
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文MotionBERT:学习人体运动表示的统一视角

![]()
![]()
![]()
这是论文《MotionBERT:学习人体运动表示的统一视角》(ICCV 2023)的官方 PyTorch 实现。
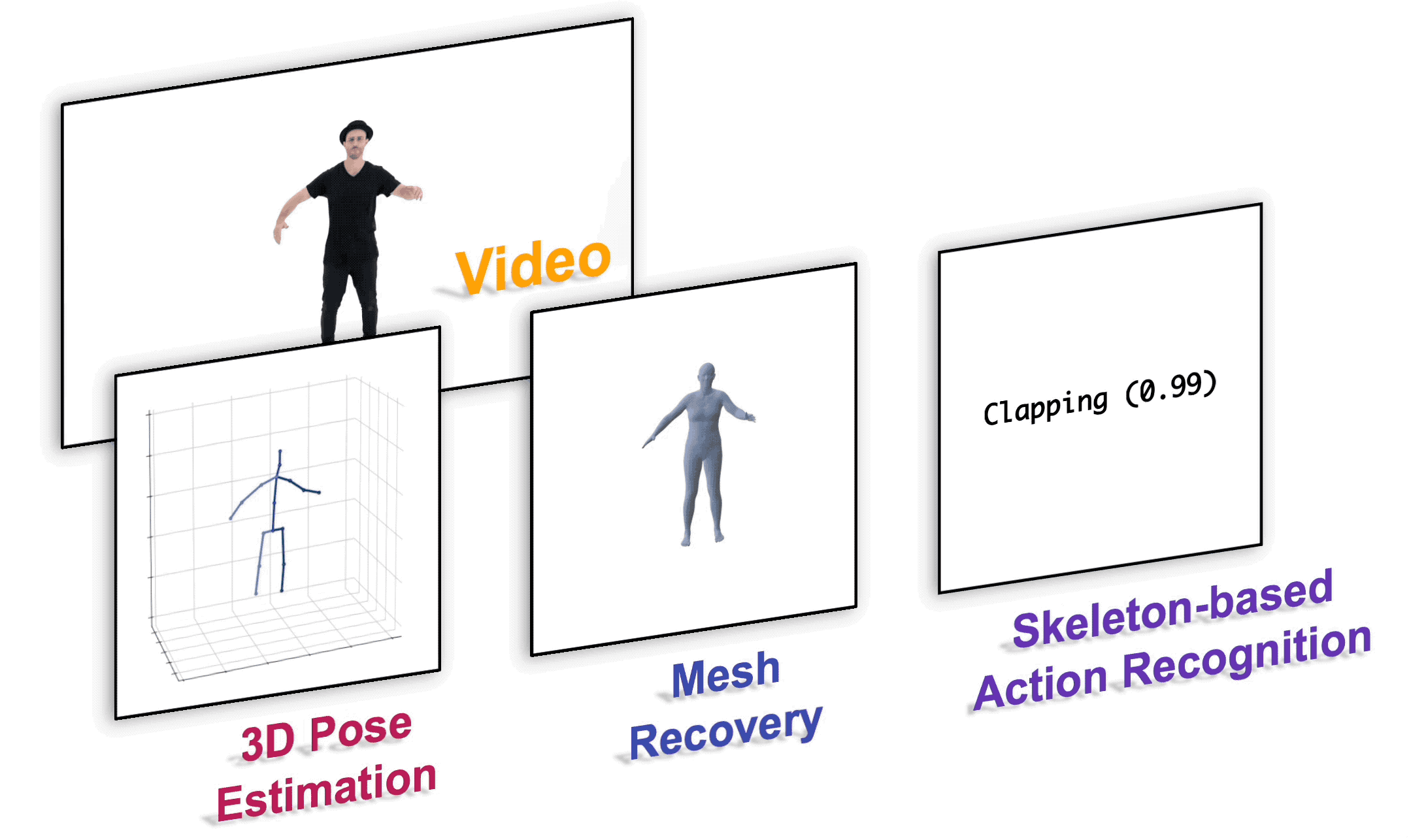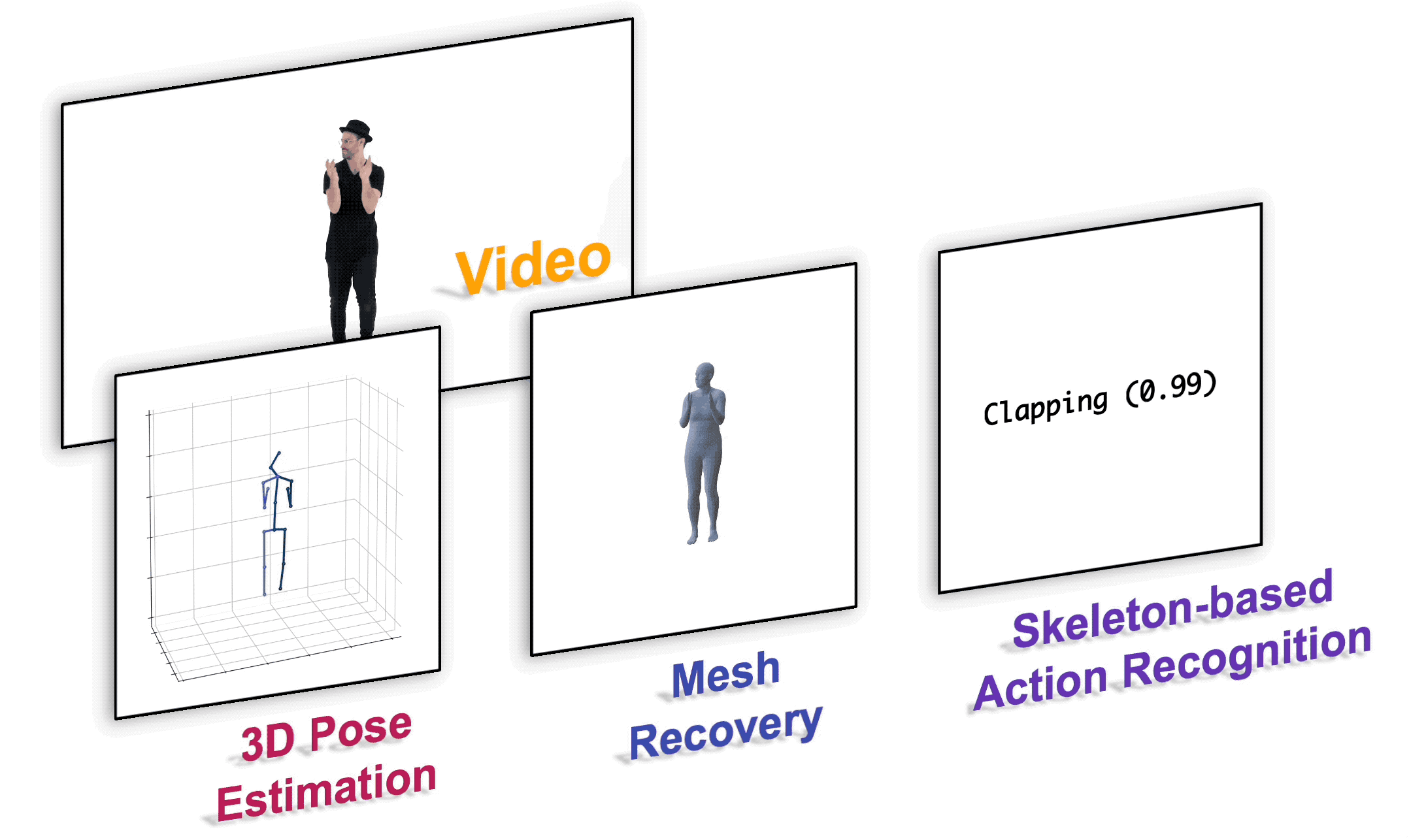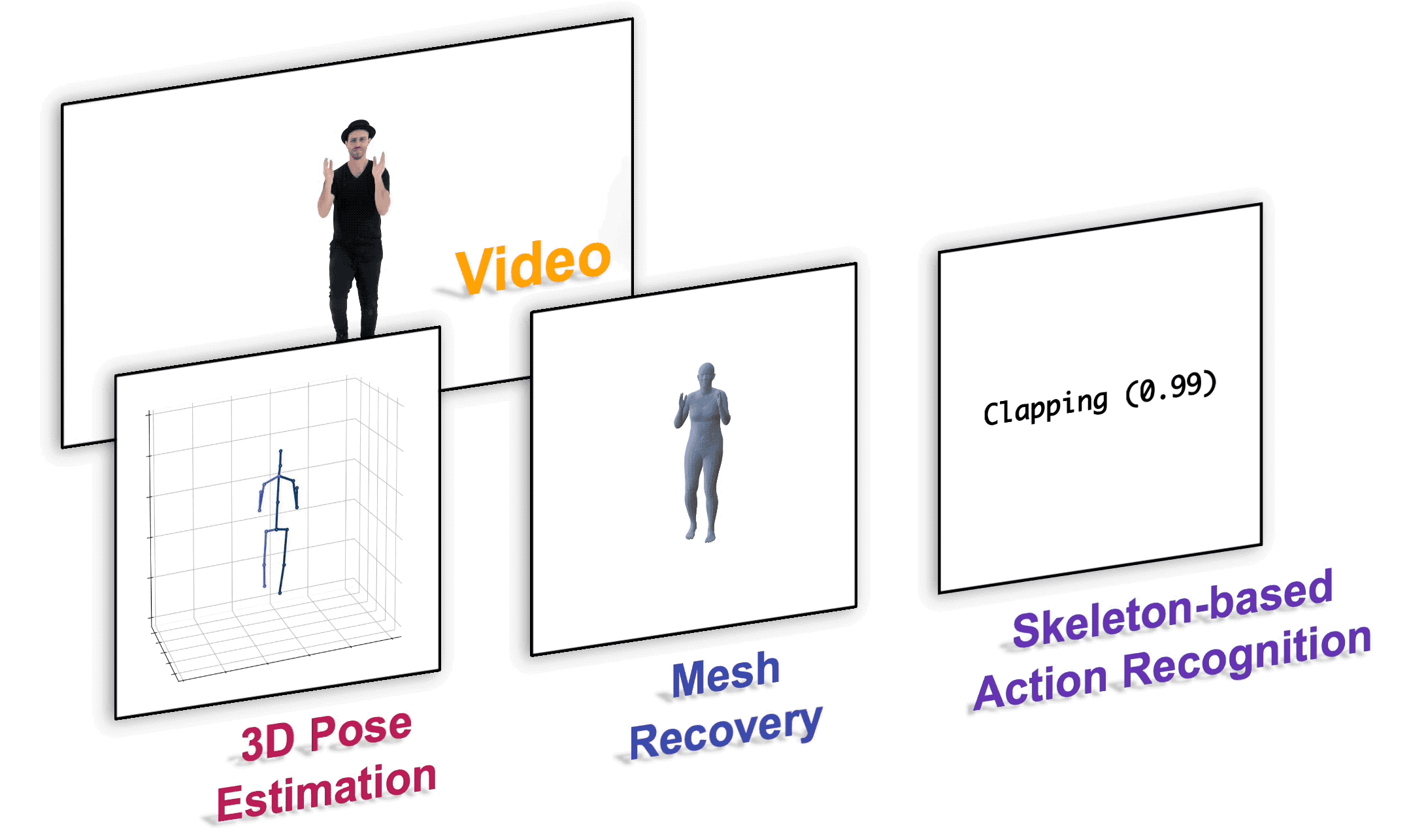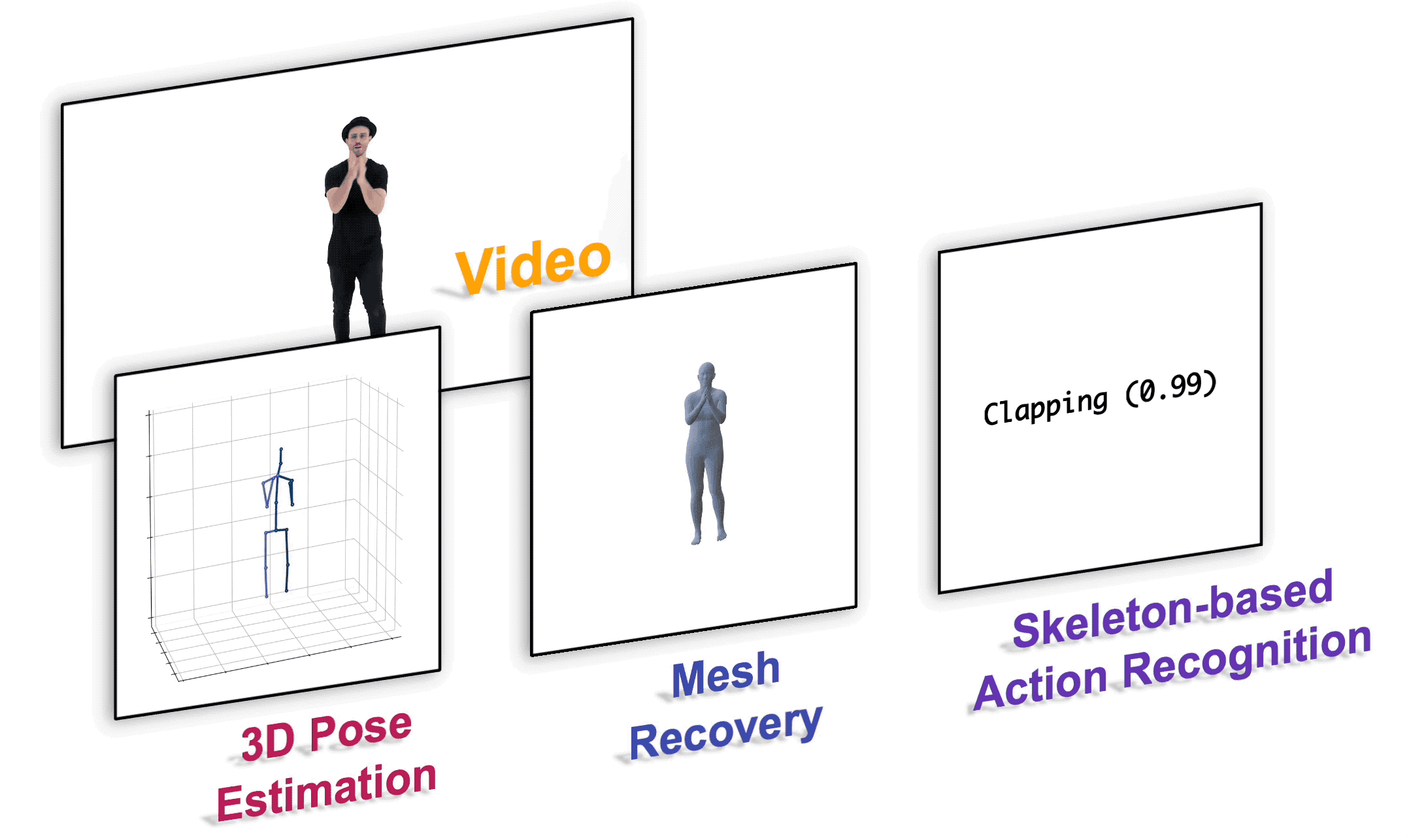
安装
conda create -n motionbert python=3.7 anaconda
