
 访问官网
访问官网 Github
Github 文档
文档最近邻基准测试

在高维空间中快速搜索最近邻是一个日益重要的问题,但至今很少有客观比较各种方法的实证尝试,尽管这种比较对推动优化进展至关重要。
本项目包含了用于对特定度量标准的各种近似最近邻(ANN)搜索实现进行基准测试的工具。我们已经预先生成了数据集(HDF5格式),并为每种算法准备了Docker容器,以及用于验证功能完整性的测试套件。
已评估
- Annoy
- FLANN
- scikit-learn:LSHForest、KDTree、BallTree
- Weaviate
- PANNS
- NearPy
- KGraph
- NMSLIB(非度量空间库)
:SWGraph、HNSW、BallTree、MPLSH
- hnswlib(nmslib项目的一部分)
- RPForest
- FAISS
- DolphinnPy
- Datasketch
- nndescent
- PyNNDescent
- MRPT
- NGT
:ONNG、PANNG、QG
- SPTAG
- PUFFINN
- N2
- ScaNN
- Vearch
- Elasticsearch
:HNSW
- Elastiknn
- ExpANN
- OpenSearch KNN
- DiskANN
:Vamana、Vamana-PQ
- Vespa
- scipy:cKDTree
- vald
- Qdrant
- 华为(qsgngt)
- Milvus
: Knowhere
- Zilliz(Glass)
- pgvector
- pgvecto.rs
- RediSearch
- 笛卡尔(01AI)
- kgn 数据集 =========




























我们提供了多个以HDF5格式预计算的数据集。所有数据集都已预先分割为训练集和测试集,并包含前100个最近邻的真实数据。
