
 访问官网
访问官网 Github
Github Huggingface
Huggingface 文档
文档 论文
论文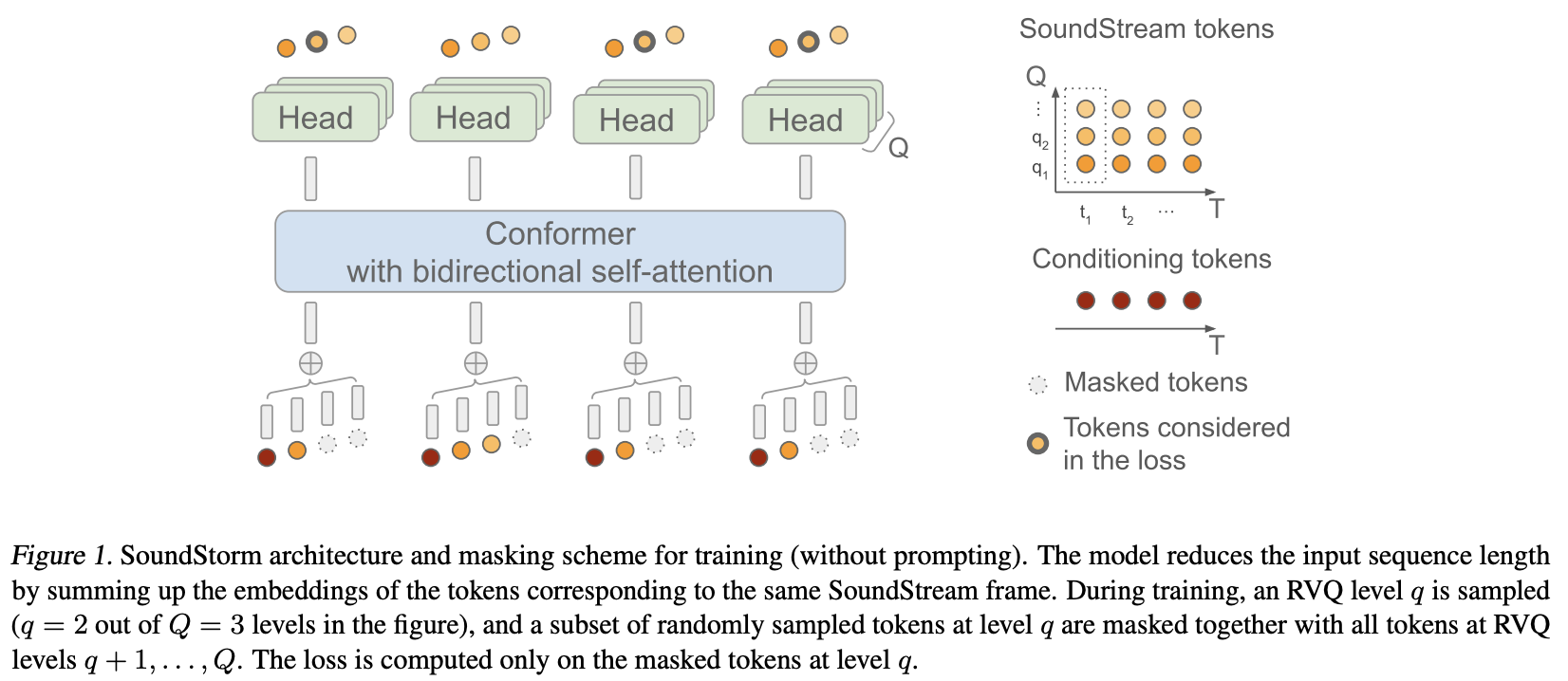
Soundstorm - Pytorch
Google Deepmind提出的SoundStorm高效并行音频生成的Pytorch实现。
他们基本上将MaskGiT应用于Soundstream的残差向量量化编码。他们选择使用的transformer架构是一个非常适合音频领域的架构,名为Conformer。
致谢
-
感谢Stability和🤗 Huggingface慷慨赞助,支持开发和开源前沿人工智能研究
-
感谢Lucas Newman的诸多贡献,包括初始训练代码、声学提示逻辑和每级量化器解码!
