
 访问官网
访问官网 Github
Github 文档
文档 论文
论文
LightGlue ⚡️
光速本地特征匹配
Philipp Lindenberger · Paul-Edouard Sarlin · Marc Pollefeys
ICCV 2023
论文 | Colab | 海报 | 训练你的模型!

LightGlue是一个深度神经网络,可以在图像对之间匹配稀疏本地特征。
一种自适应机制使其在处理简单图像对时更快(上图),并在处理困难图像对时降低计算复杂度(下图)。
此存储库托管了LightGlue的推理代码,这是一个轻量级的特征匹配器,具有高准确性和极快的推理速度。它将每个图像的一组关键点和描述符作为输入,并返回对应点的索引。其架构基于网络宽度和深度的自适应修剪技术—查看论文以获取更多详情。
我们发布了带有SuperPoint, DISK, ALIKED和SIFT本地特征预训练权重。 训练和评估代码可以在我们的库glue-factory中找到。
安装和演示 
使用pip安装这个仓库:
git clone https://github.com/cvg/LightGlue.git && cd LightGlue
python -m pip install -e .
我们提供了一个演示笔记本,展示了如何对图像对执行特征提取和匹配。
这是一个匹配两张图像的最简脚本:
from lightglue import LightGlue, SuperPoint, DISK, SIFT, ALIKED, DoGHardNet
from lightglue.utils import load_image, rbd
# SuperPoint+LightGlue
extractor = SuperPoint(max_num_keypoints=2048).eval().cuda() # 加载提取器
matcher = LightGlue(features='superpoint').eval().cuda() # 加载匹配器
# 或DISK+LightGlue, ALIKED+LightGlue或者SIFT+LightGlue
extractor = DISK(max_num_keypoints=2048).eval().cuda() # 加载提取器
matcher = LightGlue(features='disk').eval().cuda() # 加载匹配器
# 将每张图像加载为GPU上的torch.Tensor,形状为(3,H,W),归一化到[0,1]
image0 = load_image('path/to/image_0.jpg').cuda()
image1 = load_image('path/to/image_1.jpg').cuda()
# 提取本地特征
feats0 = extractor.extract(image0) # 自动调整图像大小,禁用可设置resize=None
feats1 = extractor.extract(image1)
# 匹配特征
matches01 = matcher({'image0': feats0, 'image1': feats1})
feats0, feats1, matches01 = [rbd(x) for x in [feats0, feats1, matches01]] # 删除批次维度
matches = matches01['matches'] # 形状为(K,2)的索引
points0 = feats0['keypoints'][matches[..., 0]] # 图像 #0中的坐标,形状为(K,2)
points1 = feats1['keypoints'][matches[..., 1]] # 图像 #1中的坐标,形状为(K,2)
我们还提供了一个匹配成对图像的简便方法:
from lightglue import match_pair
feats0, feats1, matches01 = match_pair(extractor, matcher, image0, image1)

LightGlue可以根据图像对调整其深度(层数)和宽度(关键点数量),对准确性的影响微乎其微。
高级配置
[所有参数的详细资料 - 点击展开]
n_layers: 堆叠的自关注+交叉关注层数。减少此值可以在提高推理速度的同时降低准确性(上图中的连续红线)。默认值:9层(所有层)。flash: 启用FlashAttention。显著增加速度并减少内存消耗,对准确性没有任何影响。默认值:True(LightGlue会自动检测FlashAttention是否可用)。mp: 启用混合精度推理。默认值:False(关闭)depth_confidence: 控制提前停止。值越低越早在早期层停止。默认值:0.95,禁用可设置为-1。width_confidence: 控制迭代点修剪。值越低越早修剪更多点。默认值:0.99,禁用可设置为-1。filter_threshold: 匹配置信度。增大此值以获得更少但更强的匹配。默认值:0.1