| 数据集 | 维度 | 训练集大小 | 测试集大小 | 邻居数 | 距离 | 下载 |
|---|---|---|---|---|---|---|
| DEEP1B | 96 | 9,990,000 | 10,000 | 100 | 角度 | HDF5 (3.6GB) |
| Fashion-MNIST | 784 | 60,000 | 10,000 | 100 | 欧几里得 | HDF5 (217MB) |
| GIST | 960 | 1,000,000 | 1,000 | 100 | 欧几里得 | HDF5 (3.6GB) |
| GloVe | 25 | 1,183,514 | 10,000 | 100 | 角度 | HDF5 (121MB) |
| GloVe | 50 | 1,183,514 | 10,000 | 100 | 角度 | HDF5 (235MB) |
| GloVe | 100 | 1,183,514 | 10,000 | 100 | 角度 | HDF5 (463MB) |
| GloVe | 200 | 1,183,514 | 10,000 | 100 | 角度 | HDF5 (918MB) |
| Kosarak | 27,983 | 74,962 | 500 | 100 | Jaccard | HDF5 (33MB) |
| MNIST | 784 | 60,000 | 10,000 | 100 | 欧几里得 | HDF5 (217MB) |
| MovieLens-10M | 65,134 | 69,363 | 500 | 100 | Jaccard | HDF5 (63MB) |
| NYTimes | 256 | 290,000 | 10,000 | 100 | 角度 | HDF5 (301MB) |
