
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文"Mini-Gemini:挖掘多模态视觉语言模型潜力"官方代码库

该框架支持从2B到34B的一系列密集和混合专家大语言模型(LLMs),同时具备图像理解、推理和生成能力。我们基于LLaVA构建了这个代码库。
发布
- [05/03] 🔥 我们现已支持基于LLaMA3的模型!欢迎在这里尝试。
- [04/15] 🔥 Hugging Face演示已上线。这是13B-HD版本,欢迎观看和尝试。
- [03/28] 🔥 Mini-Gemini来啦!我们发布了论文、演示、代码、模型和数据!
目录
演示
我们在本节提供了一些精选示例。更多示例可以在我们的项目主页找到。欢迎试用我们的在线演示!

安装
请按照以下说明安装所需的软件包。
注意:如果您想使用2B版本,请确保安装最新版本的Transformers(>=4.38.0)。
- 克隆此仓库
git clone https://github.com/dvlab-research/MGM.git
- 安装软件包
conda create -n mgm python=3.10 -y
conda activate mgm
cd MGM
pip install --upgrade pip # 启用PEP 660支持
pip install -e .
- 为训练情况安装额外的软件包
pip install ninja
pip install flash-attn --no-build-isolation
模型
该框架在概念上很简单:使用双视觉编码器提供低分辨率视觉嵌入和高分辨率候选项; 提出了补丁信息挖掘来在高分辨率区域和低分辨率视觉查询之间进行补丁级挖掘; 利用LLM将文本与图像结合,同时实现理解和生成。
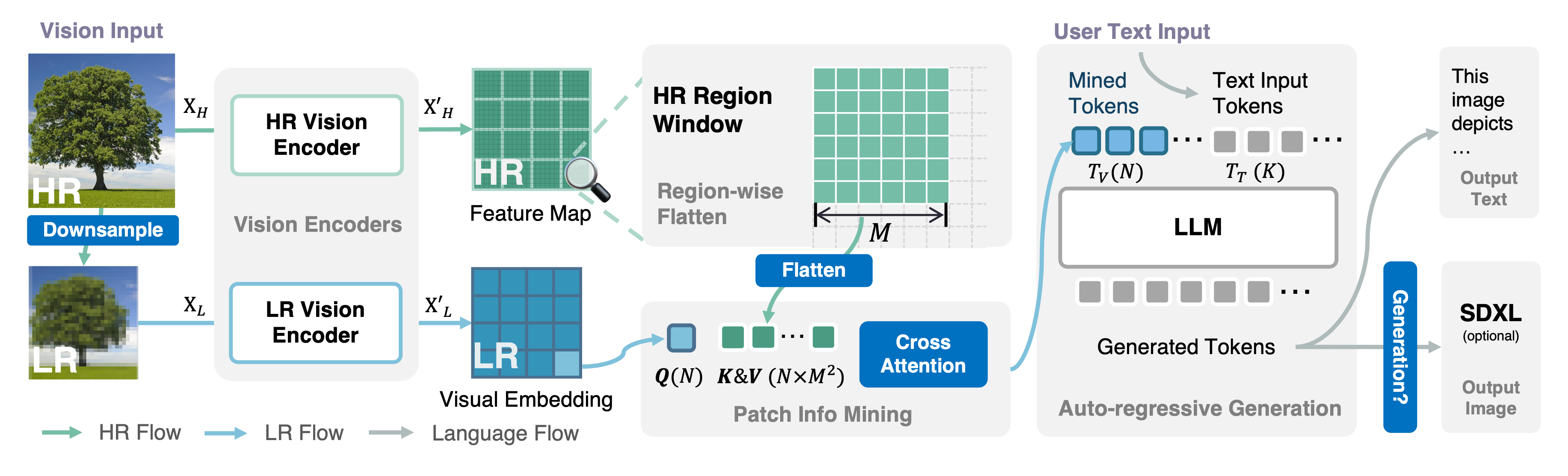
我们提供了在第1阶段和第2阶段数据上全面微调的所有模型:
| 模型 | 低分辨率 | 高分辨率 | 基础LLM | 视觉编码器 | 微调数据 | 微调计划 | 下载 |
|---|---|---|---|---|---|---|---|
| MGM-2B | 336 | 768 | Gemma-2B | CLIP-L | MGM-Instruct | full_ft-1e | ckpt |
| MGM-7B | 336 | 768 | Vicuna-7B-v1.5 | CLIP-L | MGM-Instruct | full_ft-1e | ckpt |
| MGM-13B | 336 | 768 | Vicuna-13B-v1.5 | CLIP-L | MGM-Instruct | full_ft-1e | ckpt |
| MGM-8B | 336 | 768 | LLaMA-3-8B-Instruct | CLIP-L | MGM-Instruct | full_ft-1e | ckpt |
| MGM-8x7B | 336 | 768 | Mixtral-8x7B-Instruct-v0.1 | CLIP-L | MGM-Instruct | full_ft-1e | ckpt |
| MGM-34B | 336 | 768 | Nous-Hermes-2-Yi-34B | CLIP-L | MGM-Instruct | full_ft-1e | ckpt |
| MGM-7B-HD | 672 | 1536 | Vicuna-7B-v1.5 | CLIP-L | MGM-Instruct | full_ft-1e | ckpt |
| MGM-13B-HD | 672 | 1536 | Vicuna-13B-v1.5 | CLIP-L | MGM-Instruct | full_ft-1e | ckpt |
