
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文
![]()
Hunyuan-DiT : A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding







This repo contains PyTorch model definitions, pre-trained weights and inference/sampling code for our paper exploring Hunyuan-DiT. You can find more visualizations on our project page.
DialogGen: Multi-modal Interactive Dialogue System for Multi-turn Text-to-Image Generation
🔥🔥🔥 News!!
- Jul 15, 2024: 🚀 HunYuanDiT and Shakker.Ai have jointly launched a fine-tuning event based on the HunYuanDiT 1.2 model. By publishing a lora or fine-tuned model based on HunYuanDiT, you can earn up to $230 bonus from Shakker.Ai. See Shakker.Ai for more details.
- Jul 15, 2024: :tada: Update ComfyUI to support standardized workflows and compatibility with weights from t2i module and Lora training for versions 1.1/1.2, as well as those trained by Kohya or the official script. See ComfyUI for details.
- Jul 15, 2024: :zap: We offer Docker environments for CUDA 11/12, allowing you to bypass complex installations and play with a single click! See dockers for details.
- Jul 08, 2024: :tada: HYDiT-v1.2 version is released. Please check HunyuanDiT-v1.2 and Distillation-v1.2 for more details.
- Jul 03, 2024: :tada: Kohya-hydit version now available for v1.1 and v1.2 models, with GUI for inference. Official Kohya version is under review. See kohya for details.
- Jun 27, 2024: :art: Hunyuan-Captioner is released, providing fine-grained caption for training data. See mllm for details.
- Jun 27, 2024: :tada: Support LoRa and ControlNet in diffusers. See diffusers for details.
- Jun 27, 2024: :tada: 6GB GPU VRAM Inference scripts are released. See lite for details.
- Jun 19, 2024: :tada: ControlNet is released, supporting canny, pose and depth control. See training/inference codes for details.
- Jun 13, 2024: :zap: HYDiT-v1.1 version is released, which mitigates the issue of image oversaturation and alleviates the watermark issue. Please check HunyuanDiT-v1.1 and Distillation-v1.1 for more details.
- Jun 13, 2024: :truck: The training code is released, offering full-parameter training and LoRA training.
- Jun 06, 2024: :tada: Hunyuan-DiT is now available in ComfyUI. Please check ComfyUI for more details.
- Jun 06, 2024: 🚀 We introduce Distillation version for Hunyuan-DiT acceleration, which achieves 50% acceleration on NVIDIA GPUs. Please check Distillation for more details.
- Jun 05, 2024: 🤗 Hunyuan-DiT is now available in 🤗 Diffusers! Please check the example below.
- Jun 04, 2024: :globe_with_meridians: Support Tencent Cloud links to download the pretrained models! Please check the links below.
- May 22, 2024: 🚀 We introduce TensorRT version for Hunyuan-DiT acceleration, which achieves 47% acceleration on NVIDIA GPUs. Please check TensorRT-libs for instructions.
- May 22, 2024: 💬 We support demo running multi-turn text2image generation now. Please check the script below.
🤖 Try it on the web
Welcome to our web-based Tencent Hunyuan Bot, where you can explore our innovative products! Just input the suggested prompts below or any other imaginative prompts containing drawing-related keywords to activate the Hunyuan text-to-image generation feature. Unleash your creativity and create any picture you desire, all for free!
You can use simple prompts similar to natural language text
画一只穿着西装的猪
draw a pig in a suit
生成一幅画,赛博朋克风,跑车
generate a painting, cyberpunk style, sports car
or multi-turn language interactions to create the picture.
