访问官网
访问官网 Github
Github 文档
文档

注意 重要:pomegranate v1.0.0 是从头开始重写的,使用 PyTorch 作为计算后端而不是 Cython。虽然支持相同的功能,但API有显著不同。请查看教程和示例文件夹以帮助重写您的代码。
ReadTheDocs | Tutorials | Examples
pomegranate 是一个概率建模库,其模块化实现方式和将所有模型视为概率分布的处理方式定义了它。模块化实现允许用户轻松地将正态分布放入混合模型中以创建高斯混合模型,就像将伽马分布和泊松分布放入混合模型中以创建异质混合模型一样容易。但这还不是全部!因为每个模型都被视为概率分布,贝叶斯网络可以像正态分布一样容易地被放入混合模型中,隐马尔科夫模型可以被放入贝叶斯分类器中以对序列进行分类。这两种设计选择共同提供了一种在任何其他概率建模包中都看不到的灵活性。
最近,pomegranate(v1.0.0)从头开始用 PyTorch 重写,以取代过时的 Cython 后端。这个重写让我有机会修复许多我作为初级软件工程师时所做的糟糕设计选择。不幸的是,这些变化与以前版本不兼容,会扰乱工作流程。另一方面,这些变化显著加快了大多数方法,改进并简化了代码,修复了社区多年来提出的许多问题,并使贡献变得更加容易。我在下面写了更多内容,但你来到这里可能是因为你的代码坏了,这是简短的总结。
特别感谢 NumFOCUS 通过特别的开发资助支持这项工作。
安装
pip install pomegranate
如果你需要重写前的最后一个 Cython 版本,请使用 pip install pomegranate==0.14.8。你可能需要手动安装 Cython 3 之前的版本。
为什么要重写?
这次重写主要出于四个原因:
- 速度:原生 PyTorch 通常比我手工调优的 Cython 代码快得多。
- 特性:PyTorch 有许多特性,如序列化、混合精度和 GPU 支持,现在可以直接用于 pomegranate,而无需我额外工作。
- 社区贡献:许多人在使用 pomegranate 时面临的一个挑战是他们无法修改或扩展它,因为他们不知道 Cython。即使他们知道 Cython,每次尝试添加新功能或修复错误或发布新版本时我都会感受到痛苦。使用 PyTorch 作为后端显著减少了添加新功能所需的工作量。
- 互操作性:像 PyTorch 这样的库不仅提供了利用其计算后端的宝贵机会,还能更好地与现有资源和社区集成。这次重写将使人们更容易将概率模型与神经网络作为损失、约束和结构正则化,以及与其他基于 PyTorch 的项目集成。
高层次改变
- 通用
- 整个代码库已用 PyTorch 重写,所有模型都是
torch.nn.Module的实例 - 这个代码库被一个包含超过 800 个单元测试的全面套件检查,这些测试调用断言语句几千次,比以前版本多得多。
- 安装问题现在可能来自 PyTorch,它有无数的资源可以帮助解决。
- 特性
- 所有模型现在都支持 GPU
- 所有模型现在支持半精度/混合精度
- 序列化现在由 PyTorch 处理,产生更紧凑和高效的 I/O
- 通过
torch.masked.MaskedTensor对象现在支持缺失值 - 先验概率现在可以传递给所有相关模型和方法,比以前更全面/灵活的半监督学习
- 模型
- 所有分布现在默认是多元的,并独立对待每个特征(除正态分布外)
- 名称中已删除“分布”,例如,