conda activate motionbert
# 请根据您的 CUDA 版本安装 PyTorch
conda install pytorch torchvision torchaudio pytorch-cuda=11.6 -c pytorch -c nvidia
pip install -r requirements.txt
开始使用
| 任务 | 文档 |
|---|---|
| 预训练 | docs/pretrain.md |
| 3D 人体姿态估计 | docs/pose3d.md |
| 基于骨架的动作识别 | docs/action.md |
| 人体网格重建 | docs/mesh.md |
应用
野外推理(用于自定义视频)
请参考 docs/inference.md。
使用 MotionBERT 进行以人为中心的视频表示
'''
x: 2D 骨架
类型 = <class 'torch.Tensor'>
形状 = [批量大小 * 帧数 * 关节点数(17) * 通道数(3)]
MotionBERT: 预训练的人体运动编码器
类型 = <class 'lib.model.DSTformer.DSTformer'>
E: 编码后的运动表示
类型 = <class 'torch.Tensor'>
形状 = [批量大小 * 帧数 * 关节点数(17) * 通道数(512)]
'''
E = MotionBERT.get_representation(x)
提示
- 该模型可以处理不同的输入长度(不超过243帧)。无需在其他地方显式指定输入长度。
- 该模型使用17个身体关键点(H36M 格式)。如果您使用其他格式,请在输入 MotionBERT 之前进行转换。
- 请参考 model_action.py 和 model_mesh.py 了解如何(轻松地)将 MotionBERT 适配到不同的下游任务。
- 对于 RGB 视频,您需要提取 2D 姿态(inference.md),转换关键点格式(dataset_wild.py),然后输入 MotionBERT(infer_wild.py)。
模型库
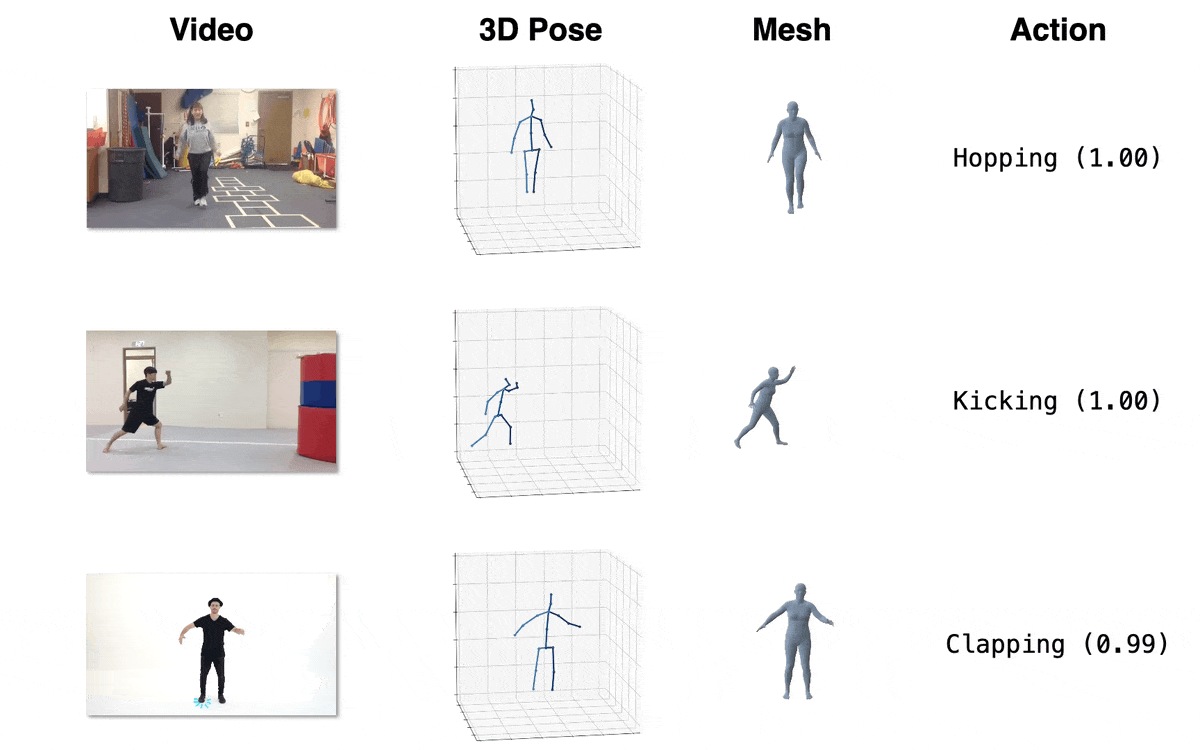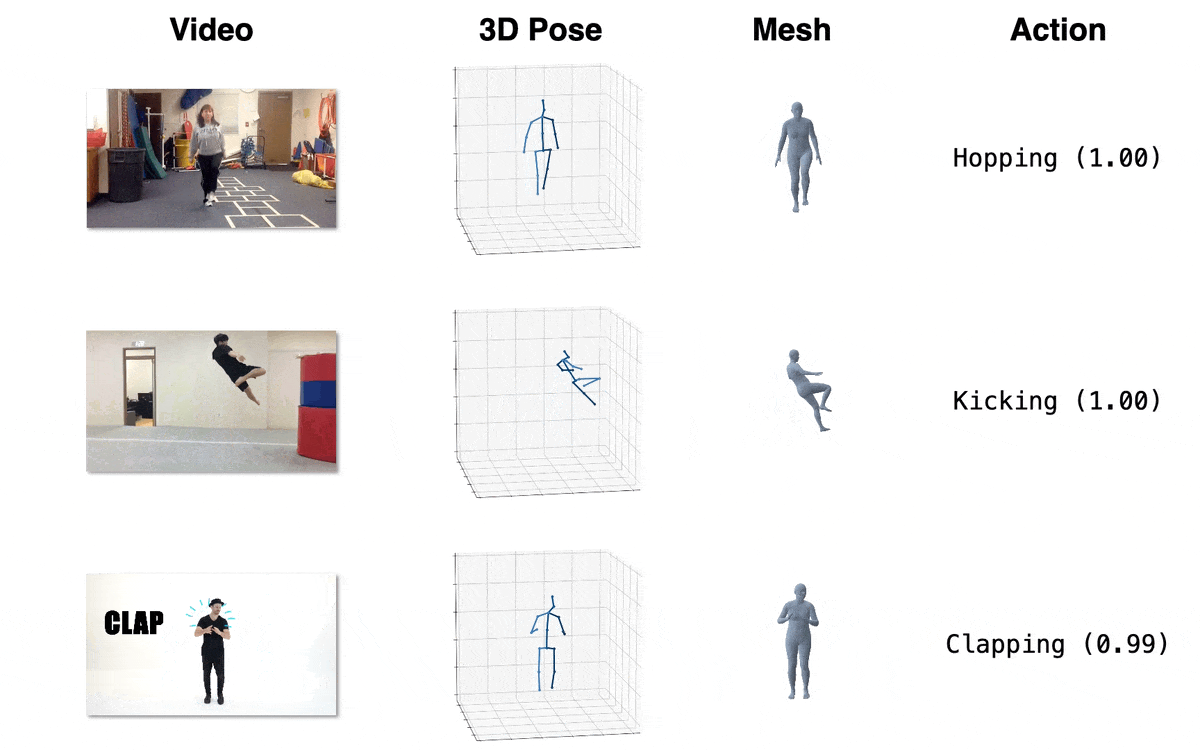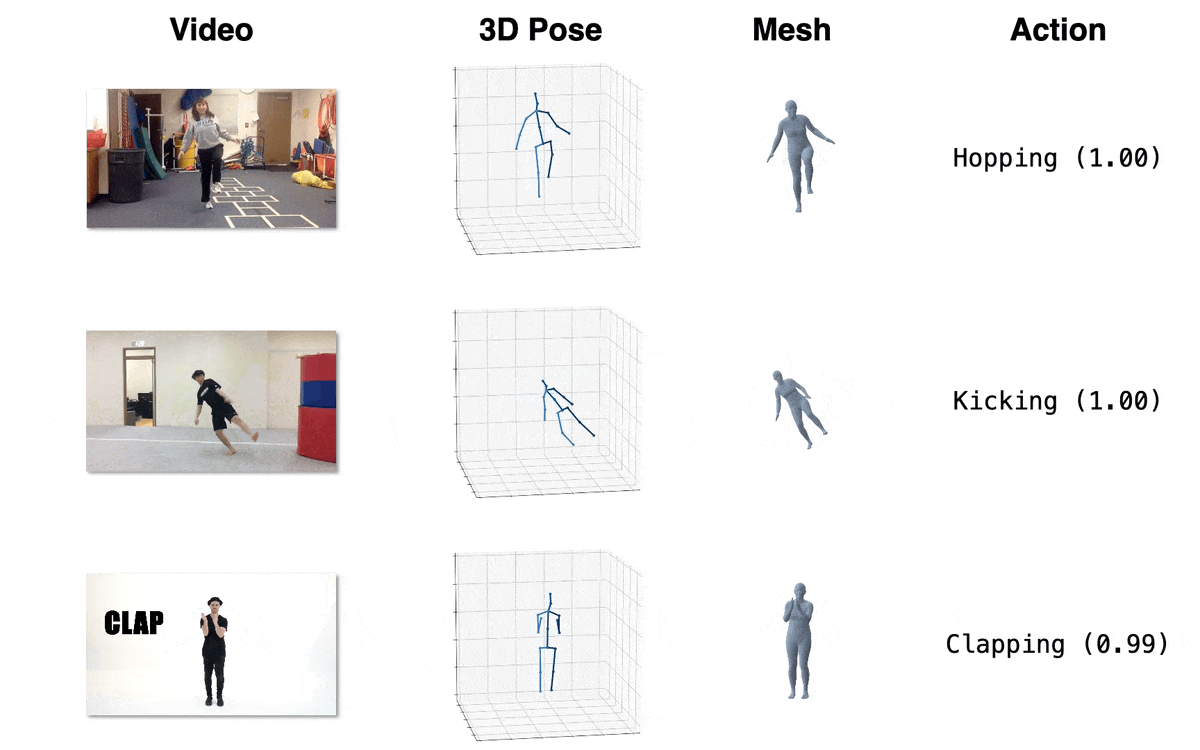