
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文

PhotoMaker: 通过堆叠ID嵌入定制真实人物照片 
[💥新 🤗 演示 (PhotoMaker V2)] [🤗 演示 (真实风格)] [🤗 演示 (艺术风格)]
[Replicate演示 (真实风格)] [Replicate演示 (艺术风格)] [Jittor版本]
PhotoMaker-V2 由HunyuanDiT团队支持。
🥳 我们发布了 PhotoMaker V2。请参阅比较查看PhotoMaker V1、PhotoMaker V2、IP-Adapter-FaceID-plus-V2和InstantID之间的对比。观看此视频了解如何使用我们的演示。关于PhotoMaker V2 ComfyUI节点,请参考相关资源
🌠 主要特点:
- 仅需数秒即可快速定制,无需额外的LoRA训练。
- 确保出色的ID保真度,提供多样性,承诺文本可控性和高质量生成。
- 可作为适配器与社区中的其他基础模型和LoRA模块协作。
❗❗ 注意:如果有任何基于PhotoMaker的资源和应用,请在讨论区留言,我们将在README文件的相关资源部分列出。 目前我们已知Replicate、Windows、ComfyUI和WebUI的实现。感谢大家!
🚩 新特性/更新
- ✅ 2024年7月22日。💥 我们发布了PhotoMaker V2,具有改进的ID保真度。同时,它仍保持了PhotoMaker V1提供的生成质量、可编辑性和与任何插件的兼容性。我们还提供了与ControlNet、T2I-Adapter和IP-Adapter集成的脚本,以提供出色的控制能力。用户可以进一步定制脚本进行升级,例如结合LCM加速或集成IP-Adapter-FaceID或InstantID以进一步提高ID保真度。我们将很快发布PhotoMaker V2的技术报告。请参阅此文档快速预览。
- ✅ 2024年1月20日。重要提示:对于不支持bfloat16的GPU,请将这一行改为
torch_dtype = torch.float16,速度将大幅提升(V100上从之前的1分钟/图提升到14秒/图)。PhotoMaker的最低GPU内存要求为11G(请参考此链接以节省GPU内存)。 - ✅ 2024年1月15日。我们发布了PhotoMaker。
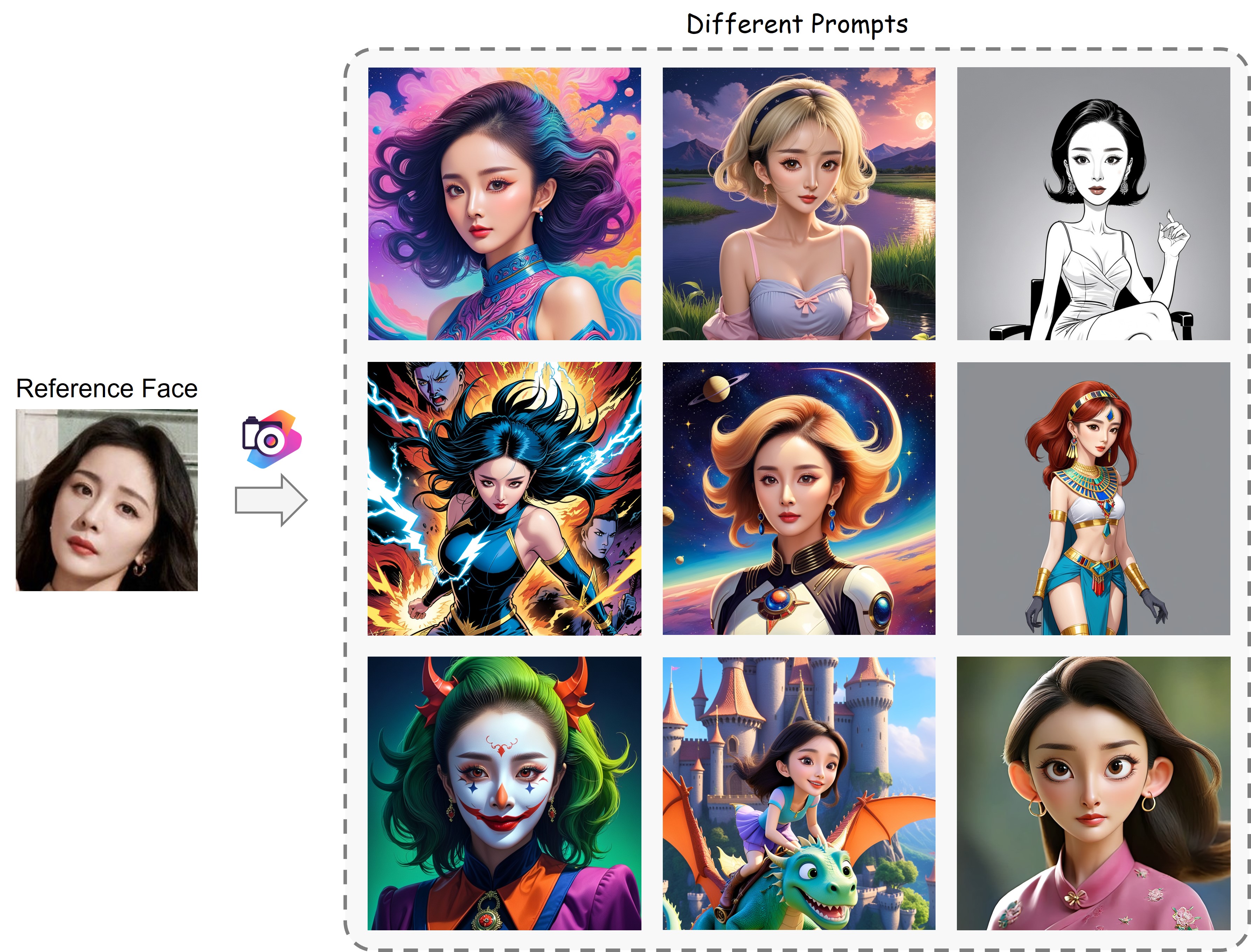
🔥 示例
真实风格生成



风格化生成
注意:只需更改基础模型并添加 LoRA 模块以获得更好的风格化效果

🔧 依赖和安装
- Python >= 3.8(推荐使用 Anaconda 或 Miniconda)
- PyTorch >= 2.0.0
conda create --name photomaker python=3.10
conda activate photomaker
pip install -U pip
# 安装依赖
pip install -r requirements.txt
# 安装 photomaker
pip install git+https://github.com/TencentARC/PhotoMaker.git
然后你可以运行以下命令来使用它
from photomaker import PhotoMakerStableDiffusionXLPipeline
⏬ 下载模型
模型将通过以下两行代码自动下载:
from huggingface_hub import hf_hub_download
photomaker_path = hf_hub_download(repo_id="TencentARC/PhotoMaker", filename="photomaker-v1.bin", repo_type="model")
你也可以选择从这个 链接 手动下载。
💻 如何测试
像 diffusers 一样使用
- 依赖
import torch
import os
from diffusers.utils import load_image
from diffusers import EulerDiscreteScheduler
from photomaker import PhotoMakerStableDiffusionXLPipeline