NormalDistribution现在是Normal FactorGraph现在得到一流公民的支持,具有所有预测和训练方法- 隐马尔科夫模型已分为
DenseHMM和SparseHMM模型,这些模型在编码过渡矩阵的方式上有所不同,DenseHMM对象在真正稠密的图上显著更快
- 区别
NaiveBayes已被永久删除,因为它与BayesClassifier冗余MarkovNetwork尚未实现- 贝叶斯网络的约束图和约束结构学习尚未实现
- 隐马尔科夫模型的静默状态尚未实现
- 隐马尔科夫模型的 Viterbi 尚未实现
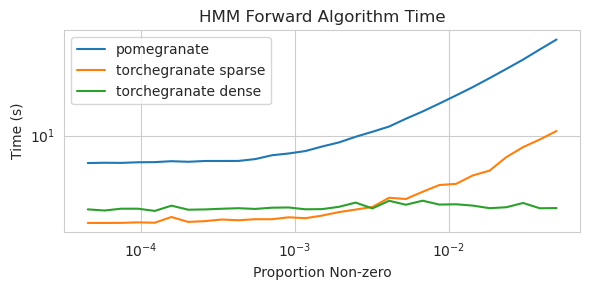
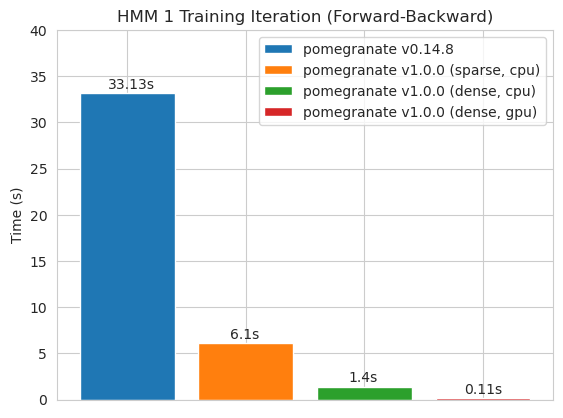
速度
pomegranate v1.0.0 中的大多数模型和方法比以前版本中的对应部分要快。这通常随着复杂度的增加而扩展,对于小数据集上的简单分布,只会看到小幅提速,但对于大数据集上的复杂模型(例如隐马尔科夫模型训练或贝叶斯网络推断)则会有更大的提速。目前显著的例外是贝叶斯网络结构学习,除了 Chow-Liu 树构建外,仍然不完整且速度不快。在下面的示例中,torchegranate 指的是用来开发 pomegranate v1.0.0 的临时仓库,pomegranate 指的是 pomegranate v0.14.8。
K均值
谁知道这里发生了什么?真是太疯狂了。

隐马尔科夫模型
稠密过渡矩阵(CPU)
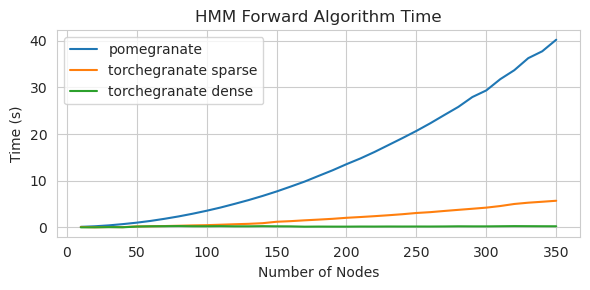
稀疏过渡矩阵(CPU)
训练具有 125 个节点模型的稠密过渡矩阵
贝叶斯网络
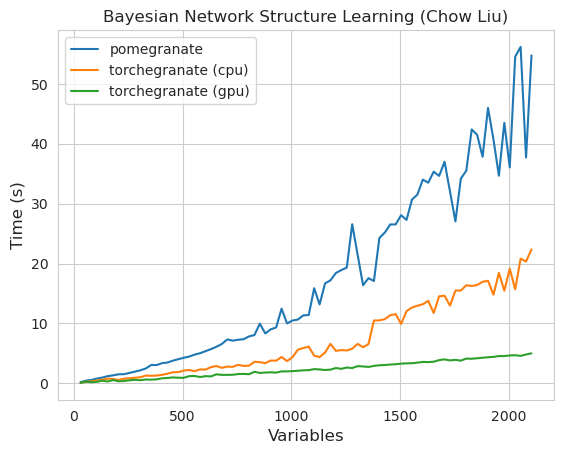
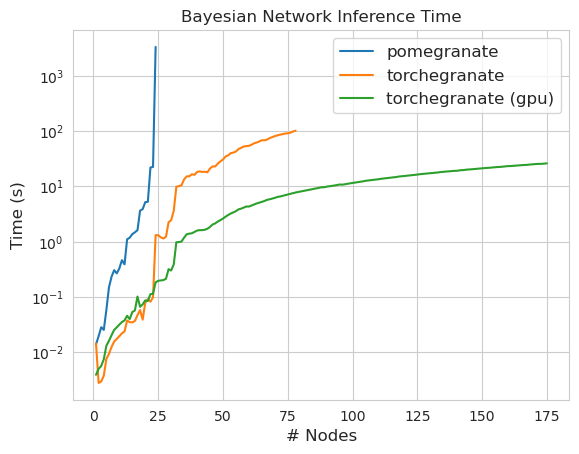
特性
注意 请查看 教程 文件夹以获取代码示例。 切换从Cython后端到PyTorch后端已经启用了或扩展了大量功能。因为重写是一个PyTorch的薄包装,当PyTorch发布新功能时,它们可以应用到pomegranate模型中,而不需要我的新版本发布。
GPU支持
现在pomegranate中的所有分布和方法都支持GPU。由于每个分布都是一个torch.nn.Module对象,用法和其他用PyTorch编写的代码相同。这意味着模型和数据都必须由用户移动到GPU。例如:
>>> X = torch.exp(torch.randn(50, 4))
# 将在CPU上执行
>>> d = Exponential().fit(X)
>>> d.scales
Parameter containing:
tensor([1.8627, 1.3132, 1.7187, 1.4957])
# 将在GPU上执行
>>> d = Exponential().cuda().fit(X.cuda())
>>> d.scales
Parameter containing:
tensor([1.8627, 1.3132, 1.7187, 1.4957], device='cuda:0')
同样,所有模型都是分布,因此可以类似地在GPU上使用。当模型被移动到GPU时,与之关联的所有模型(例如分布)也会被移动到GPU。
>>> X = torch.exp(torch.randn(50, 4)).cuda()
