
 Github
Github 文档
文档 论文
论文RCG PyTorch 实现
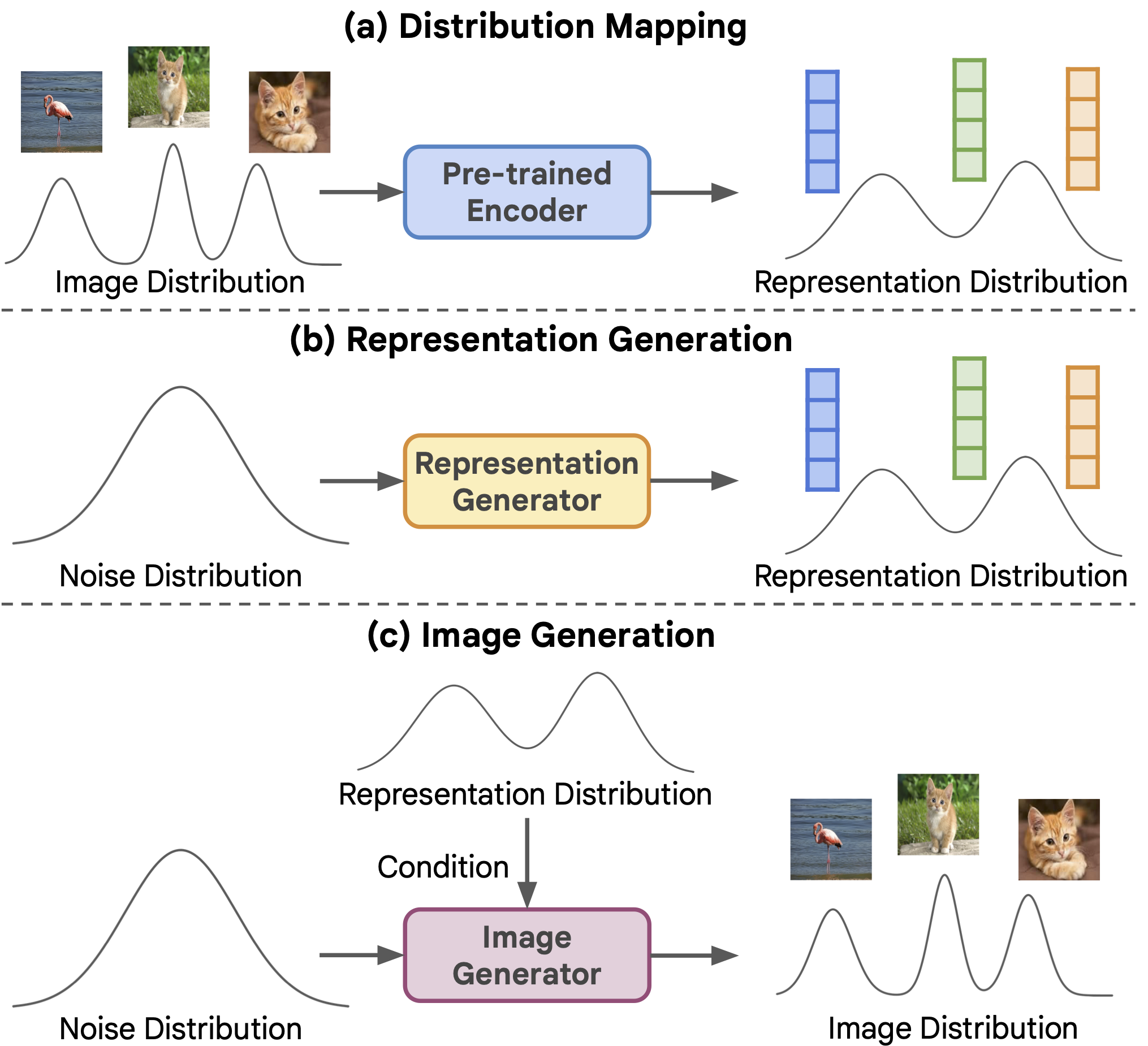
这是论文无条件生成的回归:一种自监督表示生成方法的 PyTorch/GPU 实现:
@Article{RCG2023,
author = {Tianhong Li and Dina Katabi and Kaiming He},
journal = {arXiv:2312.03701},
title = {Return of Unconditional Generation: A Self-supervised Representation Generation Method},
year = {2023},
}
RCG 是一个自条件图像生成框架,在 ImageNet 256x256 上实现了最先进的无条件图像生成性能,弥合了长期存在的无条件和类条件图像生成之间的性能差距。
更新
2024 年 3 月
- 更新 FID 评估和结果,遵循 ADM suite,通过在
torch-fidelity中硬编码 ADM 统计信息。 可以通过以下方式安装修改后的torch-fidelity:
pip install -e git+https://github.com/LTH14/torch-fidelity.git@master#egg=torch-fidelity
- 更新训练 400 个周期的 ADM 检查点(与原论文相同)。
- 包含使用 RCG 训练 DiT-XL 的脚本和预训练检查点(400 个周期)。
- 更新 Arxiv。
准备工作
数据集
下载 ImageNet 数据集,并将其放在您的 IMAGENET_DIR 中。
准备 ImageNet 验证集以进行 FID 评估:
python prepare_imgnet_val.py --data_path ${IMAGENET_DIR} --output_dir imagenet-val
要对验证集进行 FID 评估,请执行 pip install torch-fidelity,这将安装原始的 torch-fidelity 包。
安装
下载代码
git clone https://github.com/LTH14/rcg.git
cd rcg
可以使用以下命令创建并激活名为 rcg 的合适 conda 环境:
conda env create -f environment.yaml
conda activate rcg
使用此链接
下载预训练的 VQGAN 分词器,命名为 vqgan_jax_strongaug.ckpt。
使用此链接
下载预训练的 moco v3 ViT-B 编码器,并将其命名为 pretrained_enc_ckpts/mocov3/vitb.pth.tar。
使用此链接
下载预训练的 moco v3 ViT-L 编码器,并将其命名为 pretrained_enc_ckpts/mocov3/vitl.pth.tar。
使用方法
RDM
使用 4 个 V100 GPU 训练 Moco v3 ViT-B 表示扩散模型:
python -m torch.distributed.launch --nproc_per_node=4 --nnodes=1 --node_rank=0 \
main_rdm.py \
--config config/rdm/mocov3vitb_simplemlp_l12_w1536.yaml \
--batch_size 128 --input_size 256 \
