
 访问官网
访问官网 Github
Github Huggingface
Huggingface 论文
论文FACodec:用于NaturalSpeech 3的具有属性因子化的语音编解码器

项目来源
本项目完全移植自 Amphion/models/codec/ns3_codec
安装
git clone https://github.com/lifeiteng/naturalspeech3_facodec.git
cd naturalspeech3_facodec
pip3 install torch==2.1.2 torchaudio==2.1.2
pip3 install .
# pip3 install -e . # 开发模式
# export HF_ENDPOINT=https://hf-mirror.com
python test.py # 写入 audio/1_recon.wav audio/1_to_2_vc.wav
概述
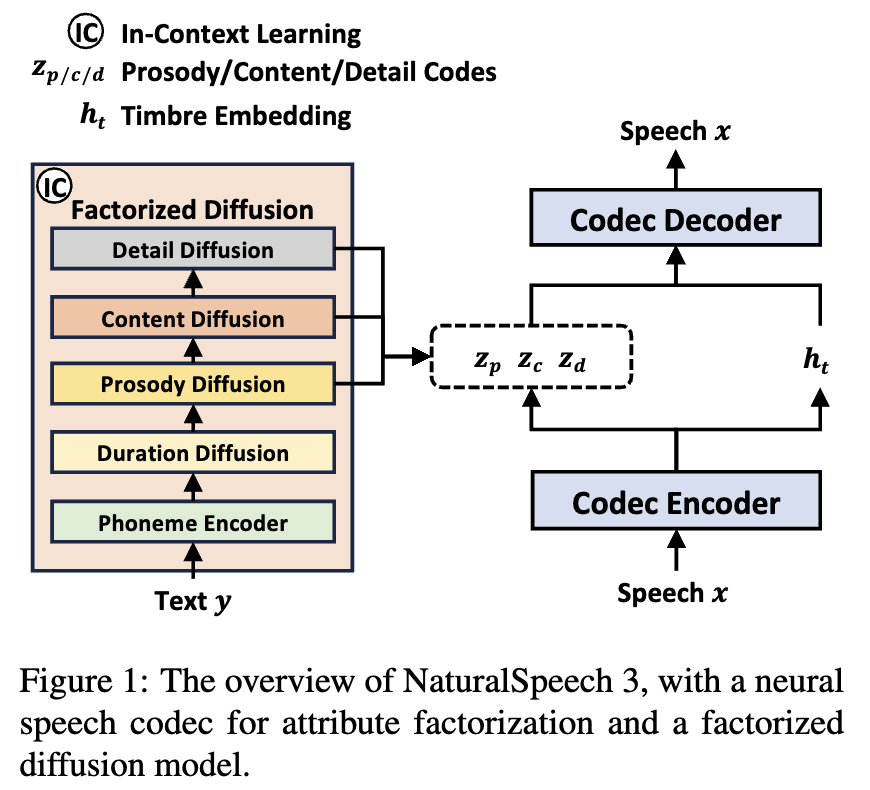
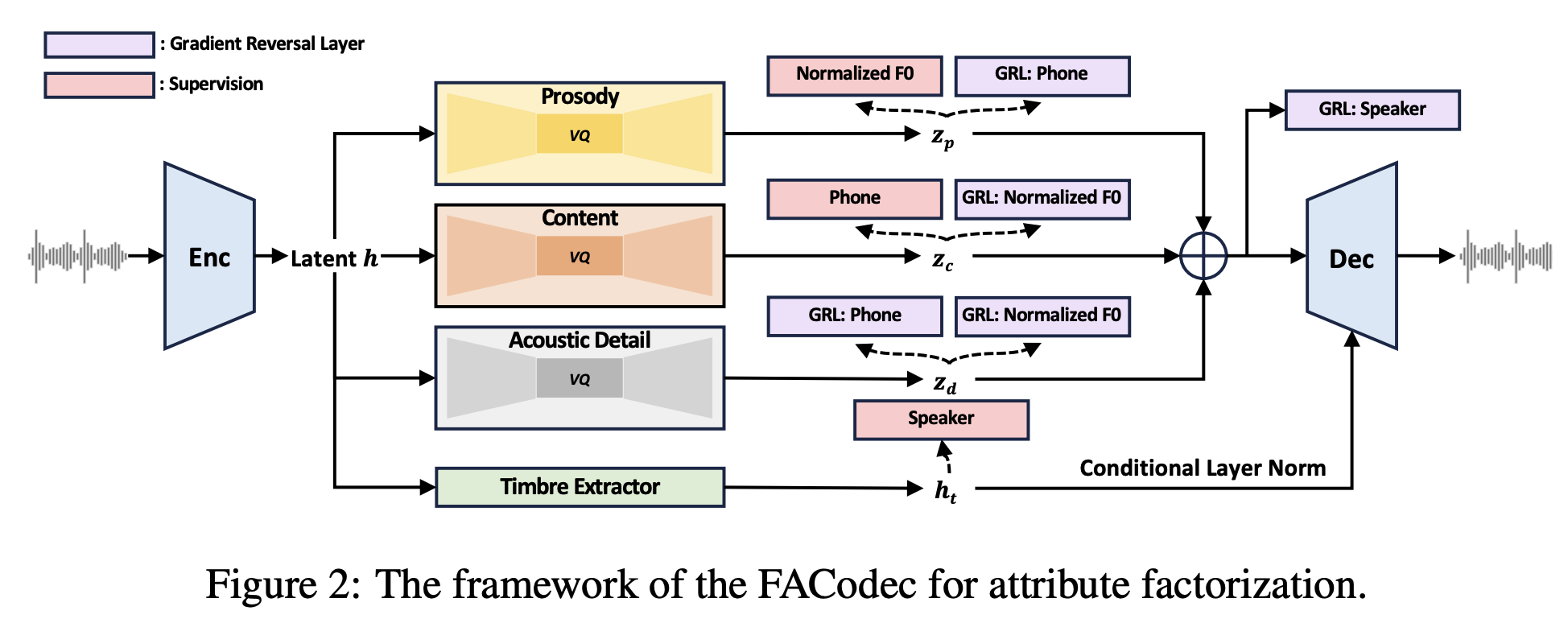
FACodec是高级文本到语音(TTS)模型NaturalSpeech 3的核心组件。FACodec将复杂的语音波形转换为表示内容、韵律、音色和声学细节等语音属性的解耦子空间,并从这些属性重建高质量的语音波形。FACodec将复杂的语音分解为表示不同属性的子空间,从而简化了语音表示的建模。
研究人员可以使用FACodec开发不同模式的TTS模型,如基于非自回归离散扩散的模型(NaturalSpeech 3)或自回归模型(如VALL-E)。
使用方法
从HuggingFace下载预训练的FACodec模型:预训练FACodec检查点
安装Amphion
git clone https://github.com/open-mmlab/Amphion.git
使用预训练FACodec模型的几行代码
from ns3_codec import FACodecEncoder, FACodecDecoder
from huggingface_hub import hf_hub_download
fa_encoder = FACodecEncoder(
ngf=32,
up_ratios=[2, 4, 5, 5],
out_channels=256,
)
fa_decoder = FACodecDecoder(
in_channels=256,
upsample_initial_channel=1024,
ngf=32,
up_ratios=[5, 5, 4, 2],
vq_num_q_c=2,
vq_num_q_p=1,
vq_num_q_r=3,
vq_dim=256,
codebook_dim=8,
codebook_size_prosody=10,
codebook_size_content=10,
codebook_size_residual=10,
use_gr_x_timbre=True,
use_gr_residual_f0=True,
use_gr_residual_phone=True,
)
encoder_ckpt = hf_hub_download(repo_id="amphion/naturalspeech3_facodec", filename="ns3_facodec_encoder.bin")
decoder_ckpt = hf_hub_download(repo_id="amphion/naturalspeech3_facodec", filename="ns3_facodec_decoder.bin")
fa_encoder.load_state_dict(torch.load(encoder_ckpt))