>>> model = GeneralMixtureModel([Exponential(), Exponential()]).cuda()
>>> model.fit(X)
[1] Improvement: 1.26068115234375, Time: 0.001134s
[2] Improvement: 0.168121337890625, Time: 0.001097s
[3] Improvement: 0.037841796875, Time: 0.001095s
>>> model.distributions[0].scales
Parameter containing:
>>> model.distributions[1].scales
tensor([0.9141, 1.0835, 2.7503, 2.2475], device='cuda:0')
Parameter containing:
tensor([1.9902, 2.3871, 0.8984, 1.2215], device='cuda:0')
混合精度
从理论上讲,pomegranate模型可以像其他PyTorch模块一样在混合或低精度模式下运行。然而,由于pomegranate使用的操作比大多数神经网络更复杂,这在实际中有时不起作用或无帮助,因为这些操作尚未在低精度模式下进行优化或实现。所以,希望这个功能随着时间的推移会变得更有用。
>>> X = torch.randn(100, 4)
>>> d = Normal(covariance_type='diag')
>>>
>>> with torch.autocast('cuda', dtype=torch.bfloat16):
>>> d.fit(X)
序列化
pomegranate分布都是torch.nn.Module的实例,因此序列化与任何其他PyTorch模型相同。
保存:
>>> X = torch.exp(torch.randn(50, 4)).cuda()
>>> model = GeneralMixtureModel([Exponential(), Exponential()], verbose=True)
>>> model.cuda()
>>> model.fit(X)
>>> torch.save(model, "test.torch")
加载:
>>> model = torch.load("test.torch")
torch.compile
注释
torch.compile正由PyTorch团队积极开发中,可能迅速改进。目前,在初始化模型时你可能需要传入check_data=False以避免一个兼容性问题。
在PyTorch v2.0.0中,torch.compile被引入,作为一个围绕工具的灵活包装,它可以将操作融合在一起,使用CUDA图表,并试图消除GPU执行中的I/O瓶颈。因为这些瓶颈在许多pomegranate用户面临的小到中等规模的数据设置中可能非常显著,因此torch.compile似乎将非常有价值。与其针对整个模型,这主要只是编译forward方法,你应该编译对象的各个方法。
# 如常创建你的对象
>>> mu = torch.exp(torch.randn(100))
>>> d = Exponential(mu).cuda()
# 创建一些数据
>>> X = torch.exp(torch.randn(1000, 100))
>>> d.log_probability(X)