--epochs 200 \
--blr 1e-6 --weight_decay 0.01 \
--output_dir ${OUTPUT_DIR} \
--data_path ${IMAGENET_DIR} \
--dist_url tcp://${MASTER_SERVER_ADDRESS}:2214
要继续之前中断的训练会话,请将 --resume 设置为存储 checkpoint-last.pth 的 OUTPUT_DIR。
下表提供了论文中使用的预训练 Moco v3 ViT-B/ViT-L RDM 权重:
| Moco v3 ViT-B | Moco v3 ViT-L | |
|---|---|---|
| 类无条件 RDM | Google Drive / 配置 | Google Drive / 配置 |
| 类条件 RDM | Google Drive / 配置 | Google Drive / 配置 |
像素生成器:MAGE
使用 64 个 V100 GPU 训练一个基于 Moco v3 ViT-B 表示的 MAGE-B,训练 200 个周期:
python -m torch.distributed.launch --nproc_per_node=8 --nnodes=8 --node_rank=0 \
main_mage.py \
--pretrained_enc_arch mocov3_vit_base \
--pretrained_enc_path pretrained_enc_ckpts/mocov3/vitb.pth.tar --rep_drop_prob 0.1 \
--use_rep --rep_dim 256 --pretrained_enc_withproj --pretrained_enc_proj_dim 256 \
--pretrained_rdm_cfg ${RDM_CFG_PATH} --pretrained_rdm_ckpt ${RDM_CKPT_PATH} \
--rdm_steps 250 --eta 1.0 --temp 6.0 --num_iter 20 --num_images 50000 --cfg 0.0 \
--batch_size 64 --input_size 256 \
--model mage_vit_base_patch16 \
--mask_ratio_min 0.5 --mask_ratio_max 1.0 --mask_ratio_mu 0.75 --mask_ratio_std 0.25 \
--epochs 200 \
--warmup_epochs 10 \
--blr 1.5e-4 --weight_decay 0.05 \
--output_dir ${OUTPUT_DIR} \
--data_path ${IMAGENET_DIR} \
--dist_url tcp://${MASTER_SERVER_ADDRESS}:2214
要训练基于 Moco v3 ViT-L 表示的 MAGE-L,
更改 Moco v3 ViT-L RDM 的 RDM_CFG_PATH 和 RDM_CKPT_PATH,以及以下参数:
--pretrained_enc_arch mocov3_vit_large --pretrained_enc_path pretrained_enc_ckpts/mocov3/vitl.pth.tar --temp 11.0 --model mage_vit_large_patch16