| SIFT | 128 | 1,000,000 | 10,000 | 100 | 欧几里得 | HDF5 (501MB) |
| Last.fm | 65 | 292,385 | 50,000 | 100 | 角度 | HDF5 (135MB) |
结果
以下结果均截至2023年4月,在AWS的r6i.16xlarge机器上运行所有基准测试,使用参数--parallelism 31并禁用超线程。所有基准测试都是单CPU运行。
glove-100-angular
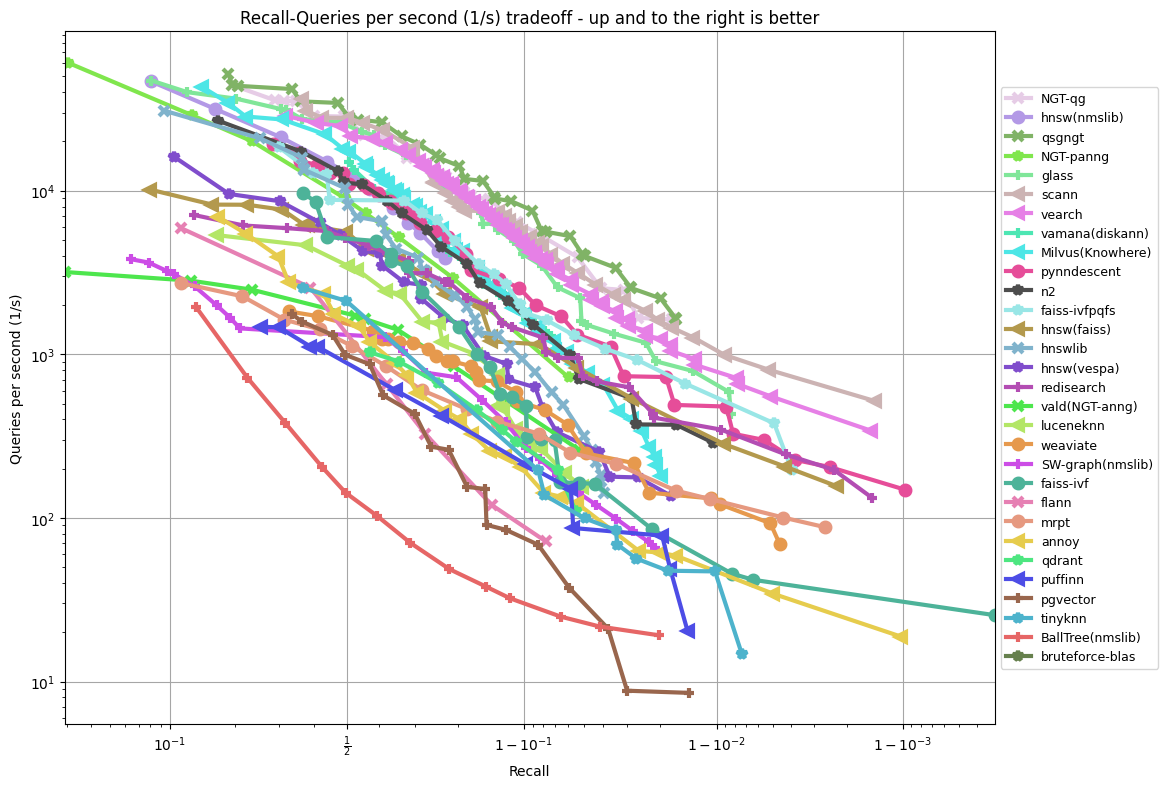
sift-128-euclidean
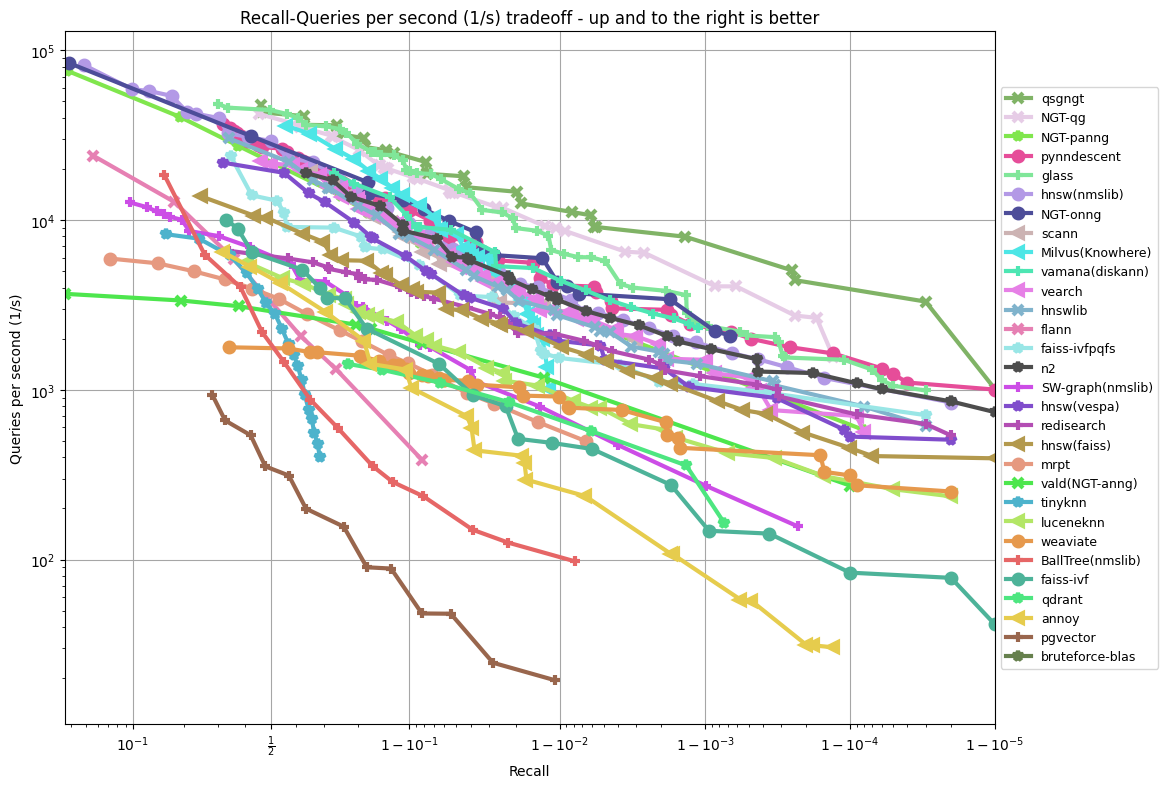
fashion-mnist-784-euclidean

nytimes-256-angular
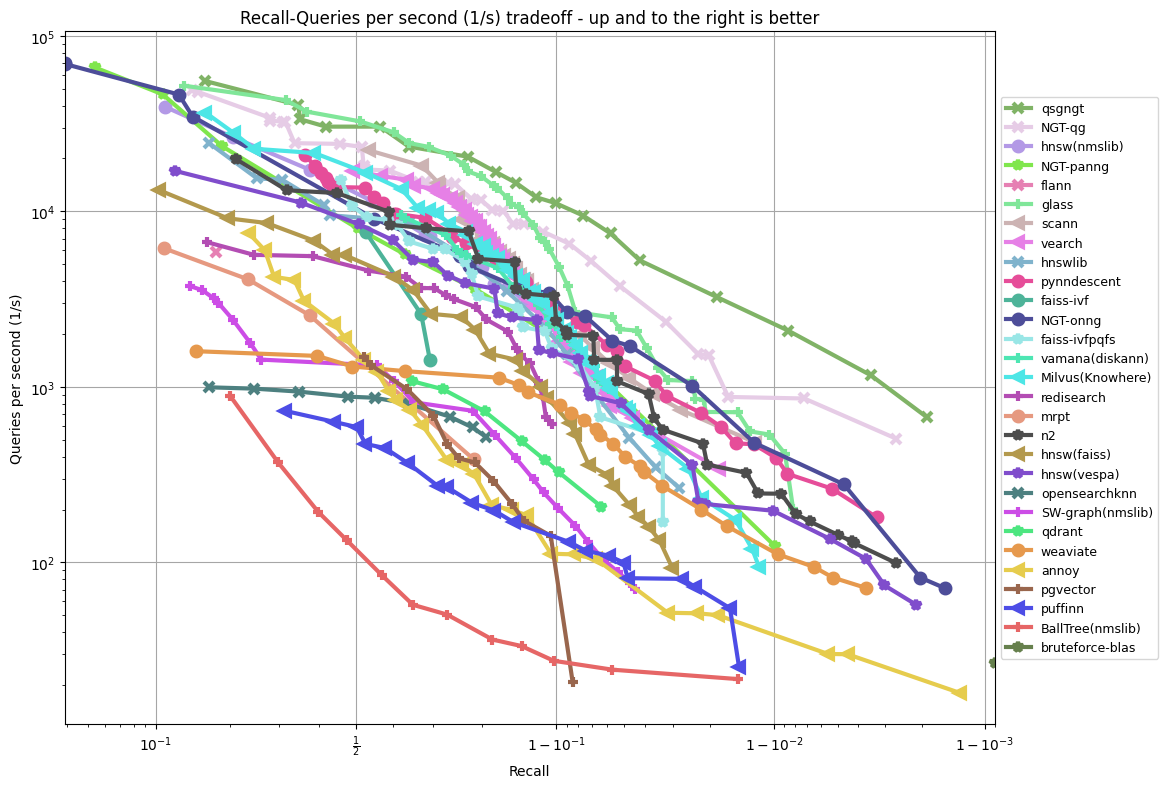
gist-960-euclidean
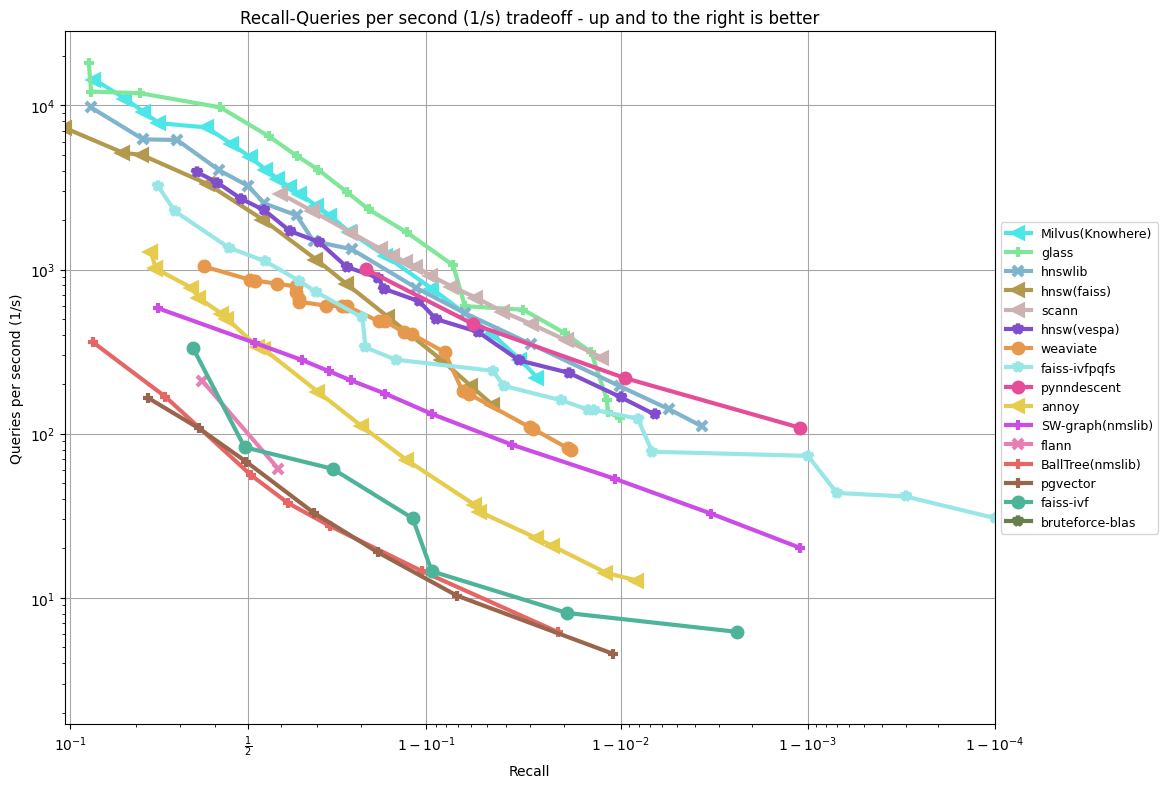
glove-25-angular
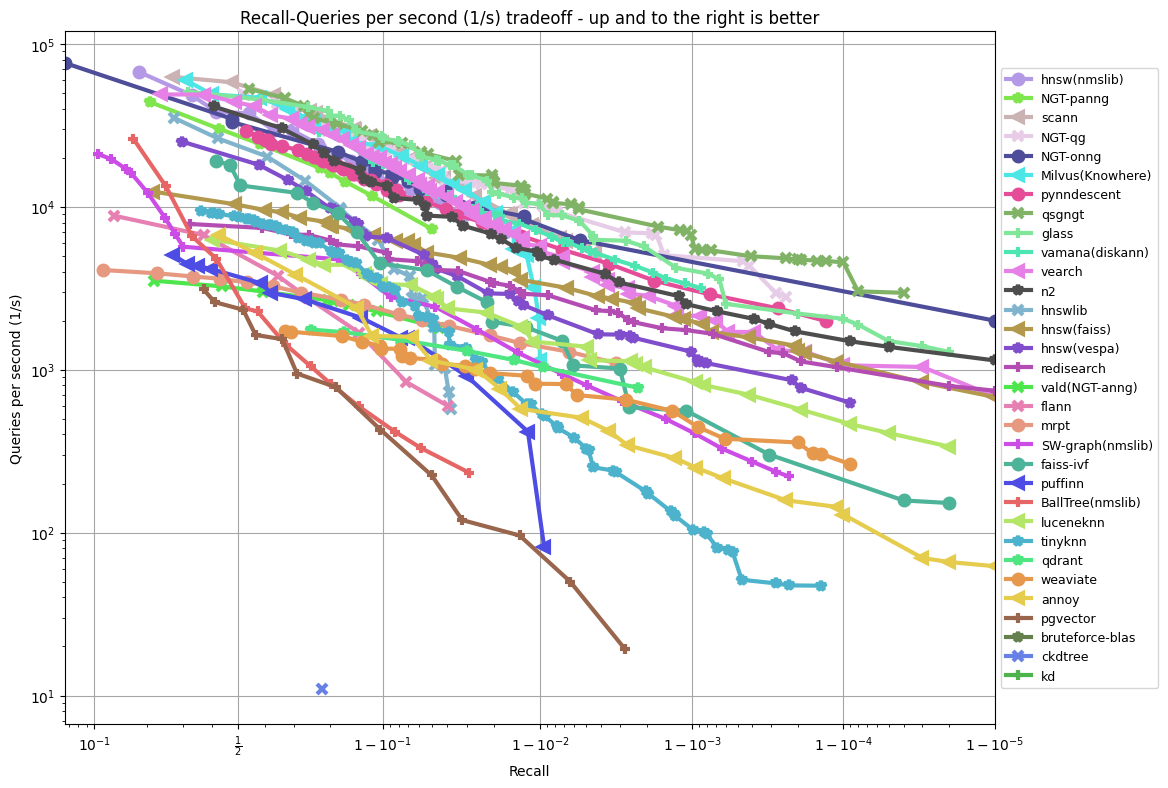
待办:更新http://ann-benchmarks.com上的图表。
安装
唯一的前提条件是Python(已测试3.10.6版本)和Docker。
- 克隆仓库。
- 运行
pip install -r requirements.txt。 - 运行
python install.py以在Docker容器内构建所有库(这可能需要一段时间,大约10-30分钟)。
运行
- 运行
python run.py(这可能需要极长时间,可能会持续数天) - 运行
python plot.py或python create_website.py来绘制结果。 - 运行
