
 Github
Github 文档
文档 论文
论文偏差因子化的、基于分辨率的深度学习模型揭示了染色质可及性的顺式调控序列语法、转录因子足迹和调控变异
- 这个代码库包含了论文《偏差因子化的、基于分辨率的深度学习模型揭示了染色质可及性的顺式调控序列语法、转录因子足迹和调控变异》(技术报告即将发布)的代码,作者为 Anusri Pampari*、Anna Shcherbina*和Anshul Kundaje。(*作者贡献相同)
- 如有建议和评论,请联系[Anusri Pampari] (<名字>@stanford.edu)。
- 这里是幻灯片、ISMB演讲和全面的教程链接。如有问题,请查看FAQ并提交github issue。
- 如果您使用的是chrombpnet <= v0.1.3版本,请参阅此处的说明 - https://github.com/kundajelab/chrombpnet/wiki/Denovo-motif-discovery
- 如果您正在项目中积极使用chrombpnet仓库,我强烈建议您将自己添加到观察者列表中以获取更新。点击眼睛符号(星号下方,右侧叉号上方)。这将使您了解该仓库的所有主要更新和错误报告。
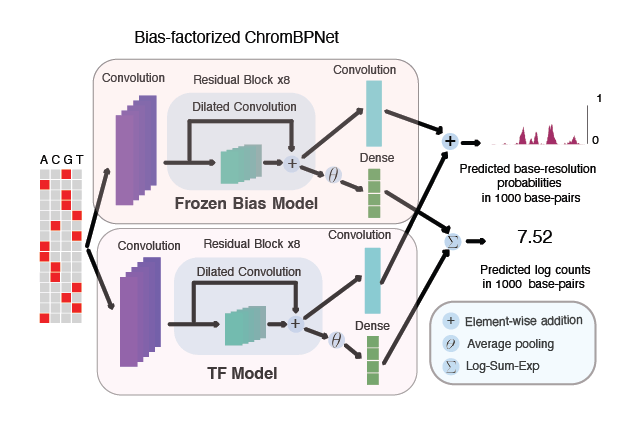
染色质谱(DNASE-seq和ATAC-seq)呈现出由转录因子(TF)协同结合调控的多分辨率形状和跨度。由于这些实验中使用的酶(DNASE-I/Tn5)产生的混杂偏差,这种复杂性更难以挖掘。现有方法无法在基础分辨率上考虑这种复杂性,也无法正确考虑酶偏差,因此错过了这些谱图的高分辨率结构。在此我们介绍ChromBPNet来解决这两个方面的问题。
ChromBPNet(图中显示为偏差因子化ChromBPNet)是一个完全卷积神经网络,使用带残差连接的扩张卷积,实现了大感受野和高效参数化。它还通过两个步骤自动进行实验偏差校正,首先通过学习简单的染色质背景模型来捕捉酶的影响(图中称为冻结偏差模型)。然后我们使用这个模型从ATAC-seq/DNASE-seq谱图中回归掉酶的影响。这个两步过程确保了ChromBPNet模型的序列组件(称为TF模型)不会学习酶偏差。
目录
安装
本节将讨论训练ChromBPNet模型所需的包。首先,建议您使用GPU进行模型训练,并已安装必要的NVIDIA驱动程序和CUDA。您可以通过执行nvidia-smi命令并确保命令返回系统GPU信息(而不是错误)来验证机器是否正确设置为使用GPU。其次,有两种方法可以确保您拥有训练ChromBPNet模型所需的包,我们在下面详细说明,
1. 在docker中运行
下载并安装适用于您平台的最新版本Docker。这里是安装程序的链接 -Docker安装程序。运行下面的docker run命令打开一个已安装所有包的环境,然后执行cd chrombpnet开始运行教程。
注意: 要从docker容器中访问系统GPU,您必须在主机上安装NVIDIA Container Toolkit。
docker run -it --rm --memory=100g --gpus device=0 kundajelab/chrombpnet:latest
2. 本地安装
创建一个干净的conda环境,python版本>=3.8
conda create -n chrombpnet python=3.8
conda activate chrombpnet
通过conda安装非Python要求
conda install -y -c conda-forge -c bioconda samtools bedtools ucsc-bedgraphtobigwig pybigwig meme
从pypi安装
pip install chrombpnet
从源代码安装
git clone https://github.com/kundajelab/chrombpnet.git
pip install -e chrombpnet
快速入门
偏差因子化ChromBPNet训练
使用预训练偏差模型训练ChromBPNet的命令如下:
chrombpnet pipeline \
-ibam /path/to/input.bam \ # 只接受ibam、ifrag或itag中的一个
-ifrag /path/to/input.tsv \ # 只接受ibam、ifrag或itag中的一个
-itag /path/to/input.tagAlign \ # 只接受ibam、ifrag或itag中的一个
-d "ATAC" \
-g /path/to/hg38.fa \
-c /path/to/hg38.chrom.sizes \
-p /path/to/peaks.bed \
-n /path/to/nonpeaks.bed \
-fl /path/to/fold_0.json \
-b /path/to/bias.h5 \
-o path/to/output/dir/ \
输入格式
-ibam或-ifrag或-itag: 以bam、fragment或tagalign格式之一包含过滤reads的输入文件路径。支持类型的示例文件 - bam、fragment、tagalign-d: 实验类型。支持以下类型 - "ATAC"或"DNASE"-g: 参考基因组fasta文件。人类参考的示例文件 - hg38.fa-c: 染色体和大小制表符分隔文件。人类参考的示例文件 - hg38.chrom.sizes-p: narrowPeak文件格式的输入峰,必须有10列,至少包含chr、start、end和summit(第10列)的值。在所有区域中,每个区域内部都以start + summit为中心。ENCSR868FGK数据集的示例文件 - peaks.bed-n: narrowPeak文件格式的输入非峰(背景区域),必须有10列,至少包含chr、start、end和summit(第10列)的值。在所有区域中,每个区域内部都以start + summit为中心。ENCSR868FGK数据集的示例文件 - nonpeaks.bed。有关如何制作自己的非峰文件的更多说明,请参见预处理指南。-fl: 显示训练、测试和验证的染色体分割的json文件。人类参考的5折json示例 - folds-b:.h5格式的偏差模型。偏差模型通常可在遵循相似协议的实验类型之间转移。可供使用的预训练偏差模型库在此。训练自定义偏差模型的说明见下文。-o: 输出目录路径
请在此处找到预处理的脚本和最佳实践。
输出格式
输出目录将按如下方式填充 -
models\
bias_model_scaled.h5
chrombpnet.h5
chrombpnet_nobias.h5 (TF模型,即预测偏差校正后可及性谱图的模型)
logs\
chrombpnet.log (每个epoch的损失)
chrombpnet.log.batch (每个epoch每个batch的损失)
(..训练中使用的其他超参数)
auxilary\
filtered.peaks
filtered.nonpeaks
...
