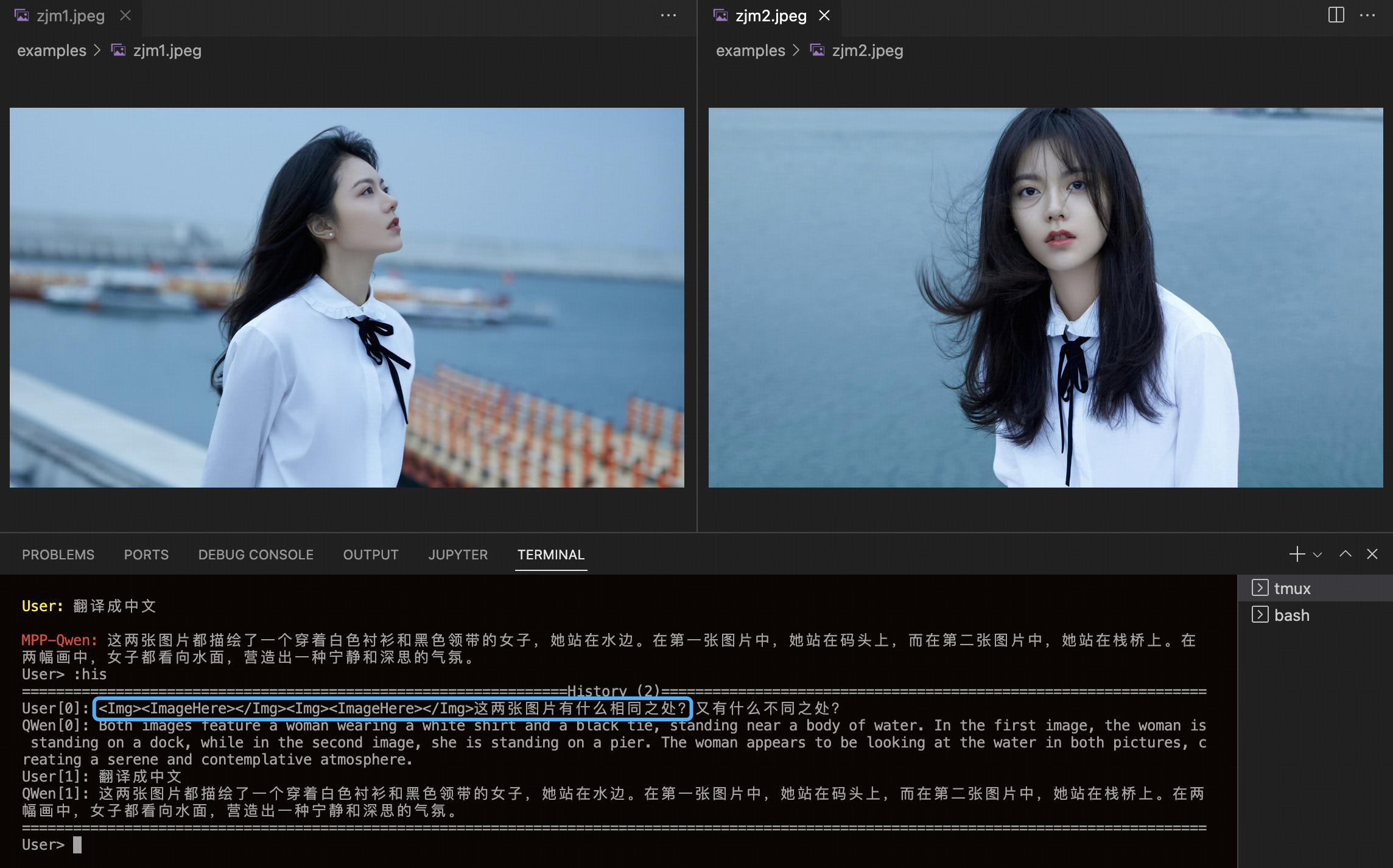
无视频 sft 的 MPP-14B 模型多图对话(看似回答,实际啥都没说):
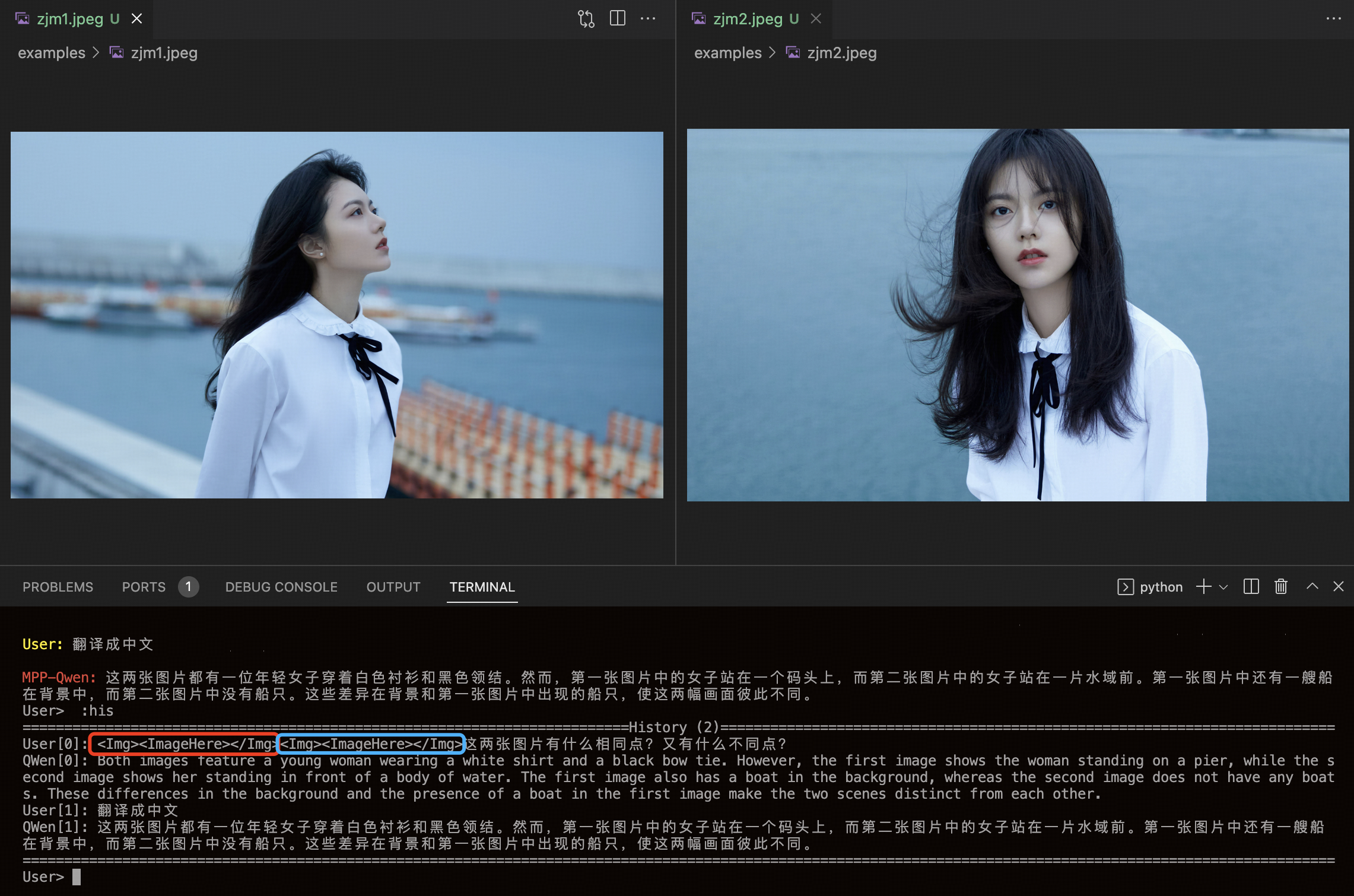
视频 sft 后的 MPPQwen-8B 模型(具备比较不同图像的能力):
待办事项列表
- 加入 huggingface-transformers 实现,并 push 到 huggingface
- 开源 sft 权重(modelscope & 百度网盘)
- 支持单图推理、多图推理、视频推理
- 支持 model parallelism 的推理(使用了 transformers 的
device_map="auto") - 开源 pretrain 权重
- 开源处理好的 pretrain 和 sft 的数据集 json 文件
- 支持多轮对话、多图 sft、视频 sft
- 支持 deepspeed 的流水线并行
安装
conda create -n minigpt4qwen python=3.8 && conda activate minigpt4qwen
pip install -e .