恢复:将 --resume 设置为存储 checkpoint-last.pth 的 OUTPUT_DIR。
评估:将 --resume 设置为预训练的 MAGE 检查点,
并在上述脚本中包含 --evaluate 标志。
预训练模型:
| 表示条件 MAGE-B | 表示条件 MAGE-L | |
|---|---|---|
| 检查点 | Google Drive | Google Drive |
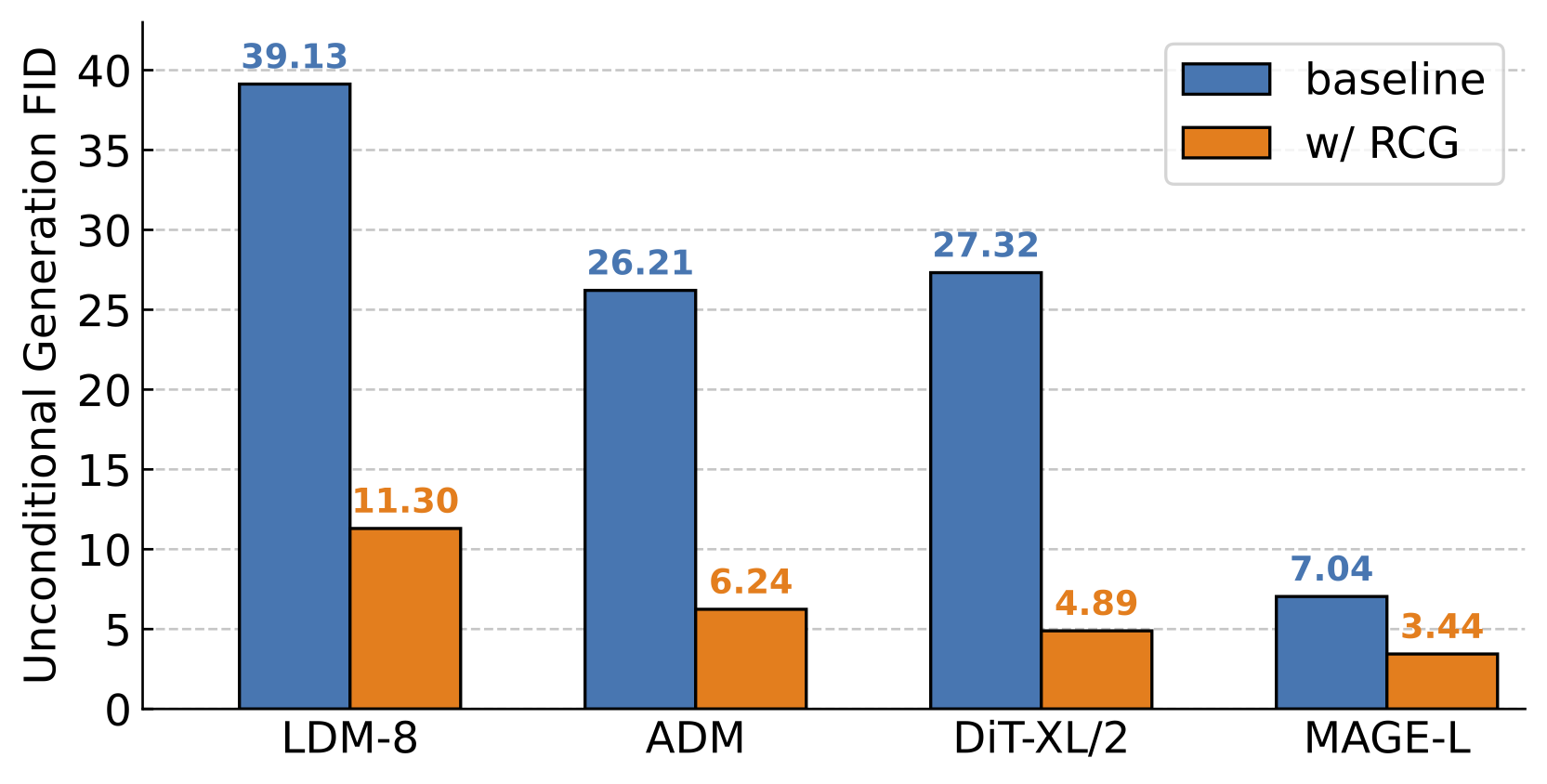
| 类无条件生成(无 CFG) | FID=3.98,IS=177.8 | FID=3.44,IS=186.9 |
| 类无条件生成(有 CFG) | FID=3.19,IS=214.9(cfg=1.0) | FID=2.15,IS=253.4(cfg=6.0) |
| 类条件生成(无 CFG) | FID=3.50,IS=194.9 | FID=2.99,IS=215.5 |
| 类条件生成(有 CFG) | FID=3.18,IS=242.6(cfg=1.0) | FID=2.25,IS=300.7(cfg=6.0) |
可视化:使用 viz_rcg.ipynb 可视化生成结果。
类无条件生成示例:

类条件生成示例:

像素生成器:DiT
要训练一个基于Moco v3 ViT-B表示的DiT-L模型,使用128个V100 GPU进行400轮训练:
python -m torch.distributed.launch --nproc_per_node=8 --nnodes=16 --node_rank=0 \
main_dit.py \
--rep_cond --rep_dim 256 \
--pretrained_enc_arch mocov3_vit_base \
--pretrained_enc_path pretrained_enc_ckpts/mocov3/vitb.pth.tar \
--pretrained_rdm_cfg ${RDM_CFG_PATH} \
--pretrained_rdm_ckpt ${RDM_CKPT_PATH} \
--batch_size 16 --image_size 256 --dit_model DiT-L/2 --num-sampling-steps ddim25 \
--epochs 400 \
--lr 1e-4 --weight_decay 0.0 \
--output_dir ${OUTPUT_DIR} \
--data_path ${IMAGENET_DIR} \
--dist_url tcp://${MASTER_SERVER_ADDRESS}:2214
注意:有时对于DiT-XL,batch_size=16会导致内存溢出。将其改为12或14对性能影响很小。
恢复训练:将--resume设置为存储checkpoint-last.pth的OUTPUT_DIR。
评估:将--resume设置为预训练的DiT检查点,并在上述脚本中包含--evaluate标志。设置--num-sampling-steps 250以获得更好的生成性能。
基于Moco v3 ViT-B表示的预训练DiT-XL/2(400轮)可以在这里下载(FID=4.89,IS=143.2)。
像素生成器:ADM
要训练一个基于Moco v3 ViT-B表示的ADM模型,使用128个V100 GPU进行100轮训练:
python -m torch.distributed.launch --nproc_per_node=8 --nnodes=16 --node_rank=0 \