fa_decoder.load_state_dict(torch.load(decoder_ckpt))
fa_encoder.eval()
fa_decoder.eval()
推理
import librosa
import torch
import soundfile as sf
test_wav_path = "test.wav"
test_wav = librosa.load(test_wav_path, sr=16000)[0]
test_wav = torch.from_numpy(test_wav).float()
test_wav = test_wav.unsqueeze(0).unsqueeze(0)
with torch.no_grad():
# 编码
enc_out = fa_encoder(test_wav)
print(enc_out.shape)
# 量化
vq_post_emb, vq_id, _, quantized, spk_embs = fa_decoder(enc_out, eval_vq=False, vq=True)
# 量化后的潜在表示
print(vq_post_emb.shape)
# 编码
print("vq id 形状:", vq_id.shape)
# 获取韵律编码
prosody_code = vq_id[:1]
print("韵律编码形状:", prosody_code.shape)
# 获取内容编码
cotent_code = vq_id[1:3]
print("内容编码形状:", cotent_code.shape)
# 获取残差编码(声学细节编码)
residual_code = vq_id[3:]
print("残差编码形状:", residual_code.shape)
# 说话人嵌入
print("说话人嵌入形状:", spk_embs.shape)
# 解码(推荐)
recon_wav = fa_decoder.inference(vq_post_emb, spk_embs)
print(recon_wav.shape)
sf.write("recon.wav", recon_wav[0][0].cpu().numpy(), 16000)
FACodec可以通过FACodecEncoderV2/FACodecDecoderV2或FACodecRedecoder实现零样本声音转换
import librosa
import torch
import soundfile as sf
from ns3_codec import FACodecEncoderV2, FACodecDecoderV2
# 与FACodecEncoder/FACodecDecoder相同的参数
# fa_encoder_v2 = FACodecEncoderV2(...)
# fa_decoder_v2 = FACodecDecoderV2(...)
fa_encoder_v2 = FACodecEncoderV2(
ngf=32,
up_ratios=[2, 4, 5, 5],
out_channels=256,
)
fa_decoder_v2 = FACodecDecoderV2(
in_channels=256,
upsample_initial_channel=1024,
ngf=32,
up_ratios=[5, 5, 4, 2],
vq_num_q_c=2,
vq_num_q_p=1,
vq_num_q_r=3,
vq_dim=256,
codebook_dim=8,
codebook_size_prosody=10,
codebook_size_content=10,
codebook_size_residual=10,
use_gr_x_timbre=True,
use_gr_residual_f0=True,
use_gr_residual_phone=True,