画一个木制的鸟
draw a wooden bird
变成玻璃的
turn into glass
📑 Open-source Plan
- Hunyuan-DiT (Text-to-Image Model)
- Inference
- Checkpoints
- Distillation Version
- TensorRT Version
- Training
- Lora
- Controlnet (Pose, Canny, Depth)
- 6GB GPU VRAM Inference
- IP-adapter
- Hunyuan-DiT-S checkpoints (0.7B model)
- Mllm
- Hunyuan-Captioner (Re-caption the raw image-text pairs)
- Inference
- Hunyuan-DialogGen (Prompt Enhancement Model)
- Inference
- Hunyuan-Captioner (Re-caption the raw image-text pairs)
- Web Demo (Gradio)
- Multi-turn T2I Demo (Gradio)
- Cli Demo
- ComfyUI
- Diffusers
- Kohya
- WebUI
Contents
- Hunyuan-DiT : A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding
- 🔥🔥🔥 News!!
- 🤖 Try it on the web
- 📑 Open-source Plan
- Contents
- Abstract
- 🎉 Hunyuan-DiT Key Features
- 📈 Comparisons
- 🎥 Visualization
- 📜 Requirements
- 🛠️ Dependencies and Installation
- 🧱 Download Pretrained Models - 1. Using HF-Mirror - 2. Resume Download
- :truck: Training
- 🔑 Inference
- :building_construction: Adapter
- :art: Hunyuan-Captioner
- 🚀 Acceleration (for Linux)
- 🔗 BibTeX
- Start History
Abstract
We present Hunyuan-DiT, a text-to-image diffusion transformer with fine-grained understanding of both English and Chinese. To construct Hunyuan-DiT, we carefully designed the transformer structure, text encoder, and positional encoding. We also build from scratch a whole data pipeline to update and evaluate data for iterative model optimization. For fine-grained language understanding, we train a Multimodal Large Language Model to refine the captions of the images. Finally, Hunyuan-DiT can perform multi-round multi-modal dialogue with users, generating and refining images according to the context. Through our carefully designed holistic human evaluation protocol with more than 50 professional human evaluators, Hunyuan-DiT sets a new state-of-the-art in Chinese-to-image generation compared with other open-source models.
🎉 Hunyuan-DiT Key Features
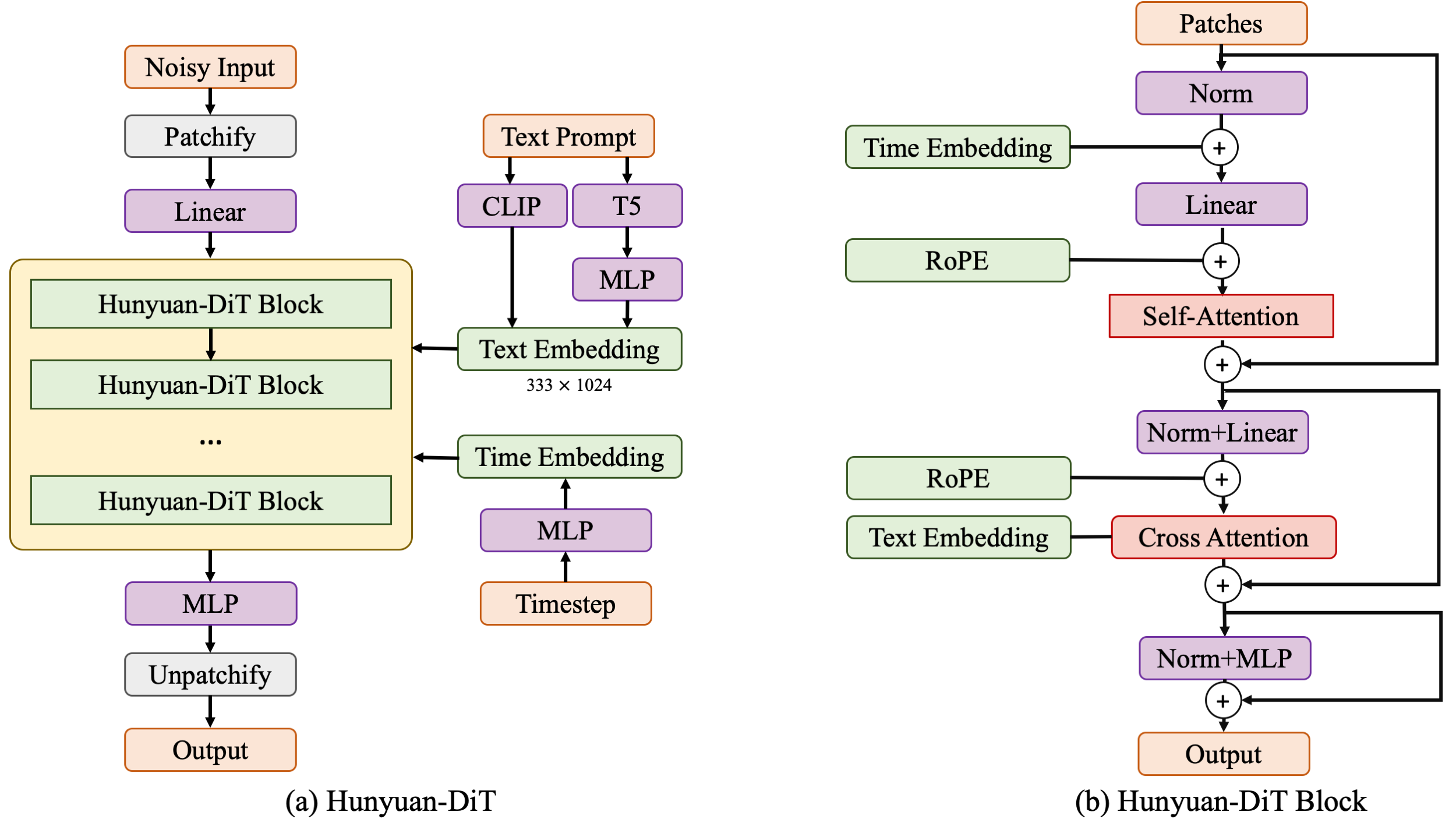