python data_export.py --out res.csv将所有结果导出到csv文件中,以便进行额外的后处理。
你可以按以下方式自定义算法和数据集:
- 检查
ann_benchmarks/algorithms/{YOUR_IMPLEMENTATION}/config.yml是否包含你想要测试的参数设置 - 要在SIFT上运行实验,请执行
python run.py --dataset glove-100-angular。有关可能的设置的更多信息,请参见python run.py --help。请注意,实验可能需要很长时间。 - 要处理结果,可以使用
python plot.py --dataset glove-100-angular或python create_website.py。示例调用:python create_website.py --plottype recall/time --latex --scatter --outputdir website/。
包含你的算法
通过提供以下内容,将你的算法添加到ann_benchmarks/algorithms/{YOUR_IMPLEMENTATION}/文件夹中:
- 一个名为
module.py的小型Python封装 - 一个名为
Dockerfile的Dockerfile - 一组在
config.yml中的超参数 - 通过将你的实现添加到
.github/workflows/benchmarks.yml来运行CI测试
查看可用实现以获取灵感。
原则
- 欢迎所有人提交拉取请求,对每个库的使用方式进行调整和修改。
- 特别是:如果你是这些库中任何一个的作者,并且认为可以改进基准测试,请考虑进行改进并提交拉取请求。
- 这是一个持续进行的项目,旨在反映当前状态。
- 使所有内容易于复制,包括安装和准备数据集。
- 尝试每个库的多个不同参数值,忽略不在精度-性能前沿的点。