)
encoder_v2_ckpt = hf_hub_download(repo_id="amphion/naturalspeech3_facodec", filename="ns3_facodec_encoder_v2.bin")
decoder_v2_ckpt = hf_hub_download(repo_id="amphion/naturalspeech3_facodec", filename="ns3_facodec_decoder_v2.bin")
fa_encoder_v2.load_state_dict(torch.load(encoder_v2_ckpt))
fa_decoder_v2.load_state_dict(torch.load(decoder_v2_ckpt))
def load_audio(wav_path):
wav = librosa.load(wav_path, sr=16000)[0]
wav = torch.from_numpy(wav).float()
wav = wav.unsqueeze(0).unsqueeze(0)
return wav
使用torch.no_grad():
wav_a = load_audio("/Users/feiteng/speech/ns3_codec/audio/1.wav")
wav_b = load_audio("/Users/feiteng/speech/ns3_codec/audio/2.wav")
enc_out_a = fa_encoder_v2(wav_a)
prosody_a = fa_encoder_v2.get_prosody_feature(wav_a)
enc_out_b = fa_encoder_v2(wav_b)
prosody_b = fa_encoder_v2.get_prosody_feature(wav_b)
vq_post_emb_a, vq_id_a, _, quantized, spk_embs_a = fa_decoder_v2(
enc_out_a, prosody_a, eval_vq=False, vq=True
)
vq_post_emb_b, vq_id_b, _, quantized, spk_embs_b = fa_decoder_v2(
enc_out_b, prosody_b, eval_vq=False, vq=True
)
vq_post_emb_a_to_b = fa_decoder_v2.vq2emb(vq_id_a, use_residual=False)
recon_wav_a_to_b = fa_decoder_v2.inference(vq_post_emb_a_to_b, spk_embs_b)
或者
from ns3_codec import FACodecRedecoder
fa_redecoder = FACodecRedecoder()
redecoder_ckpt = hf_hub_download(repo_id="amphion/naturalspeech3_facodec", filename="ns3_facodec_redecoder.bin")
fa_redecoder.load_state_dict(torch.load(redecoder_ckpt))
使用torch.no_grad():
enc_out_a = fa_encoder(wav_a)
enc_out_b = fa_encoder(wav_b)
vq_post_emb_a, vq_id_a, _, quantized_a, spk_embs_a = fa_decoder(enc_out_a, eval_vq=False, vq=True)