main_adm.py \
--rep_cond --rep_dim 256 \
--pretrained_enc_arch mocov3_vit_base \
--pretrained_enc_path pretrained_enc_ckpts/mocov3/vitb.pth.tar \
--pretrained_rdm_cfg ${RDM_CFG_PATH} \
--pretrained_rdm_ckpt ${RDM_CKPT_PATH} \
--batch_size 2 --image_size 256 \
--epochs 100 \
--lr 1e-4 --weight_decay 0.0 \
--attention_resolutions 32,16,8 --diffusion_steps 1000 \
--learn_sigma --noise_schedule linear \
--num_channels 256 --num_head_channels 64 --num_res_blocks 2 --resblock_updown \
--use_scale_shift_norm \
--gen_timestep_respacing ddim25 --use_ddim \
--output_dir ${OUTPUT_DIR} \
--data_path ${IMAGENET_DIR} \
--dist_url tcp://${MASTER_SERVER_ADDRESS}:2214
恢复训练:将--resume设置为存储checkpoint-last.pth的OUTPUT_DIR。
评估:将--resume设置为预训练的ADM检查点,并在上述脚本中包含--evaluate标志。设置--gen_timestep_respacing 250并禁用--use_ddim以获得更好的生成性能。
基于Moco v3 ViT-B表示的预训练ADM(400轮)可以在这里下载(FID=6.24,IS=136.9)。
像素生成器:LDM
使用此链接下载分词器,并将其命名为vqgan-ckpts/ldm_vqgan_f8_16384/checkpoints/last.ckpt。
要训练一个基于Moco v3 ViT-B表示的LDM-8模型,使用64个V100 GPU进行40轮训练:
python -m torch.distributed.launch --nproc_per_node=8 --nnodes=8 --node_rank=0 \
main_ldm.py \
--config config/ldm/cin-ldm-vq-f8-repcond.yaml \
--batch_size 4 \
--epochs 40 \
--blr 2.5e-7 --weight_decay 0.01 \
--output_dir ${OUTPUT_DIR} \
--data_path ${IMAGENET_DIR} \
--dist_url tcp://${MASTER_SERVER_ADDRESS}:2214
恢复训练:将--resume设置为存储checkpoint-last.pth的OUTPUT_DIR。
评估:将--resume设置为预训练的LDM检查点,并在上述脚本中包含--evaluate标志。
基于Moco v3 ViT-B表示的预训练LDM(40轮)可以在这里下载(FID=11.30,IS=101.9)。
联系方式
如果您有任何问题,请随时通过电子邮件(tianhong@mit.edu)与我联系。祝您使用愉快!