- 高维数据集,维度约为100-1000。这既具有挑战性,又符合实际情况。不超过1000维,因为这些问题可能应该通过单独进行降维来解决。
- 默认使用单一查询。ANN-Benchmarks 确保在实验过程中只饱和一个 CPU,即不进行多线程处理。提供了一种批处理模式,可以一次性向实现提供所有查询。在
run.py和plot.py中添加--batch标志以启用批处理模式。 - 避免极其昂贵的索引构建(超过几个小时)。
- 专注于适合 RAM 的数据集。对于十亿级基准测试,请参见相关的 big-ann-benchmarks 项目。
- 我们主要支持基于 CPU 的 ANN 算法。FAISS 存在 GPU 支持,但必须在本地编译 GPU 支持,并且必须使用
--local --batch标志运行实验。 - 对索引数据和查询点进行适当的训练/测试集划分。
- 请注意,我们认为集合相似度数据集是稀疏的,因此我们向算法传递一个已排序的整数数组来表示每个用户的集合。
作者
由 Erik Bernhardsson 构建,Martin Aumüller 和 Alexander Faithfull 做出了重要贡献。
相关出版物
基准测试框架背后的设计原则在以下出版物中有所描述:
- M. Aumüller, E. Bernhardsson, A. Faithfull: ANN-Benchmarks: 近似最近邻算法的基准测试工具。Information Systems 2019. DOI: 10.1016/j.is.2019.02.006
- M. Aumüller, E. Bernhardsson, A. Faithfull: ANN-Benchmarks 的可复现性协议:近似最近邻搜索算法的基准测试工具,成果。
相关项目
- big-ann-benchmarks 是一项针对十亿级近似最近邻搜索的基准测试工作,作为 NeurIPS'21 竞赛赛道 的一部分。