权重&数据准备
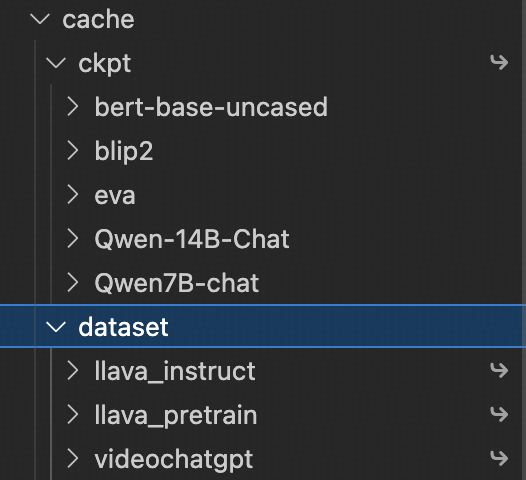
请放在 cache 目录中,结构如下
模型权重请参照:WEIGHT.md
训练数据请参照:DATA.md
推理
请先按照 WEIGHT.md 配置好权重
并在以下链接中二选一,下载 sft 后的模型权重(15GB):
运行命令行 demo
单 GPU 推理
python cli_demo.py --model-type qwen7b_chat -c lavis/output/pp_7b_video/sft_video/global_step2005/unfreeze_llm_model.pth
多 GPU(llm 使用 device_map="auto" 加载,可以多卡加载 LLM 部分模型:
python cli_demo.py --model-type qwen7b_chat -c lavis/output/pp_7b_video/sft_video/global_step2005/unfreeze_llm_model.pth --llm_device_map "auto"
CPU(速度慢):
python cli_demo.py--model-type qwen7b_chat -c lavis/output/pp_7b_video/sft_video/global_step2005/unfreeze_llm_model.pth --cpu-only # 如果显存足够(>=20GB)可以不要--cpu-only
运行后需要输入图片路径,可以输入多张图片,用:f结束图片路径输入后进入对话
常见操作:
:help 查看help
:clear 清空当前命令行
:clh 清空对话历史(但图像输入不会更改)
:his 查看对话历史
:img 查看输入的图像路径
运行gradio webui demo
单GPU推理
python webui_demo.py --model-type qwen7b_chat -c lavis/output/pp_7b_video/sft_video/global_step2005/unfreeze_llm_model.pth
多GPU推理(llm使用device_map="auto"加载)
python webui_demo.py --model-type qwen7b_chat -c lavis/output/pp_7b_video/sft_video/global_step2005/unfreeze_llm_model.pth --llm_device_map "auto"