| MGM-8B-HD | 672 | 1536 | LLaMA-3-8B-Instruct | CLIP-L | MGM-Instruct | full_ft-1e | ckpt |
| MGM-8x7B-HD | 672 | 1536 | Mixtral-8x7B-Instruct-v0.1 | CLIP-L | MGM-Instruct | full_ft-1e | ckpt |
| MGM-34B-HD | 672 | 1536 | Nous-Hermes-2-Yi-34B | CLIP-L | MGM-Instruct | full_ft-1e | ckpt |
| 以下是仅在第一阶段数据上预训练的权重: |
| 模型 | LR | HR | 基础语言模型 | 视觉编码器 | 预训练数据 | 微调计划 | 下载 |
|---|---|---|---|---|---|---|---|
| MGM-2B | 336 | 768 | Gemma-2B | CLIP-L | MGM-Pretrain | 1e | ckpt |
| MGM-7B | 336 | 768 | Vicuna-7B-v1.5 | CLIP-L | MGM-Pretrain | 1e | ckpt |
| MGM-13B | 336 | 768 | Vicuna-13B-v1.5 | CLIP-L | MGM-Pretrain | 1e | ckpt |
| MGM-8x7B | 336 | 768 | Mixtral-8x7B-Instruct-v0.1 | CLIP-L | MGM-Pretrain | 1e | ckpt |
| MGM-34B | 336 | 768 | Nous-Hermes-2-Yi-34B | CLIP-L | MGM-Pretrain | 1e | ckpt |
准备工作
数据集
我们提供了用于模型训练的处理好的数据。 对于模型预训练,请下载以下基于图像的训练数据并按以下方式组织:
-> 表示将数据放入本地文件夹。
- LLaVA Images ->
data/MGM-Pretrain/images,data/MGM-Finetune/llava/LLaVA-Pretrain/images - ALLaVA Caption ->
data/MGM-Pretrain/ALLaVA-4V
对于模型微调,请下载以下指令数据并按以下方式组织:
-> 表示将数据放入本地文件夹。
- COCO train2017 ->
data/MGM-Finetune/coco - GQA ->
data/MGM-Finetune/gqa - OCR-VQA (我们将所有文件保存为
.jpg) ->data/MGM-Finetune/ocr_vqa - TextVQA (不包含在训练中) ->
data/MGM-Finetune/textvqa - VisualGenome part1, VisualGenome part2 ->
data/MGM-Finetune/vg - ShareGPT4V-100K ->
data/MGM-Finetune/sam,share_textvqa,wikiart,web-celebrity,web-landmark - LAION GPT4V ->
data/MGM-Finetune/gpt4v-dataset - ALLaVA Instruction ->
data/MGM-Pretrain/ALLaVA-4V - DocVQA ->
data/MGM-Finetune/docvqa - ChartQA ->
data/MGM-Finetune/chartqa - DVQA ->
