
 访问官网
访问官网 Github
Github 论文
论文通过权重和激活值修剪大语言模型
Wanda(Weights and activations修剪法)的官方PyTorch实现,如我们的论文所述:
一种简单而有效的大语言模型修剪方法
Mingjie Sun*, Zhuang Liu*, Anna Bair, J. Zico Kolter (* 表示贡献相同)
卡内基梅隆大学, Meta AI研究院和博世人工智能中心
论文 - 项目主页
@article{sun2023wanda,
title={A Simple and Effective Pruning Approach for Large Language Models},
author={Sun, Mingjie and Liu, Zhuang and Bair, Anna and Kolter, J. Zico},
year={2023},
journal={arXiv preprint arXiv:2306.11695}
}
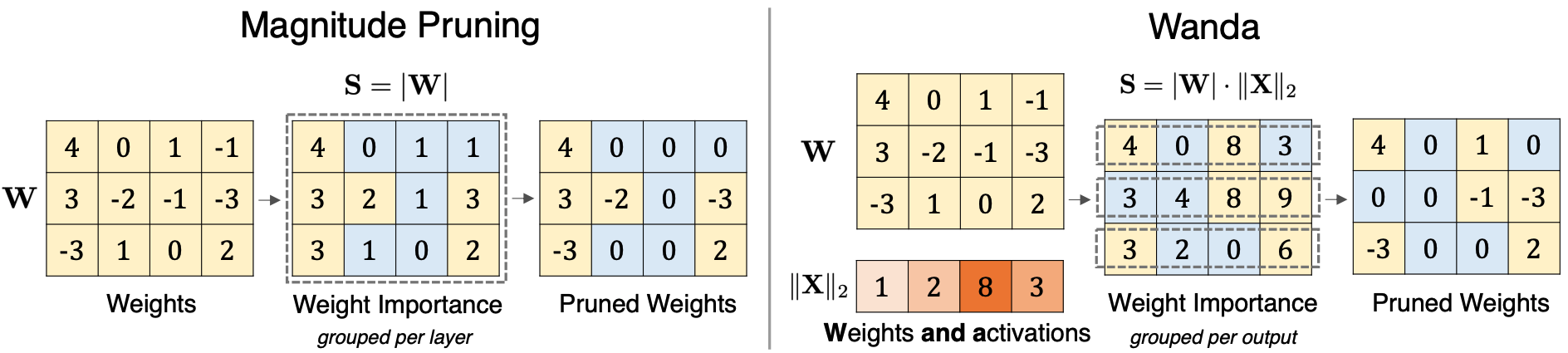
与仅基于权重大小进行修剪的方法相比,我们的修剪方法Wanda通过权重大小和输入激活范数的乘积,在每个输出基础上移除权重。
更新
- (2023.9.22) 增加对LLaMA-2的支持。
- (2023.9.22) 增加代码以复现论文中关于OBS权重更新的消融研究。
- (2023.10.6) 为消融研究中的权重更新分析添加新的支持。欢迎试用!