CPU推理:
python webui_demo.py --model-type qwen7b_chat -c lavis/output/pp_7b_video/sft_video/global_step2005/unfreeze_llm_model.pth --cpu-only # 如果显存足够(>=20GB)可以不要--cpu-only
流水线并行训练(PP+DP)
下面为8卡3090运行指令:
预训练
nproc_per_node: 8 dp: 4 pp: 2 nproc_per_node = pp * dp
python -m torch.distributed.run --nproc_per_node=8 train_pipeline.py --cfg-path lavis/projects/pp_qwen7b_video/pretrain.yaml --num-stages 2
SFT
nproc_per_node: 8 dp: 1 pp: 8 nproc_per_node = pp * dp
python -m torch.distributed.run --nproc_per_node=8 train_pipeline.py --cfg-path lavis/projects/pp_qwen7b_video/sft.yaml --num-stages 8
pipeline并行的权重转换为pth文件
预训练阶段:
(仅转换linear projection层)
python pipe_proj2pth.py --ckpt-dir lavis/output/pp_7b_video/pretrain/global_step2181
转换后,模型文件会存储在ckpt_dir底下,名为model.pth
SFT阶段
(需要转换projection层和所有LLM的参数)
python pipemodel2pth.py --ckpt-dir lavis/output/pp_7b_video/sft_video/global_step2005
转换后,模型文件会存储在ckpt_dir底下,名为unfreeze_llm_model.pth
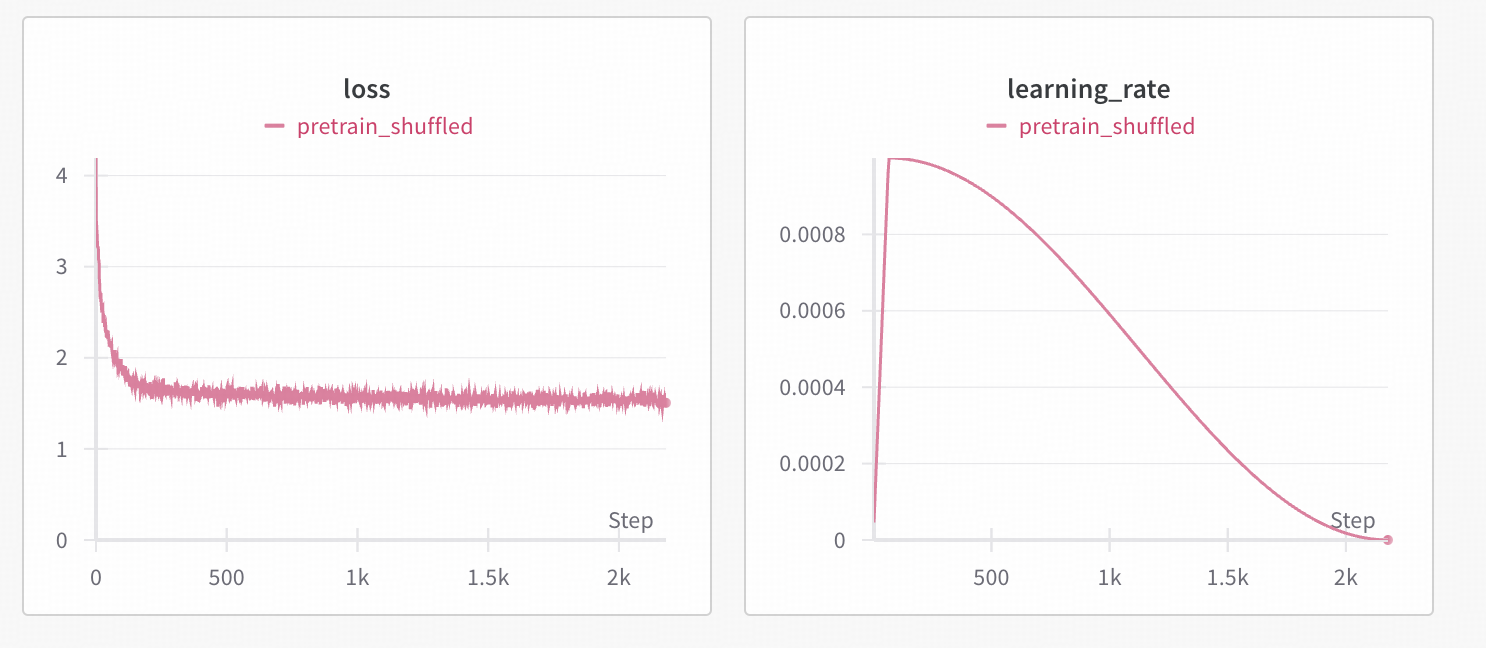