-
感谢🤗 Accelerate提供简单而强大的训练解决方案
-
感谢Einops提供不可或缺的抽象,使构建神经网络变得有趣、简单和令人振奋
-
感谢Steven Hillis提交正确的掩蔽策略并验证仓库可用!🙏
-
感谢Lucas Newman基本上用多个仓库的模型训练了一个小型可用的Soundstorm,展示了端到端的工作流程。使用的模型包括SoundStream、Text-to-Semantic T5,以及这里的SoundStorm transformer。
-
感谢@Jiang-Stan发现了迭代去掩蔽中的一个关键bug!
安装
$ pip install soundstorm-pytorch
使用方法
import torch
from soundstorm_pytorch import SoundStorm, ConformerWrapper
conformer = ConformerWrapper(
codebook_size = 1024,
num_quantizers = 12,
conformer = dict(
dim = 512,
depth = 2
),
)
model = SoundStorm(
conformer,
steps = 18, # 18步,与原始maskgit论文一致
schedule = 'cosine' # 目前最佳的调度是余弦调度
)
# 从大量原始音频中获取预编码的codebook ids
codes = torch.randint(0, 1024, (2, 1024, 12)) # (批次, 序列, 残差VQ数量)
# 对大量数据循环执行以下操作
loss, _ = model(codes)
loss.backward()
# 模型现在可以在18步内生成。~2秒听起来合理
generated = model.generate(1024, batch_size = 2) # (2, 1024)
要直接在原始音频上训练,你需要将预训练的SoundStream传入SoundStorm。你可以在audiolm-pytorch训练自己的SoundStream。
import torch
from soundstorm_pytorch import SoundStorm, ConformerWrapper, Conformer, SoundStream
conformer = ConformerWrapper(
codebook_size = 1024,
num_quantizers = 12,
conformer = dict(
dim = 512,
depth = 2
),
)
soundstream = SoundStream(
codebook_size = 1024,
rq_num_quantizers = 12,
attn_window_size = 128,
attn_depth = 2
)
model = SoundStorm(
conformer,
soundstream = soundstream # 传入soundstream
)
# 找到你希望模型学习的尽可能多的音频
audio = torch.randn(2, 10080)
# 将其通过模型并进行大量tiny步骤
loss, _ = model(audio)
loss.backward()
# 现在你可以生成最先进的语音了
generated_audio = model.generate(seconds = 30, batch_size = 2) # 生成30秒的音频(它会根据传入的soundstream的采样频率和累积下采样来计算秒数对应的长度)
完整的文本到语音将依赖于训练好的TextToSemantic编码器/解码器transformer。你需要加载权重并将其作为spear_tts_text_to_semantic传入SoundStorm。
这是一项进行中的工作,因为spear-tts-pytorch目前只完成了模型架构,还没有预训练+伪标签+反向翻译逻辑。
from spear_tts_pytorch import TextToSemantic
text_to_semantic = TextToSemantic(
dim = 512,
source_depth = 12,
target_depth = 12,
num_text_token_ids = 50000,
num_semantic_token_ids = 20000,
use_openai_tokenizer = True
)
# 加载训练好的text-to-semantic transformer
text_to_semantic.load('/path/to/trained/model.pt')
# 将其传入soundstorm
model = SoundStorm(
conformer,
soundstream = soundstream,
spear_tts_text_to_semantic = text_to_semantic
).cuda()
# 现在你可以生成最先进的语音了
generated_speech = model.generate(
texts = [
'the rain in spain stays mainly in the plain',
'the quick brown fox jumps over the lazy dog'
]
) # (2, n) - 从soundstream解码的原始波形
待办事项
-
集成 soundstream
-
生成时,长度可以以秒为单位定义(考虑采样频率等因素)
-
确保支持分组 RVQ。在组维度上连接嵌入而非求和
-
直接复制 conformer 并用旋转位置嵌入重做 Shaw 的相对位置嵌入。现在没人再用 Shaw 的方法了
-
默认启用 flash attention
-
移除批量归一化,只使用层归一化,但放在 swish 激活函数之后(如 normformer 论文所述)
-
使用 accelerate 的训练器 - 感谢 @lucasnewman
-
通过在
forward和generate时传入mask来允许可变长度序列的训练和生成 -
生成时选择返回音频文件列表
-
将其转换为命令行工具
-
添加交叉注意力和自适应层归一化条件
引用
[此处省略引用部分的翻译,保留原文]