- (2023.10.6) 增加对零样本评估的支持。
- (2023.10.20) 增加修剪OPT模型的代码。
- (2023.10.23) 增加LoRA微调的代码。
设置
安装说明可以在INSTALL.md中找到。
使用方法
scripts目录包含了所有用于复现论文主要结果(表2)的bash命令。
以下是使用Wanda修剪LLaMA-7B以实现非结构化50%稀疏度的示例命令:
python main.py \
--model decapoda-research/llama-7b-hf \
--prune_method wanda \
--sparsity_ratio 0.5 \
--sparsity_type unstructured \
--save out/llama_7b/unstructured/wanda/
以下是参数的简要概述:
--model: Hugging Face模型库中LLaMA模型的标识符。--cache_dir: 加载或存储LLM权重的目录。默认为llm_weights。--prune_method: 我们实现了三种修剪方法,即[magnitude,wanda,sparsegpt]。--sparsity_ratio: 表示要修剪的权重百分比。--sparsity_type: 指定稀疏度类型[unstructured,2:4,4:8]。--use_variant: 是否使用Wanda变体,默认为False。--save: 指定结果存储的目录。
对于结构化N:M稀疏度,将参数--sparsity_type设置为"2:4"或"4:8"。以下是一个示例命令:
python main.py \
--model decapoda-research/llama-7b-hf \
--prune_method wanda \
--sparsity_ratio 0.5 \
--sparsity_type 2:4 \
--save out/llama_7b/2-4/wanda/
修剪LLaMA-2
对于LLaMA-2模型,将--model替换为meta-llama/Llama-2-7b-hf(以7b为例):
python main.py \
--model meta-llama/Llama-2-7b-hf \
--prune_method wanda \
--sparsity_ratio 0.5 \
--sparsity_type unstructured \
--save out/llama2_7b/unstructured/wanda/
LLaMA-2结果:(截至2023.9.22,LLaMA-2-34b尚未发布)
| 稀疏度 | ppl | llama2-7b | llama2-13b | llama2-70b |
|---|---|---|---|---|
| - | 密集 | 5.12 | 4.57 | 3.12 |
| 非结构化50% | magnitude | 14.89 | 6.37 | 4.98 |
| 非结构化50% | sparsegpt | 6.51 | 5.63 | 3.98 |
| 非结构化50% | wanda | 6.42 | 5.56 | 3.98 |
| 4:8 | magnitude | 16.48 | 6.76 | 5.58 |
| 4:8 | sparsegpt | 8.12 | 6.60 | 4.59 |
| 4:8 | wanda | 7.97 | 6.55 | 4.47 |
| 2:4 | magnitude | 54.59 | 8.33 | 6.33 |
| 2:4 | sparsegpt | 10.17 | 8.32 | 5.40 |
| 2:4 | wanda | 11.02 | 8.27 | 5.16 |
OBS权重更新消融实验
为重现权重更新分析,我们提供了此消融实验的实现。所有命令可在此脚本中找到。
for method in ablate_mag_seq ablate_wanda_seq ablate_mag_iter ablate_wanda_iter
do
CUDA_VISIBLE_DEVICES=0 python main.py \
--model decapoda-research/llama-7b-hf \
--sparsity_ratio 0.5 \
--sparsity_type unstructured \
--prune_method ${method} \
--save out/llama_7b_ablation/unstructured/
done
这里ablate_{mag/wanda}_{seq/iter}表示我们使用幅度剪枝或wanda在每一层获取剪枝掩码,然后以顺序或迭代方式每128个输入通道应用一次权重更新程序。详情请参阅我们论文的第5节。
零样本评估
为评估零样本任务,我们修改了EleutherAI LM Harness框架,使其能够评估剪枝后的LLM模型。我们在此链接提供了修改后的仓库。请确保下载、解压并从源代码安装此自定义lm_eval包。
为保证可重现性,我们使用了主分支上的commit df3da98。除BoolQ任务版本为1外,所有任务均使用版本0进行评估。
总的来说,我们提供的功能是在这个函数中添加两个参数pretrained_model和tokenizer。然后我们可以从我们的代码库调用这个simple_evaluate函数API来评估稀疏剪枝后的LLM。要评估零样本任务以及WikiText困惑度,请传入--eval_zero_shot参数。
加速评估
每种方法的剪枝速度通过累计每层剪枝所花费的时间来评估,不包括前向传播。
对于结构化稀疏性的推理加速,我们建议读者参考这篇博客文章,其中PyTorch >= 2.1支持结构化稀疏性。你可以在这里切换CUTLASS或CuSPARSELt内核。
最后,关于剪枝图像分类器,请参见image_classifiers目录了解详情。
致谢
本仓库基于SparseGPT仓库构建。
许可
本项目在MIT许可下发布。更多信息请参见LICENSE文件。
问题
欢迎通过issues/邮件与我们讨论论文/代码!
mingjies at cs.cmu.edu
liuzhuangthu at gmail.com