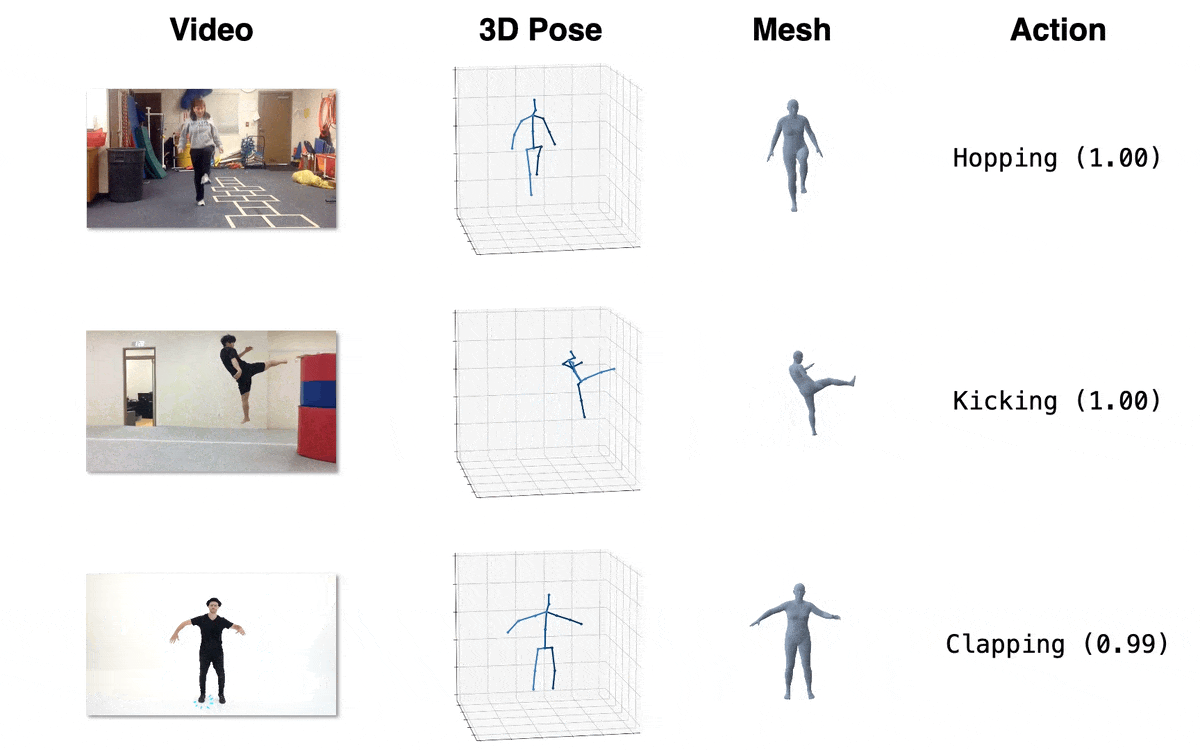
| 模型 | 下载链接 | 配置文件 | 性能 |
|---|---|---|---|
| MotionBERT (162MB) | OneDrive | pretrain/MB_pretrain.yaml | - |
| MotionBERT-Lite (61MB) | OneDrive | pretrain/MB_lite.yaml | - |
| 3D 姿态 (H36M-SH, 从头训练) | OneDrive | pose3d/MB_train_h36m.yaml | 39.2mm (MPJPE) |
| 3D 姿态 (H36M-SH, 微调) | OneDrive | pose3d/MB_ft_h36m.yaml | 37.2mm (MPJPE) |
| 动作识别 (跨主体, 微调) | OneDrive | action/MB_ft_NTU60_xsub.yaml | 97.2% (Top1 准确率) |
| 动作识别 (跨视角, 微调) | OneDrive | action/MB_ft_NTU60_xview.yaml | 93.0% (Top1 准确率) |
| 网格重建 (使用 3DPW, 微调) | OneDrive | mesh/MB_ft_pw3d.yaml | 88.1mm (MPVE) |
在大多数使用场景中(特别是在微调时),MotionBERT-Lite 能够以较低的计算开销提供相似的性能。
待办事项
- 预训练的脚本和文档
- 自定义视频的演示
引用
如果您发现我们的工作对您的项目有用,请考虑引用以下论文:
@inproceedings{motionbert2022,
title = {MotionBERT: A Unified Perspective on Learning Human Motion Representations},
author = {Zhu, Wentao and Ma, Xiaoxuan and Liu, Zhaoyang and Liu, Libin and Wu, Wayne and Wang, Yizhou},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision},
year = {2023},
}