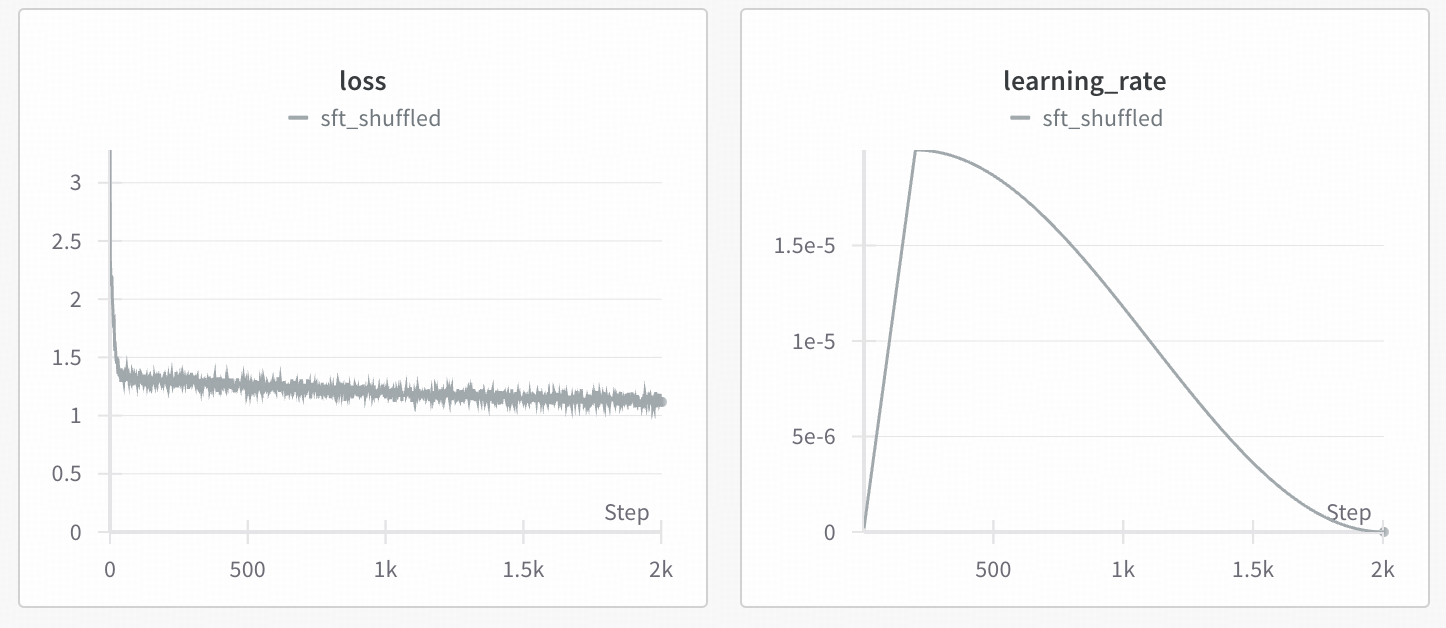
二阶段训练loss曲线参考
pretrain:
SFT:
自定义数据格式(如果你想继续训练)
处理函数可以参考:https://github.com/Coobiw/MiniGPT4Qwen/releases/download/MPP-Qwen-Next_ckpt-and-data/ckpt-and-data.zip中,llava_instuct和videochatgpt目录里的analysis.py脚本
图像指令微调数据格式
单轮(instruction和output为str):
[
{
"image": "000000215677.jpg",
"instruction": "<Img><ImageHere></Img> {question}",
"output": "{answer}"
}
]
多轮(instruction和output为等长的list):
{
"image": "000000479443.jpg",
"instruction": [
"<Img><ImageHere></Img> {question1}",
"{question2}",
"..."
],
"output": [
"{answer1}",
"{answer2}",
"..."
]
}
视频指令微调数据格式
[
{
"video": "v_k_ZXmr8pmrs.mkv",
"instruction": "<Img><ImageHere></Img> {question}",
"output": "{answer}"
}
]
致谢
- Lavis 本仓库是基于lavis进行构建的,且使用了其中BLIP2的ViT和Q-former
- QwenLM 本仓库的语言模型采用Qwen7B-Chat
- DeepSpeed 👍
- DeepSpeedExamples 👍👍
- LLaVA 参照其训练范式,使用了其预训练和指令微调数据
- VideoChatGPT 使用其视频SFT的100k数据
- Video-LLaVA 提供videochatgpt视频数据的百度网盘下载链接
许可
- 本仓库的许多代码是基于Lavis的,其采用BSD 3-Clause License.
- 本仓库采用Qwen-7B-Chat,支持商用和科研、开发用途,其License为LICENSE
Star历史