data/MGM-Finetune/dvqa - AI2D ->
data/MGM-Finetune/ai2d
对于模型评估,请按照此链接进行准备。我们使用一些额外的基准进行评估。请下载以下训练图像数据并按以下方式组织:
-> 表示将数据放入本地文件夹。
请按照结构将预训练数据、微调数据和评估数据分别放入 MGM-Pretrain、MGM-Finetune 和 MGM-Eval 子集中。
对于元信息,请下载以下文件并按结构中的方式组织它们。
| 数据文件名 | 大小 |
|---|---|
| mgm_pretrain.json | 1.68 G |
| mgm_instruction.json | 1.79 G |
| mgm_generation_pure_text.json | 0.04 G |
重要提示: mgm_generation_pure_text.json 是一个与生成相关的子集。不要将它与 mgm_instruction.json 合并,因为它已经包含在其中。您可以将此文件与自定义的 LLM/VLM SFT 数据集合并,以启用推理生成能力。
预训练权重
我们建议用户从以下链接下载预训练权重 CLIP-Vit-L-336, OpenCLIP-ConvNeXt-L, Gemma-2b-it, Vicuna-7b-v1.5, Vicuna-13b-v1.5, Mixtral-8x7B-Instruct-v0.1, 和 Nous-Hermes-2-Yi-34B,并按照结构将它们放入 model_zoo。
结构
在训练之前,文件夹结构应按如下方式组织。
MGM
├── mgm
├── scripts
├── work_dirs
│ ├── MGM
│ │ ├── MGM-2B
│ │ ├── ...
├── model_zoo
│ ├── LLM
│ │ ├── gemma
│ │ │ ├── gemma-2b-it
│ │ ├── vicuna
│ │ │ ├── 7B-V1.5
│ │ │ ├── 13B-V1.5
│ │ ├── llama-3
│ │ │ ├── Meta-Llama-3-8B-Instruct
│ │ │ ├── Meta-Llama-3-70B-Instruct
│ │ ├── mixtral
│ │ │ ├── Mixtral-8x7B-Instruct-v0.1
│ │ ├── Nous-Hermes-2-Yi-34B
│ ├── OpenAI
│ │ ├── clip-vit-large-patch14-336
│ │ ├── openclip-convnext-large-d-320-laion2B-s29B-b131K-ft-soup
├── data
│ ├── MGM-Pretrain
│ │ ├── mgm_pretrain.json
│ │ ├── images
│ │ ├── ALLaVA-4V
│ ├── MGM-Finetune
│ │ ├── mgm_instruction.json
│ │ ├── llava
│ │ ├── coco
│ │ ├── gqa
│ │ ├── ocr_vqa
│ │ ├── textvqa
│ │ ├── vg
│ │ ├── gpt4v-dataset
│ │ ├── sam
│ │ ├── share_textvqa
│ │ ├── wikiart
│ │ ├── web-celebrity
│ │ ├── web-landmark
│ │ ├── ALLaVA-4V
│ │ ├── docvqa
│ │ ├── chartqa
│ │ ├── dvqa
│ │ ├── ai2d
│ ├── MGM-Eval
│ │ ├── MMMU
│ │ ├── MMB
│ │ ├── MathVista
│ │ ├── ...