evaluation\
overall_report.pdf
overall_report.html
bw_shift_qc.png
bias_metrics.json
chrombpnet_metrics.json
chrombpnet_only_peaks.counts_pearsonr.png
chrombpnet_only_peaks.profile_jsd.png
chrombpnet_nobias_profile_motifs.pdf
chrombpnet_nobias_counts_motifs.pdf
chrombpnet_nobias_max_bias_response.txt
chrombpnet_nobias.....footprint.png
...
提供了有关输入参数的更多信息以及输出文件格式及其使用方法的详细使用指南在此和在此。
更多信息,另请参见:
偏差模型训练
训练自定义偏差模型的命令如下:
chrombpnet bias pipeline \
-ibam /path/to/input.bam \ # 只接受ibam、ifrag或itag中的一个
-ifrag /path/to/input.tsv \ # 只接受ibam、ifrag或itag中的一个
-itag /path/to/input.tagAlign \ # 只接受ibam、ifrag或itag中的一个
-d "ATAC" \
-g /path/to/hg38.fa \
-c /path/to/hg38.chrom.sizes \
-p /path/to/peaks.bed \
-n /path/to/nonpeaks.bed \
-fl /path/to/fold_0.json \
-b 0.5 \
-o path/to/output/dir/ \
输入格式
-ibam或-ifrag或-itag:输入文件路径,包含经过过滤的读数,格式可以是bam、fragment或tagalign之一。支持的文件类型示例 - bam、fragment、tagalign-d:实验类型。支持以下类型 - "ATAC"或"DNASE"-g:参考基因组fasta文件。人类参考基因组示例文件 - hg38.fa-c:染色体和大小的制表符分隔文件。人类参考基因组示例文件 - hg38.chrom.sizes-p:以narrowPeak文件格式输入峰值,必须有10列,至少包含染色体、起始位置、结束位置和峰顶(第10列)的值。在所有区域中,每个区域内部都以起始位置加峰顶为中心。ENCSR868FGK数据集的示例文件 - peaks.bed-n:以narrowPeak文件格式输入非峰值(背景区域),必须有10列,至少包含染色体、起始位置、结束位置和峰顶(第10列)的值。在所有区域中,每个区域内部都以起始位置加峰顶为中心。ENCSR868FGK数据集的示例文件 - nonpeaks.bed-f:显示训练集、测试集和验证集染色体划分的json文件。人类参考基因组的5折json示例 - folds-o:输出目录路径
预处理的脚本和最佳实践请参见此处。
输出格式
输出目录结构如下:
models\
bias.h5
logs\
bias.log(每个epoch的损失)
bias.log.batch(每个epoch每个batch的损失)
(..其他用于训练的超参数)
intermediates\
...
evaluation\
overall_report.html
overall_report.pdf
pwm_from_input.png
k562_epoch_loss.png
bias_metrics.json
bias_only_peaks.counts_pearsonr.png
bias_only_peaks.profile_jsd.png
bias_only_nonpeaks.counts_pearsonr.png
bias_only_nonpeaks.profile_jsd.png
bias_predictions.h5
bias_profile.pdf
bias_counts.pdf
...
关于输入参数和输出文件格式的详细使用指南以及如何使用它们的更多信息,请参见此处和此处。
更多信息,另请参见:
如何引用
如果您的投稿不允许使用GitHub引用,请联系Anusri Pampari和Anshul Kundaje。 如果您在工作中使用了ChromBPNet,请按以下格式引用:
@software{Pampari_Bias_factorized_base-resolution_2023,
author = {Pampari, Anusri and Shcherbina, Anna and Nair, Surag and Schreiber, Jacob and Patel, Aman and Wang, Austin and Kundu, Soumya and Shrikumar, Avanti and Kundaje, Anshul},
doi = {10.5281/zenodo.7567627},
month = {1},
title = {{Bias factorized, base-resolution deep learning models of chromatin accessibility reveal cis-regulatory sequence syntax, transcription factor footprints and regulatory variants.}},
url = {https://github.com/kundajelab/chrombpnet},
version = {0.1.1},
year = {2023}
}