vq_post_emb_b, vq_id_b, _, quantized_b, spk_embs_b = fa_decoder(enc_out_b, eval_vq=False, vq=True)
# 转换说话人
vq_post_emb_a_to_b = fa_redecoder.vq2emb(vq_id_a, spk_embs_b, use_residual=False)
recon_wav_a_to_b = fa_redecoder.inference(vq_post_emb_a_to_b, spk_embs_b)
sf.write("recon_a_to_b.wav", recon_wav_a_to_b[0][0].cpu().numpy(), 16000)
问答
问题1:FACodec支持的音频采样率是多少?跳跃大小是多少?每帧会生成多少个编码?
回答1:FACodec支持16KHz的语音音频。跳跃大小为200个样本,每帧将生成(16000/200) * 6(码本总数)个编码。
问题2:是否可以使用FACodec训练像VALL-E这样的自回归TTS模型?
回答2:是的。事实上,NaturalSpeech 3的作者已经探索了使用FACodec进行离散token生成的自回归生成模型。他们使用自回归语言模型生成韵律码,然后使用非自回归模型生成剩余的内容和声学细节码。
问题3:是否可以使用FACodec训练像NaturalSpeech2这样的潜在扩散TTS模型?
回答3:是的。你可以使用量化后得到的潜在表示作为潜在扩散模型的建模目标。
问题4:FACodec能否压缩和重构其他领域的音频?比如音效、音乐等。
回答4:由于FACodec是为语音设计的,它可能不适合其他音频领域。然而,可以使用FACodec模型来压缩和重构其他领域的音频,但质量可能不如原始音频。
问题5:FACodec能否用作其他任务(如声音转换)的内容特征?
回答5:我认为答案是肯定的。研究人员可以使用FACodec的内容码作为声音转换的内容特征。我们希望看到这个方向上的更多研究。
引用
如果你使用我们的FACodec模型,请引用以下论文:
@article{ju2024naturalspeech,
title={NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models},
author={Ju, Zeqian and Wang, Yuancheng and Shen, Kai and Tan, Xu and Xin, Detai and Yang, Dongchao and Liu, Yanqing and Leng, Yichong and Song, Kaitao and Tang, Siliang and others},
journal={arXiv preprint arXiv:2403.03100},
year={2024}
}
@article{zhang2023amphion,
title={Amphion: An Open-Source Audio, Music and Speech Generation Toolkit},
author={Xueyao Zhang and Liumeng Xue and Yicheng Gu and Yuancheng Wang and Haorui He and Chaoren Wang and Xi Chen and Zihao Fang and Haopeng Chen and Junan Zhang and Tze Ying Tang and Lexiao Zou and Mingxuan Wang and Jun Han and Kai Chen and Haizhou Li and Zhizheng Wu},
journal={arXiv},
year={2024},
volume={abs/2312.09911}
}