训练
训练过程包括两个阶段:(1)特征对齐阶段:桥接视觉和语言标记;(2)指令微调阶段:教导模型遵循多模态指令。
我们的模型在8张A100 GPU(80GB内存)上训练。如果使用更少的GPU,你可以减少per_device_train_batch_size并相应增加gradient_accumulation_steps。始终保持全局批量大小不变:per_device_train_batch_size x gradient_accumulation_steps x num_gpus。
在训练之前,请确保你已经按照准备工作下载并组织好数据。
注意:请为2台机器训练设置hostfile,为4台机器训练设置hostfile_4。
如果你想训练和微调该框架,请运行以下命令(针对图像尺寸为336的MGM-7B):
bash scripts/llama/train/stage_1_2_full_v7b_336_hr_768.sh
或者针对图像尺寸为336的MGM-13B:
bash scripts/llama/train/stage_1_2_full_v13b_336_hr_768.sh
由于我们重用了MGM-7B的预训练投影器权重,你可以直接使用图像尺寸为672的MGM-7B-HD进行第二阶段的指令微调:
bash scripts/llama/train/stage_2_full_v7b_672_hr_1536.sh
请在scripts/中查找更多关于gemma、llama、mixtral和yi的训练脚本。
评估
我们在几个基于图像的基准测试上进行评估。请按照准备工作下载评估数据,并按照结构中的方式组织它们。
| 模型 | LLM | 分辨率 | 链接 | TextVQA | MMB | MME | MM-Vet | MMMU_val | MMMU_test | MathVista |
|---|---|---|---|---|---|---|---|---|---|---|
| MGM-2B | Gemma-2B | 336 | ckpt | 56.2 | 59.8 | 1341/312 | 31.1 | 31.7 | 29.1 | 29.4 |
| MGM-7B | Vicuna-7B-v1.5 | 336 | ckpt | 65.2 | 69.3 | 1523/316 | 40.8 | 36.1 | 32.8 | 31.4 |
| MGM-13B | Vicuna-13B-v1.5 | 336 | ckpt | 65.9 | 68.5 | 1565/322 | 46.0 | 38.1 | 33.5 | 37.0 |
| MGM-8B | LLaMA-3-8B-Instruct | 336 | ckpt | 67.6 | 72.7 | 1606/341 | 47.3 | 38.2 | 36.3 | -- |
| MGM-8x7B | Mixtral-8x7B-Instruct-v0.1 | 336 | ckpt | 69.2 | 75.6 | 1639/379 | 45.8 | 41.8 | 37.1 | 41.8 |
| MGM-34B | Nous-Hermes-2-Yi-34B | 336 | ckpt | 70.1 | 79.6 | 1666/439 | 53.0 | 48.7 | 43.6 | 38.9 |
| MGM-7B-HD | Vicuna-7B-v1.5 | 672 | ckpt | 68.4 | 65.8 | 1546/319 | 41.3 | 36.8 | 32.9 | 32.2 |
| MGM-13B-HD | Vicuna-13B-v1.5 | 672 | ckpt | 70.2 | 68.6 | 1597/320 | 50.5 | 37.3 | 35.1 | 37.0 |
| MGM-8B-HD | LLaMA-3-8B-Instruct | 672 | ckpt | 71.6 | -- | 1532/357 | -- | 37.0 | -- | -- |
| MGM-8x7B-HD | Mixtral-8x7B-Instruct-v0.1 | 672 | ckpt | 71.9 | 74.7 | 1633/356 | 53.5 | 40.0 | 37.0 | 43.1 |
| MGM-34B-HD | Nous-Hermes-2-Yi-34B | 672 | ckpt | 74.1 | 80.6 | 1659/482 | 59.3 | 48.0 | 44.9 | 43.3 |
如果你想在基于图像的基准测试上评估模型,请使用scripts/MODEL_PATH/eval中的脚本。
例如,使用MGM-7B-HD运行以下命令进行TextVQA评估:
bash scripts/llama/eval/textvqa.sh
请在scripts/MODEL_PATH中查找更多评估脚本。
命令行界面推理
无需Gradio界面即可与图像进行对话。它还支持多GPU、4位和8位量化推理。使用4位量化。 请确保你已安装diffusers和PaddleOCR(仅用于更好的OCR体验),然后尝试以下命令进行图像和生成推理:
python -m mgm.serve.cli \
--model-path work_dirs/MGM/MGM-13B-HD \
--image-file <你的图像路径>
或者尝试使用OCR获得更好的体验(确保您已安装 PaddleOCR):
python -m mgm.serve.cli \
--model-path work_dirs/MGM/MGM-13B-HD \
