
 Github
Github Huggingface
Huggingface 论文
论文CrossFormer++
这个仓库是我们以下论文的代码:
-
CrossFormer++: 基于跨尺度注意力的多功能视觉Transformer (IEEE TPAMI 接收)。
-
CrossFormer: 基于跨尺度注意力的多功能视觉Transformer (ICLR 2022 接收)。
crossformer 分支保留了旧版本代码和旧依赖项。
更新
- 使用3x训练计划的Mask-RCNN检测/实例分割结果。
- 使用3x训练计划的Cascade Mask-RCNN检测/实例分割结果。
- 在检测和分割中使用
get_flops.py。 - 上传预训练的CrossFormer-L。
- 上传CrossFormer++-S/B/L/H分类的预训练模型。
- 上传用于检测和分割的CrossFormer++-S/B/L。
简介
现有的视觉Transformer无法在不同尺度的对象/特征之间建立注意力(跨尺度注意力),而这种能力对视觉任务非常重要。CrossFormer是一种多功能的视觉Transformer,解决了这个问题。它的核心设计包括跨尺度嵌入层(CEL)和长短距离注意力(L/SDA),它们共同实现了跨尺度注意力。
CEL将每个输入嵌入与多尺度特征混合。L/SDA将所有嵌入分成几组,自注意力仅在每组内计算(具有相同颜色边框的嵌入属于同一组)。
此外,我们还提出了一个动态位置偏置(DPB)模块,使有效但不灵活的相对位置偏置适用于可变图像大小。
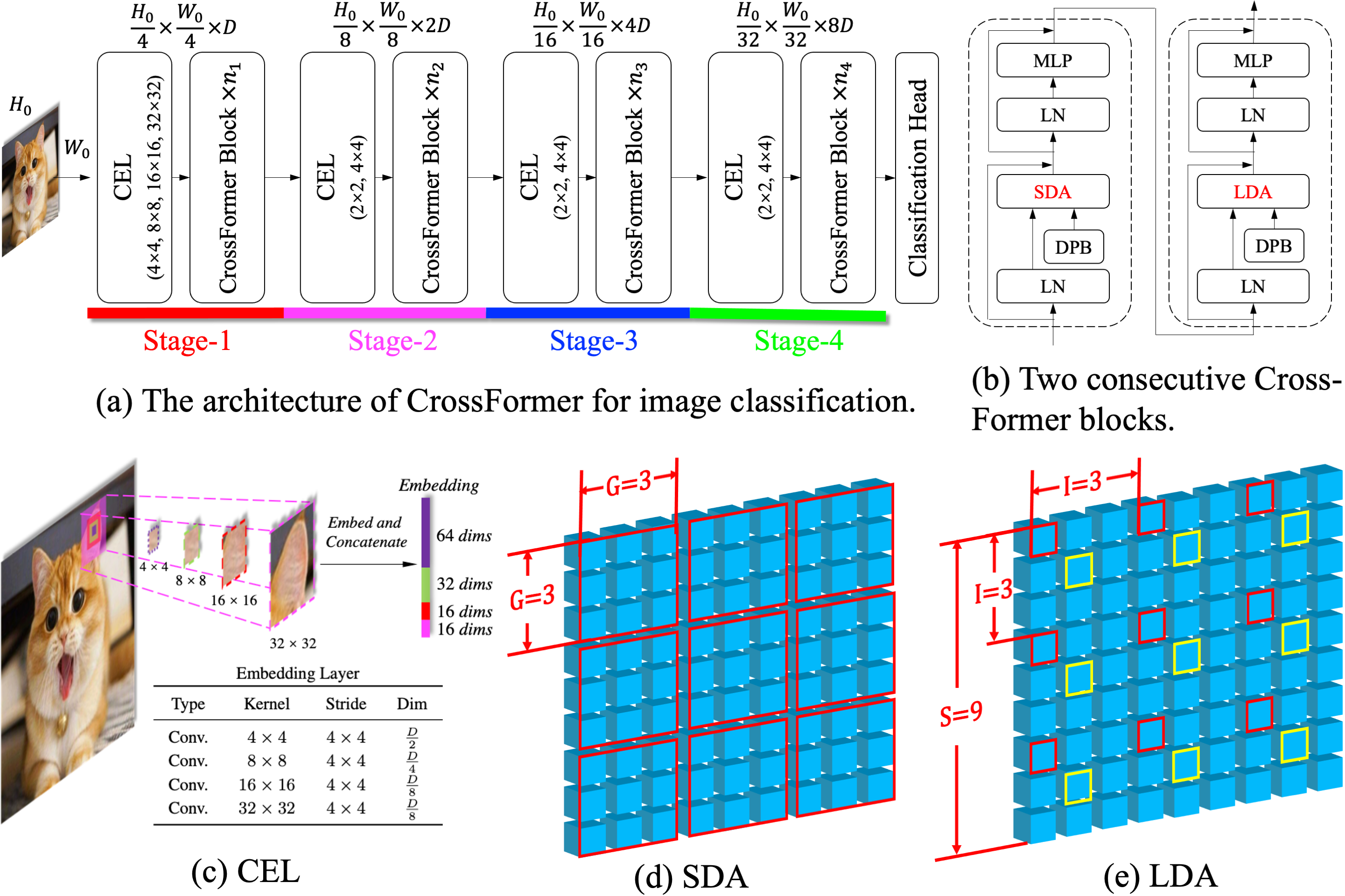
进一步,在CrossFormer++中,我们引入了渐进组大小(PGS)策略,以在性能和计算预算之间实现更好的平衡,并引入了激活冷却层(ACL)来抑制残差流中激活幅度的剧烈增长。

目前,实验已在四个具有代表性的视觉任务上完成,即图像分类、目标检测和实例/语义分割。结果表明,CrossFormer在这些任务中优于现有的视觉Transformer,尤其是在密集预测任务(即目标检测和实例/语义分割)中。我们认为这是因为图像分类只关注一个对象和大尺度特征,而密集预测任务更依赖于跨尺度注意力。
准备工作
- 创建并激活conda环境
conda create -n crossformer_env python=3.9 -y
conda activate crossformer_env
- 库(基于Python3.9)
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
pip install tensorboard termcolor
pip install timm pyyaml yacs protobuf==3.20.0
-
数据集:ImageNet
-
检测/实例分割和语义分割的要求列在这里:detection/README.md 或 segmentation/README.md
为了便于使用,我们已经将CrossFormer和CrossFormer++的代码适配到了较新版本的pytorch、mmcv、mmdetection和mmsegmentation,因此本仓库中的结果可能与论文中报告的结果略有不同。
如果您使用的是较旧版本的CUDA,请考虑使用本仓库 crossformer 分支中的原始CrossFormer代码。
入门
训练
## path_to_imagenet 路径下应该有两个目录:train 和 validation
## CrossFormer-T
python -u -m torch.distributed.launch --nproc_per_node 8 main.py --cfg configs/crossformer/tiny_patch4_group7_224.yaml \
--batch-size 128 --data-path path_to_imagenet --output ./output
## CrossFormer-S
python -u -m torch.distributed.launch --nproc_per_node 8 main.py --cfg configs/crossformer/small_patch4_group7_224.yaml \
--batch-size 128 --data-path path_to_imagenet --output ./output
## CrossFormer-B
python -u -m torch.distributed.launch --nproc_per_node 8 main.py --cfg configs/crossformer/base_patch4_group7_224.yaml
--batch-size 128 --data-path path_to_imagenet --output ./output
## CrossFormer-L
python -u -m torch.distributed.launch --nproc_per_node 8 main.py --cfg configs/crossformer/large_patch4_group7_224.yaml \
--batch-size 128 --data-path path_to_imagenet --output ./output