默认值提供了速度和准确性之间的良好权衡。要最大化准确性,请使用所有关键点并禁用自适应机制:
extractor = SuperPoint(max_num_keypoints=None)
matcher = LightGlue(features='superpoint', depth_confidence=-1, width_confidence=-1)
要在准确性小幅下降的情况下提高速度,请减少关键点数量并降低自适应阈值:
extractor = SuperPoint(max_num_keypoints=1024)
matcher = LightGlue(features='superpoint', depth_confidence=0.9, width_confidence=0.95)
最大速度通过以下组合获得:
- FlashAttention: 当
torch >= 2.0时自动使用或从源码安装。 - PyTorch编译,当
torch >= 2.0时可用:
matcher = matcher.eval().cuda()
matcher.compile(mode='reduce-overhead')
对于少于1536个关键点的输入(通过实验确定),这将编译LightGlue但禁用点修剪(较大开销)。对于更大输入尺寸,它会自动回退到急切模式并启用点修剪。自适应深度支持任何输入尺寸。
基准测试
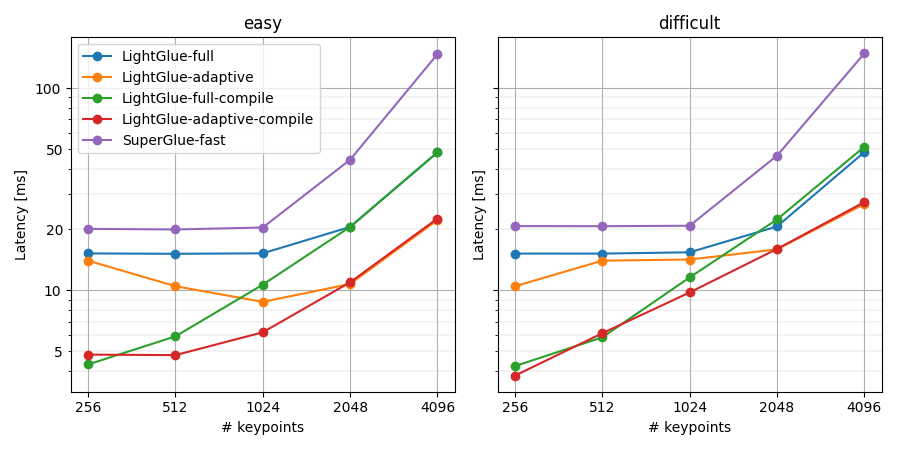
在GPU(RTX 3080)上的基准结果。通过编译和自适应,LightGlue在每图像1024个关键点时运行速度为每秒150帧,在4096个关键点时为每秒50帧。这比SuperGlue快了4-10倍。
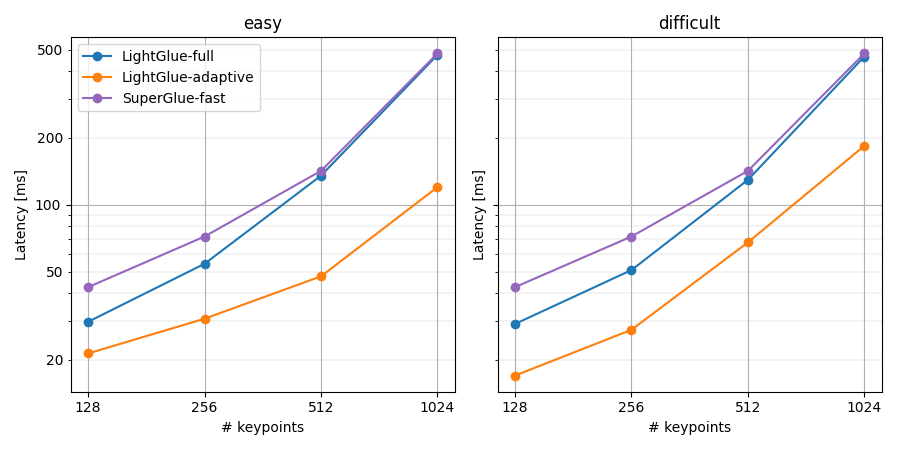
在CPU(Intel i7 10700K)上的基准结果。LightGlue在每图像512个关键点时运行速度为每秒20帧。
使用我们的基准脚本获取适合您的设置的相同图表:
python benchmark.py [--device cuda] [--add_superglue] [--num_keypoints 512 1024 2048 4096] [--compile]
[性能提示 - 点击展开]
注意: 点修剪引入的开销有时超过其益处。因此,仅在图像中关键点数多于N时启用点修剪,其中N是硬件相关的。 我们提供了针对当前硬件(RTX 30xx GPU)优化的默认值。 我们建议运行基准脚本并通过更新LightGlue.pruning_keypoint_thresholds['cuda']对您的硬件调整阈值。
训练和评估
使用Glue Factory,你可以用你自己的本地特征,在你的数据集上训练LightGlue!你还可以在标准基准如HPatches和MegaDepth上评估它和其他基准模型。
其他链接
- hloc - 视觉定位工具包: 使用LightGlue进行结构-从-运动和视觉定位。
- LightGlue-ONNX: 将LightGlue导出为开放神经网络交换(ONNX)格式,并支持TensorRT和OpenVINO。
- 图像匹配Web界面: 一个Web GUI,以轻松比较不同匹配器,包括LightGlue。
- kornia现已通过接口
LightGlue和LightGlueMatcher暴露LightGlue。
BibTeX引用
如果你使用了论文中的任何想法或本仓库中的代码,请考虑引用:
@inproceedings{lindenberger2023lightglue,
author = {Philipp Lindenberger and
Paul-Edouard Sarlin and
Marc Pollefeys},
title = {{LightGlue: Local Feature Matching at Light Speed}},
booktitle = {ICCV},
year = {2023}
}
许可证
LightGlue的预训练权重和本存储库中提供的代码均按Apache-2.0许可证发布。DISK也遵循此许可证,但SuperPoint遵循不同的、限制性许可证(包括其预训练权重及其推理文件)。ALIKED是遵循BSD-3-Clause许可证发布的。