Chinese-English Bilingual DiT Architecture
Hunyuan-DiT is a diffusion model in the latent space, as depicted in figure below. Following the Latent Diffusion Model, we use a pre-trained Variational Autoencoder (VAE) to compress the images into low-dimensional latent spaces and train a diffusion model to learn the data distribution with diffusion models. Our diffusion model is parameterized with a transformer. To encode the text prompts, we leverage a combination of pre-trained bilingual (English and Chinese) CLIP and multilingual T5 encoder.
Multi-turn Text2Image Generation
Understanding natural language instructions and performing multi-turn interaction with users are important for a text-to-image system. It can help build a dynamic and iterative creation process that bring the user’s idea into reality step by step. In this section, we will detail how we empower Hunyuan-DiT with the ability to perform multi-round conversations and image generation. We train MLLM to understand the multi-round user dialogue and output the new text prompt for image generation.

📈 Comparisons
In order to comprehensively compare the generation capabilities of HunyuanDiT and other models, we constructed a 4-dimensional test set, including Text-Image Consistency, Excluding AI Artifacts, Subject Clarity, Aesthetic. More than 50 professional evaluators performs the evaluation.
| Model | Open Source | Text-Image Consistency (%) | Excluding AI Artifacts (%) | Subject Clarity (%) | Aesthetics (%) | Overall (%) |
|---|---|---|---|---|---|---|
| SDXL | ✔ | 64.3 | 60.6 | 91.1 | 76.3 | 42.7 |
| PixArt-α | ✔ | 68.3 | 60.9 | 93.2 | 77.5 | 45.5 |
| Playground 2.5 | ✔ | 71.9 | 70.8 | 94.9 | 83.3 | 54.3 |
| SD 3 | ✘ | 77.1 | 69.3 | 94.6 | 82.5 | 56.7 |
| MidJourney v6 | ✘ | 73.5 | 80.2 | 93.5 | 87.2 | 63.3 |
| DALL-E 3 | ✘ | 83.9 | 80.3 | 96.5 | 89.4 | 71.0 |
| Hunyuan-DiT | ✔ | 74.2 | 74.3 | 95.4 | 86.6 | 59.0 |
🎥 Visualization
- Chinese Elements

- Long Text Input

- **Multi-turn Text2Image