## CrossFormer++-S
python -u -m torch.distributed.launch --nproc_per_node 8 main.py --cfg configs/crossformer_pp/small_patch4_group_const_224.yaml \
--batch-size 128 --data-path path_to_imagenet --output ./output
## CrossFormer++-B
python -u -m torch.distributed.launch --nproc_per_node 8 main.py --cfg configs/crossformer_pp/base_patch4_group_const_224.yaml \
--batch-size 128 --data-path path_to_imagenet --output ./output
## CrossFormer++-L
python -u -m torch.distributed.launch --nproc_per_node 8 main.py --cfg configs/crossformer_pp/large_patch4_group_const_224.yaml \
--batch-size 128 --data-path path_to_imagenet --output ./output
测试
## 以CrossFormer-T为例评估准确率
python -u -m torch.distributed.launch --nproc_per_node 1 main.py --cfg configs/crossformer/small_patch4_group7_224.yaml \
--batch-size 128 --data-path path_to_imagenet --eval --resume path_to_crossformer-t.pth
## 以CrossFormer-T为例测试吞吐量
python -u -m torch.distributed.launch --nproc_per_node 1 main.py --cfg configs/crossformer/small_patch4_group7_224.yaml \
--batch-size 128 --data-path path_to_imagenet --throughput
您需要相应地修改 path_to_imagenet 和 path_to_crossformer-t.pth。
目标检测的训练和测试脚本:detection/README.md。
语义分割的训练和测试脚本:segmentation/README.md。
结果
图像分类
模型在ImageNet-1K上训练并在其验证集上评估。输入图像大小为224 x 224。
| 架构 | 参数量 | FLOPs | 准确率 | 模型 |
|---|---|---|---|---|
| ResNet-50 | 25.6M | 4.1G | 76.2% | - |
| RegNetY-8G | 39.0M | 8.0G | 81.7% | - |
| CrossFormer-T | 27.8M | 2.9G | 81.5% | 谷歌云盘/百度网盘, 提取码: nkju |
| CrossFormer-S | 30.7M | 4.9G | 82.5% | 谷歌云盘/百度网盘, 提取码: fgqj |
| CrossFormer++-S | 23.3M | 4.9G | 83.2% | 百度网盘, 提取码:crsf |
| CrossFormer-B | 52.0M | 9.2G | 83.4% | 谷歌云盘/百度网盘, 提取码: 7md9 |
| CrossFormer++-B | 52.0M | 9.5G | 84.2% | 百度网盘, 提取码:crsf |
| CrossFormer-L | 92.0M | 16.1G | 84.0% | 谷歌云盘/百度网盘, 提取码: cc89 |
| CrossFormer++-L | 92.0M | 16.6G | 84.7% | 百度网盘, 提取码:crsf |
| CrossFormer++-H | 96.0M | 21.8G | 84.9% | 百度网盘, 提取码:crsf |
与其他视觉transformer的更多对比结果可以在论文中看到。
注意:CrossFormer++的检查点将尽快发布。
目标检测和实例分割
模型在COCO 2017上训练。主干网络使用ImageNet-1K预训练权重进行初始化。
| 主干网络 | 检测头 | 学习策略 | 参数量 | FLOPs | box AP | mask AP |
|---|---|---|---|---|---|---|
| ResNet-101 | RetinaNet | 1x | 56.7M | 315.0G | 38.5 | - |
| CrossFormer-S | RetinaNet | 1x | 40.8M | 282.0G | 44.4 | - |
| CrossFormer++-S | RetinaNet | 1x | 40.8M | 282.0G | 45.1 | - |