### 加载基础模型
pipe = PhotoMakerStableDiffusionXLPipeline.from_pretrained(
base_model_path, # 可以更改为基于 SDXL 的任何基础模型
torch_dtype=torch.bfloat16,
use_safetensors=True,
variant="fp16"
).to(device)
### 加载 PhotoMaker 检查点
pipe.load_photomaker_adapter(
os.path.dirname(photomaker_path),
subfolder="",
weight_name=os.path.basename(photomaker_path),
trigger_word="img" # 定义触发词
)
pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config)
### 也可以与其他 LoRA 模块配合使用
# pipe.load_lora_weights(os.path.dirname(lora_path), weight_name=lora_model_name, adapter_name="xl_more_art-full")
# pipe.set_adapters(["photomaker", "xl_more_art-full"], adapter_weights=[1.0, 0.5])
pipe.fuse_lora()
- 输入 ID 图像
### 定义输入 ID 图像
input_folder_name = './examples/newton_man'
image_basename_list = os.listdir(input_folder_name)
image_path_list = sorted([os.path.join(input_folder_name, basename) for basename in image_basename_list])
input_id_images = []
for image_path in image_path_list:
input_id_images.append(load_image(image_path))
- 生成
# 注意,触发词 `img` 必须跟在类别词后面以实现个性化
prompt = "一张男子的半身肖像 img 戴着钢铁侠套装的太阳镜,最佳品质"
negative_prompt = "(不对称、最差质量、低质量、插图、3D、2D、绘画、卡通、素描)、张嘴、灰度"
generator = torch.Generator(device=device).manual_seed(42)
images = pipe(
prompt=prompt,
input_id_images=input_id_images,
negative_prompt=negative_prompt,
num_images_per_prompt=1,
num_inference_steps=num_steps,
start_merge_step=10,
generator=generator,
).images[0]
gen_images.save('out_photomaker.png')
启动本地gradio演示
运行以下命令:
python gradio_demo/app.py
你可以在这个文件中自定义此脚本。
如果你想在MAC上运行它,你应该按照这个说明操作,然后运行app.py。
使用技巧:
- 上传更多要定制的人物照片以提高ID保真度。如果输入的是亚洲人脸,可以考虑在类别词前加"Asian",例如"Asian woman img"
- 在风格化时,生成的脸看起来太真实吗?将风格强度调整到30-50,数字越大,ID保真度越低,但风格化能力会更好。你也可以尝试其他具有良好风格化效果的基础模型或LoRA。
- 减少生成的图像数量和采样步骤以提高速度。但请记住,减少采样步骤可能会影响ID保真度。
相关资源
PhotoMaker的Replicate演示:
- 演示链接,在Replicate上运行PhotoMaker,由@yorickvP和@jd7h提供。
- 演示链接(风格版本)。
PhotoMaker的WebUI版本:
- stable-diffusion-webui-forge:https://github.com/lllyasviel/stable-diffusion-webui-forge 由@Lvmin Zhang提供
- Fooocus App:Fooocus-inswapper 由@machineminded提供
PhotoMaker的Windows版本:
- bmaltais/PhotoMaker 由@bmaltais提供,易于在Windows上部署PhotoMaker。描述可以在这个链接中找到。
- sdbds/PhotoMaker-for-windows 由@sdbds提供。
ComfyUI:
- 🔥 ComfyUI的官方实现:https://github.com/comfyanonymous/ComfyUI/commit/d1533d9c0f1dde192f738ef1b745b15f49f41e02
- https://github.com/ZHO-ZHO-ZHO/ComfyUI-PhotoMaker
- https://github.com/StartHua/Comfyui-Mine-PhotoMaker
- https://github.com/shiimizu/ComfyUI-PhotoMaker
ComfyUI(用于PhotoMaker V2):
- https://github.com/shiimizu/ComfyUI-PhotoMaker-Plus
- https://github.com/edwios/ComfyUI-PhotoMakerV2-ZHO/tree/main
- https://openart.ai/workflows/shalacai/photomakerv2/fttT4ztRM85JxBJ2eUyr
纯C/C++/CUDA版本的PhotoMaker:
其他应用/网页演示
- Wisemodel 始智(在中国易于使用) https://wisemodel.cn/space/gradio/photomaker
- OpenXLab(在中国易于使用):https://openxlab.org.cn/apps/detail/camenduru/PhotoMaker
 由@camenduru提供。
由@camenduru提供。 - Colab:https://github.com/camenduru/PhotoMaker-colab 由@camenduru提供
- Monster API:https://monsterapi.ai/playground?model=photo-maker
- Pinokio:https://pinokio.computer/item?uri=https://github.com/cocktailpeanutlabs/photomaker
45行Gradio演示
由@Gradio提供
🤗 致谢
- PhotoMaker由腾讯ARC实验室和南开大学MCG-NKU联合开发。
- 受到许多优秀演示和仓库的启发,包括IP-Adapter、multimodalart/Ip-Adapter-FaceID、FastComposer和T2I-Adapter。感谢他们的杰出工作!
- 感谢HunyuanDiT团队的慷慨支持和建议!
- 感谢腾讯PCG的Venus团队提供的反馈和建议。
- 感谢HuggingFace团队的慷慨支持!
免责声明
本项目致力于积极影响AI驱动的图像生成领域。用户可以自由使用此工具创建图像,但需遵守当地法律并负责任地使用。开发者不对用户可能的滥用承担任何责任。
BibTeX
如果您发现PhotoMaker对您的研究和应用有用,请使用以下BibTeX进行引用:
@inproceedings{li2023photomaker,
title={PhotoMaker: Customizing Realistic Human Photos via Stacked ID Embedding},
author={Li, Zhen and Cao, Mingdeng and Wang, Xintao and Qi, Zhongang and Cheng, Ming-Ming and Shan, Ying},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2024}
}