--image-file <您的图像路径> \
--ocr
或者尝试使用生成进行推理(确保您已安装 diffusers):
python -m mgm.serve.cli \
--model-path work_dirs/MGM/MGM-13B-HD \
--image-file <您的图像路径> \
--gen
您还可以尝试使用8位甚至4位进行高效推理
python -m mgm.serve.cli \
--model-path work_dirs/MGM/MGM-13B-HD \
--image-file <您的图像路径> \
--gen
--load-8bit
Gradio Web 界面
在这里,我们采用类似于LLaVA的Gradio界面,为我们的模型提供一个用户友好的界面。 要在本地启动Gradio演示,请逐个运行以下命令。如果您计划启动多个模型工作器以比较不同的检查点,您只需要启动控制器和Web服务器一次。
启动控制器
python -m mgm.serve.controller --host 0.0.0.0 --port 10000
启动Gradio Web服务器
python -m mgm.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reload
您刚刚启动了Gradio Web界面。现在,您可以使用屏幕上打印的URL打开Web界面。您可能会注意到模型列表中没有模型。不用担心,因为我们还没有启动任何模型工作器。当您启动模型工作器时,它将自动更新。
启动模型工作器
这是在GPU上执行推理的实际"工作器"。每个工作器负责由--model-path指定的单个模型。
python -m mgm.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path work_dirs/MGM/MGM-13B-HD
等待进程完成加载模型,直到看到"Uvicorn running on ..."。现在,刷新您的Gradio Web界面,您将在模型列表中看到刚刚启动的模型。
您可以启动任意数量的工作器,并在同一个Gradio界面中比较不同的模型。请保持--controller相同,并为每个工作器修改--port和--worker为不同的端口号。
python -m mgm.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port <不同于40000,比如40001> --worker http://localhost:<相应更改,即40001> --model-path work_dirs/MGM/MGM-34B-HD
如果您使用的是带有M1或M2芯片的Apple设备,可以通过使用--device标志来指定mps设备:--device mps。
启动模型工作器(多GPU,当GPU VRAM <= 24GB时)
如果您的GPU VRAM小于24GB(例如,RTX 3090,RTX 4090等),您可以尝试使用多个GPU运行。我们最新的代码库将在您有多个GPU的情况下自动尝试使用多个GPU。您可以使用CUDA_VISIBLE_DEVICES指定要使用的GPU。以下是使用前两个GPU运行的示例。
CUDA_VISIBLE_DEVICES=0,1 python -m mgm.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path work_dirs/MGM/MGM-13B-HD
启动模型工作器(4位,8位推理,量化)
您可以使用量化位(4位,8位)启动模型工作器,这允许您以减少的GPU内存占用进行推理。请注意,使用量化位进行推理可能不如全精度模型准确。只需在您执行的模型工作器命令中添加--load-4bit或--load-8bit。以下是使用4位量化运行的示例。
python -m mgm.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path work_dirs/MGM/MGM-13B-HD --load-4bit
示例
我们在本节提供一些示例。更多示例可以在我们的项目页面找到。
高分辨率理解

推理生成

引用
如果您发现这个仓库对您的研究有用,请考虑引用以下论文
@article{li2024mgm,
title={Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models},
author={Li, Yanwei and Zhang, Yuechen and Wang, Chengyao and Zhong, Zhisheng and Chen, Yixin and Chu, Ruihang and Liu, Shaoteng and Jia, Jiaya},
journal={arXiv:2403.18814},
year={2023}
}
致谢
本项目与Google LLC无关。
我们要感谢以下仓库的出色工作:
- 本工作基于LLaVA构建。
- 本工作使用了来自Gemma、Vicuna、Mixtral和Nous-Hermes的LLM。
许可证


数据和检查点仅用于研究目的,并获得许可。它们也仅限于遵守LLaVA、LLaMA、Vicuna和GPT-4许可协议的用途。数据集采用CC BY NC 4.0许可(仅允许非商业用途),使用该数据集训练的模型不应用于研究目的以外的用途。