| CrossFormer-B | RetinaNet | 1x | 62.1M | 389.0G | 46.2 | - |
| CrossFormer++-B | RetinaNet | 1x | 62.2M | 389.0G | 46.6 | - |
| 主干网络 | 检测头 | 学习策略 | 参数量 | FLOPs | box AP | mask AP |
|---|---|---|---|---|---|---|
| ResNet-101 | Mask-RCNN | 1x | 63.2M | 336.0G | 40.4 | 36.4 |
| CrossFormer-S | Mask-RCNN | 1x | 50.2M | 301.0G | 45.4 | 41.4 |
| CrossFormer++-S | Mask-RCNN | 1x | 43.0M | 287.4G | 46.4 | 42.1 |
| CrossFormer-B | Mask-RCNN | 1x | 71.5M | 407.9G | 47.2 | 42.7 |
| CrossFormer++-B | Mask-RCNN | 1x | 71.5M | 408.0G | 47.7 | 43.2 |
目标检测的更多结果和预训练模型:detection/README.md。
语义分割
模型在ADE20K上训练。主干网络使用ImageNet-1K预训练权重进行初始化。
| 主干网络 | 分割头 | 迭代次数 | 参数量 | 浮点运算次数 | IOU | 多尺度 IOU |
|---|---|---|---|---|---|---|
| CrossFormer-S | FPN | 80K | 34.3M | 209.8G | 46.4 | - |
| CrossFormer++-S | FPN | 80K | 27.1M | 199.5G | 47.4 | - |
| CrossFormer-B | FPN | 80K | 55.6M | 320.1G | 48.0 | - |
| CrossFormer++-B | FPN | 80K | 55.6M | 331.1G | 48.6 | - |
| CrossFormer-L | FPN | 80K | 95.4M | 482.7G | 49.1 | - |
| 主干网络 | 分割头 | 迭代次数 | 参数量 | 浮点运算次数 | IOU | 多尺度 IOU |
|---|---|---|---|---|---|---|
| ResNet-101 | UPerNet | 160K | 86.0M | 1029.G | 44.9 | - |
| CrossFormer-S | UPerNet | 160K | 62.3M | 979.5G | 47.6 | 48.4 |
| CrossFormer++-S | UPerNet | 160K | 53.1M | 963.5G | 49.4 | 50.8 |
| CrossFormer-B | UPerNet | 160K | 83.6M | 1089.7G | 49.7 | 50.6 |
| CrossFormer++-B | UPerNet | 160K | 83.7M | 1089.8G | 50.7 | 51.0 |
| CrossFormer-L | UPerNet | 160K | 125.5M | 1257.8G | 50.4 | 51.4 |
多尺度 IOU 表示使用多尺度测试的 IOU。
更多语义分割结果和预训练模型:segmentation/README.md。
引用我们
@inproceedings{wang2021crossformer,
title = {CrossFormer: A Versatile Vision Transformer Hinging on Cross-scale Attention},
author = {Wenxiao Wang and Lu Yao and Long Chen and Binbin Lin and Deng Cai and Xiaofei He and Wei Liu},
booktitle = {International Conference on Learning Representations, {ICLR}},
url = {https://openreview.net/forum?id=_PHymLIxuI},
year = {2022}
}
@article{wang2023crossformer++,
author = {Wenxiao Wang and Wei Chen and Qibo Qiu and Long Chen and Boxi Wu and Binbin Lin and Xiaofei He and Wei Liu},
title = {Crossformer++: A versatile vision transformer hinging on cross-scale attention},
journal = {{IEEE} Transactions on Pattern Analysis and Machine Intelligence, {TPAMI}},
year = {2023},
doi = {10.1109/TPAMI.2023.3341806},
}
致谢
本仓库部分代码参考了 Swin Transformer。