# 编译`log_probability`方法!
>>> d.log_probability = torch.compile(d.log_probability, mode='reduce-overhead', fullgraph=True)
>>> d.log_probability(X)
不幸的是,我在当方法以嵌套方式调用时,即在混合模型中编译predict方法时遇到了一些困难,在内部,它调用每个分布的log_probability方法。我已经尝试以一种避免其中一些错误的方式组织代码,但由于当前的错误消息不明,我遇到了一些困难。
缺失值
pomegranate通过torch.masked.MaskedTensor对象支持处理包含缺失值的数据。简单来说,只需要在缺失值上放一个掩码。
>>> X = <your tensor with NaN for the missing values>
>>> mask = ~torch.isnan(X)
>>> X_masked = torch.masked.MaskedTensor(X, mask=mask)
>>> d = Normal(covariance_type='diag').fit(X_masked)
>>> d.means
Parameter containing:
tensor([0.2271, 0.0290, 0.0763, 0.0135])
目前所有算法都将缺失当作忽略的内容。例如,当计算包含缺失值的列的均值时,均值将仅是现有值的平均值。缺失值不会被填补,因为不当的填补可能会对数据造成偏差,产生扭曲分布的不可能的估计,并缩小方差。
因为并不是所有操作都适用于MaskedTensors,目前以下分布不支持缺失值:Bernoulli,categorical,full covariance的normal,均匀分布
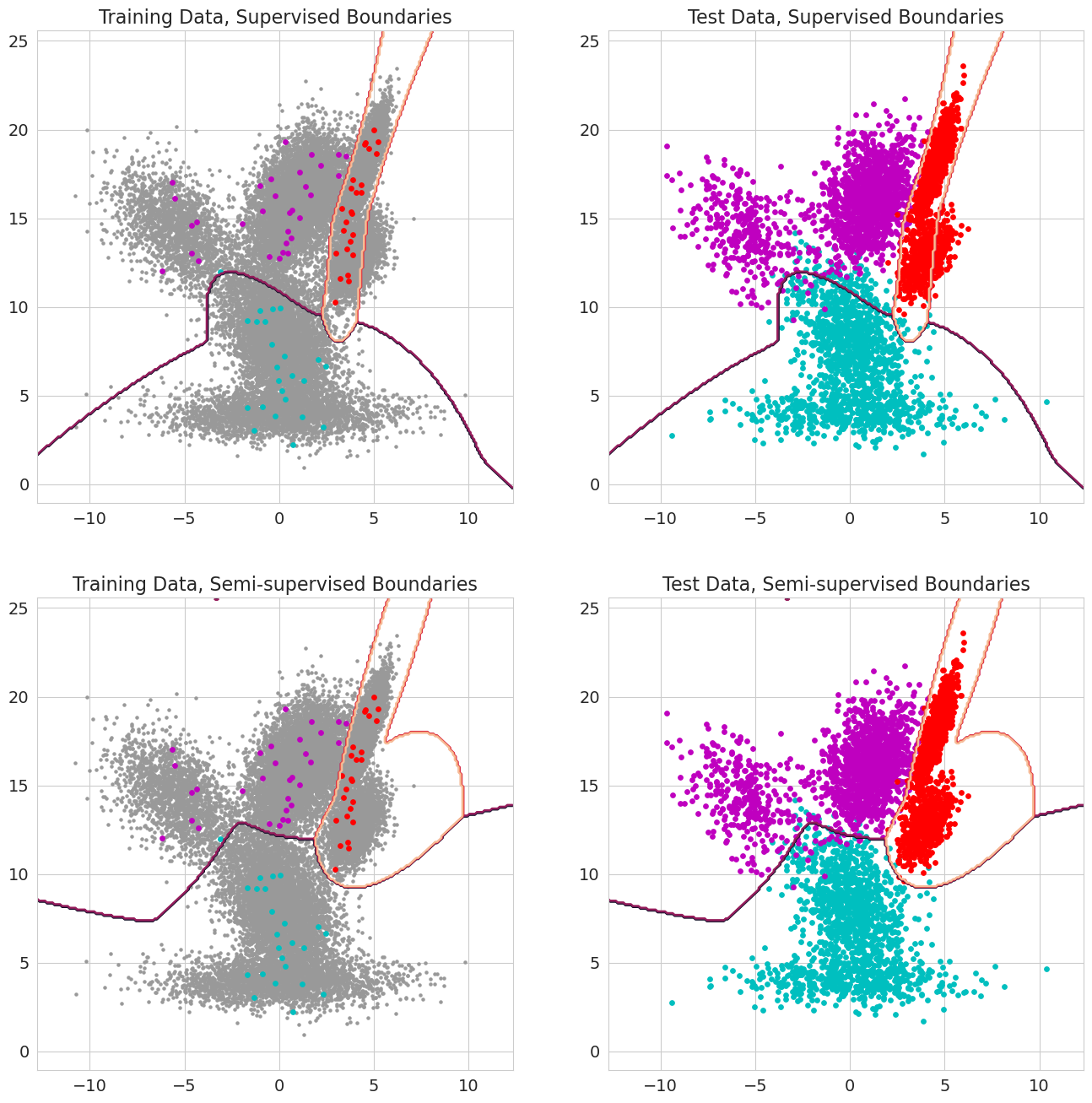
先验概率和半监督学习
pomegranate v1.0.0的一个新功能是在混合模型、贝叶斯分类器和隐马尔可夫模型中传入每个观测的先验概率。这些是观测在评估似然之前属于模型某个组件的先验概率,应在0到1之间。当这些值包括某个观测的1.0时,它被视为标签,因为在将该观测分配到某个状态时似然不再重要。因此,当每个观测对某个状态具有1.0时,可以使用这些先验概率进行有标签训练,包含部分标记序列的观测子集时进行半监督学习,或者当值在0和1之间时进行更复杂的加权形式。